













TurboAttention:基于多項式近似和漸進式量化的高效注意力機制優(yōu)化方案,降低LLM計算成本70%
隨著大型語言模型(LLMs)在AI應(yīng)用領(lǐng)域持續(xù)發(fā)展,其計算成本也呈現(xiàn)顯著上升趨勢。數(shù)據(jù)分析表明,GPT-4的運行成本約為700美元/小時,2023年各企業(yè)在LLM推理方面的總支出超過50億美元。這一挑戰(zhàn)的核心在于注意力機制——該機制作為模型處理和關(guān)聯(lián)信息的計算核心,同時也構(gòu)成了主要的性能瓶頸。
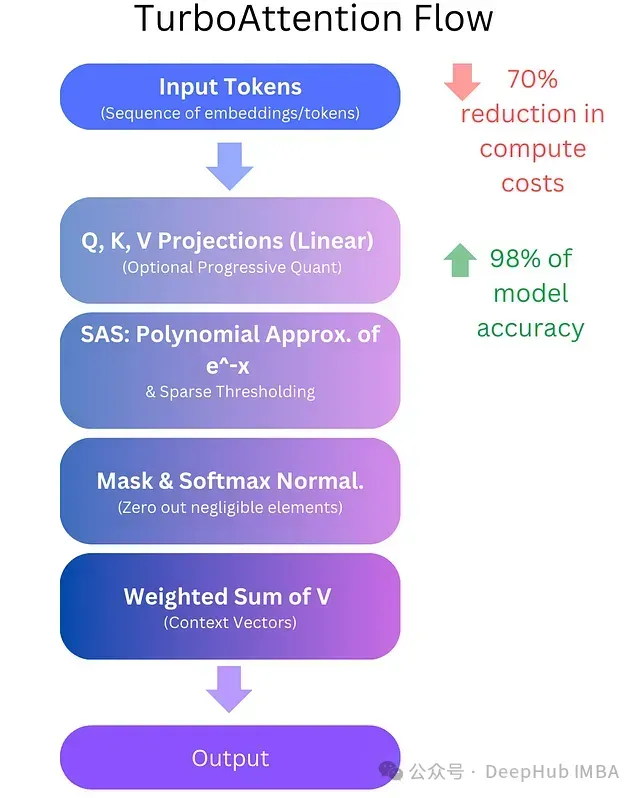
TurboAttention提出了一種全新的LLM信息處理方法。該方法通過一系列優(yōu)化手段替代了傳統(tǒng)的二次復(fù)雜度注意力機制,包括稀疏多項式軟最大值近似和高效量化技術(shù)。初步實現(xiàn)結(jié)果顯示,該方法可實現(xiàn)70%的計算成本降低,同時保持98%的模型精度。
對于規(guī)模部署LLM的組織而言,這不僅是性能的提升,更是一項可顯著降低運營成本并優(yōu)化響應(yīng)時間的技術(shù)突破。
本文將從技術(shù)層面深入探討TurboAttention如何實現(xiàn)效率提升,分析其架構(gòu)創(chuàng)新。
1、注意力機制原理
在深入分析TurboAttention之前,首先需要理解注意力機制的基本原理,特別是其高效性與計算密集性的雙重特性。
注意力機制定義
在深度學(xué)習(xí)領(lǐng)域,注意力機制是一種使模型能夠動態(tài)關(guān)注輸入數(shù)據(jù)不同部分的技術(shù)方法。區(qū)別于對所有詞元或元素賦予相同的權(quán)重,注意力機制允許網(wǎng)絡(luò)重點關(guān)注特定詞元。這一特性在序列處理任務(wù)中尤其重要,如語言建模中句子前部分的詞對后續(xù)詞的影響。
注意力機制類型
自注意力:計算同一序列內(nèi)部的注意力得分。例如,在句子處理中,模型計算每個詞與同一句子中其他詞的關(guān)聯(lián)度,以獲取上下文關(guān)系。
交叉注意力:計算不同序列間的注意力得分,典型應(yīng)用如神經(jīng)機器翻譯系統(tǒng)中源語言與目標(biāo)語言序列間的關(guān)聯(lián)計算。
計算復(fù)雜度分析
傳統(tǒng)注意力機制需要處理尺寸為的矩陣計算,其中表示序列長度。因此計算復(fù)雜度為。對于LLM中常見的數(shù)千詞元長序列,這種復(fù)雜度rapidly構(gòu)成性能瓶頸。
高效注意力機制的必要性
隨著模型規(guī)模從百萬擴展到十億甚至萬億參數(shù),注意力機制的計算瓶頸日益凸顯,這嚴(yán)重制約了實時處理能力并導(dǎo)致計算成本攀升。TurboAttention通過整合多項優(yōu)化策略解決這一問題,包括稀疏化處理、多項式軟最大值近似和分級量化方案。
2、TurboAttention技術(shù)架構(gòu)
TurboAttention提供了一種在大規(guī)模Transformer模型中實現(xiàn)注意力機制近似的技術(shù)方案,在計算效率和模型性能之間達到平衡。其核心創(chuàng)新點包括兩個方面:注意力權(quán)重的計算優(yōu)化(采用多項式近似和稀疏閾值處理)以及相關(guān)數(shù)據(jù)(查詢、鍵和值矩陣)的存儲優(yōu)化(采用漸進式量化方案)。
核心技術(shù)組件
- 稀疏注意力計算:通過識別并僅保留關(guān)鍵詞元對的方式,大幅降低注意力計算量。
- 低秩矩陣分解:在可行情況下將高維注意力矩陣分解為低維表示,以減少矩陣乘法運算。
- 核函數(shù)優(yōu)化:采用核函數(shù)方法,提供比傳統(tǒng)矩陣乘法更高效的注意力分布估計。
- 多項式軟最大值近似(SAS):使用多項式函數(shù)近似軟最大值中的指數(shù)運算,降低計算開銷。
- 漸進式量化(PQ):實現(xiàn)多級量化策略(從INT8到INT4,某些情況下可降至INT2),優(yōu)化帶寬和內(nèi)存使用。
數(shù)學(xué)基礎(chǔ)
傳統(tǒng)注意力運算的數(shù)學(xué)表達式為:

其中(查詢矩陣)、(鍵矩陣)和(值矩陣)由輸入數(shù)據(jù)生成,表示鍵向量維度。雖然保證了注意力權(quán)重和為1,但指數(shù)運算帶來了顯著的計算開銷。TurboAttention通過引入稀疏計算(僅計算必要的注意力分?jǐn)?shù))和高效指數(shù)近似來優(yōu)化這一過程。
以高精度(FP16/FP32)存儲和傳輸和矩陣會占用大量內(nèi)存。漸進式量化通過將這些矩陣轉(zhuǎn)換為低位整數(shù)表示來解決此問題,有效降低內(nèi)存和計算開銷。
SAS:稀疏激活軟最大值技術(shù)
Transformer模型中注意力機制的一個關(guān)鍵性能瓶頸是軟最大值函數(shù)。傳統(tǒng)軟最大值計算需要執(zhí)行指數(shù)運算和除法運算,這在處理大規(guī)模矩陣時會產(chǎn)生顯著的浮點運算開銷。
多項式近似軟最大值
SAS(稀疏激活軟最大值)技術(shù)證明了在實際應(yīng)用范圍內(nèi)可以使用低次多項式進行有效近似。具體定義如下:
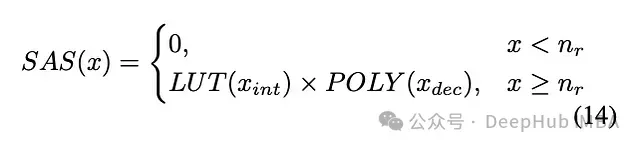
該公式將計算分為整數(shù)部分和小數(shù)部分(和),對其中一部分使用查找表(LUT),另一部分使用多項式()計算。
典型的三次多項式擬合(通過最小二乘法求解)形式如下:

通過將多項式次數(shù)限制在2或3并將取值范圍控制在內(nèi),SAS方法相比浮點指數(shù)運算實現(xiàn)了顯著的性能提升。
在GPU張量核心等硬件上,這些多項式運算可以通過FP16友好的方式執(zhí)行,進一步提高計算吞吐量。
軟最大值后稀疏化處理
較大的"主導(dǎo)"注意力分?jǐn)?shù)往往會掩蓋較小的分?jǐn)?shù)。在應(yīng)用多項式指數(shù)近似后,SAS可將低于閾值的分?jǐn)?shù)置零,實現(xiàn)僅關(guān)注最相關(guān)詞元交互的目標(biāo)。這種方法生成稀疏結(jié)果,從而降低內(nèi)存和計算開銷。
漸進式量化技術(shù)(PQ)
SAS技術(shù)解決了軟最大值的計算效率問題,而量化技術(shù)則針對大規(guī)模模型的內(nèi)存帶寬約束提供解決方案。傳統(tǒng)整數(shù)量化方法已在權(quán)重和激活值處理中證明其有效性,但在應(yīng)用注意力機制時,大多數(shù)方法仍需要對查詢(Q)、鍵(K)和值(V)矩陣進行部分反量化操作。

漸進式量化(PQ)技術(shù)源自近期研究工作(如Lin等人2024年提出的Qserve),采用兩級處理方案:
第一級:對稱INT8量化
將原始FP16或FP32數(shù)值映射至零點為的INT8區(qū)間,以避免矩陣乘法中的額外計算開銷。該階段同時保存比例因子(浮點值)和量化后的整數(shù)數(shù)據(jù)。
第二級:非對稱INT4量化
將INT8表示進一步壓縮至INT4精度,需要引入零點。雖然非對稱量化在乘法運算中引入了額外項,但由于大部分?jǐn)?shù)據(jù)以壓縮格式處理,僅在必要時進行部分展開,因此總體開銷得到有效控制。
漸進式量化的數(shù)學(xué)表達式為:
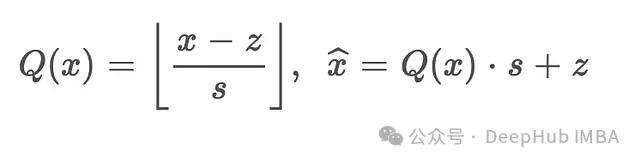
其中和在INT8和INT4階段可采用不同值。最終的整數(shù)推理計算公式(基于snippet中的等式7和8推導(dǎo))為:

其中和表示部分解壓但仍保持低位表示的數(shù)據(jù)。這一系列操作確保了浮點運算開銷最小化,同時實現(xiàn)顯著的內(nèi)存節(jié)省。
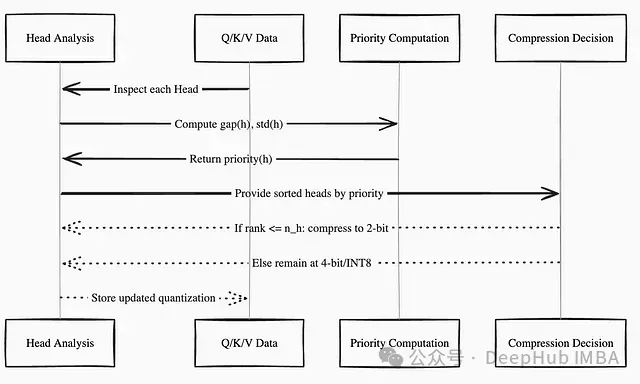
注意力頭優(yōu)先級差異化處理
量化過程中的一個重要發(fā)現(xiàn)是,不同注意力頭對精度損失的敏感度存在顯著差異。來自Phi3-mini和LLaMA3-8B模型的實驗觀察表明,查詢和鍵矩陣中某些注意力頭的通道具有較大幅值,過度壓縮這些頭會導(dǎo)致模型性能下降。
為解決這一問題,TurboAttention引入了注意力頭優(yōu)先級計算機制:
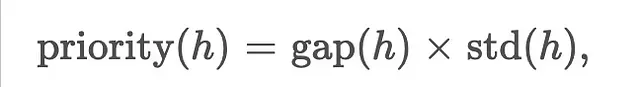
其中表示頭中通道的最大值與最小值之差,為這些差值的標(biāo)準(zhǔn)差。優(yōu)先級較高的頭對低位量化更為敏感,因此保持INT4精度,而低優(yōu)先級頭可進一步壓縮至INT2。具體實現(xiàn)為:
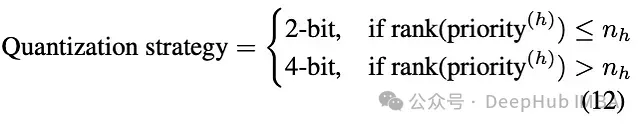
通過這種方式,少量頭(由參數(shù)定義)接受更激進的壓縮,但模型整體性能得以保持。這種精細(xì)化的量化策略相比統(tǒng)一量化方案獲得了更好的壓縮效果。
3、TurboAttention實現(xiàn)架構(gòu)
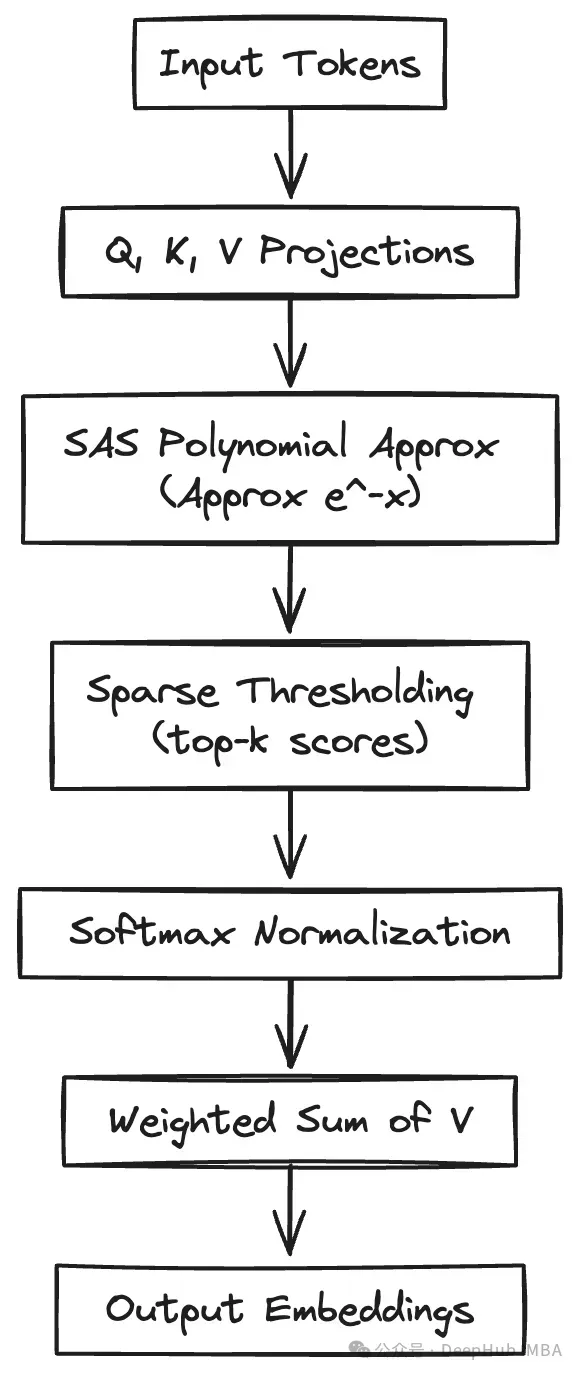
TurboAttention的實現(xiàn)涉及多個核心模塊:基于多項式的軟最大值近似模塊和Q、K、V矩陣的漸進式量化處理模塊。下面提供基于PyTorch的實現(xiàn)示例。
TurboAttention的實現(xiàn)涉及多個核心模塊:基于多項式的軟最大值近似模塊和Q、K、V矩陣的漸進式量化處理模塊。下面提供基于PyTorch的實現(xiàn)示例。
說明: 示例代碼集成了稀疏注意力、多項式指數(shù)近似和部分量化等核心思想。為保持代碼可讀性,某些實現(xiàn)細(xì)節(jié)(如多項式近似的具體實現(xiàn))進行了適當(dāng)簡化。
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class TurboAttention(nn.Module):
def __init__(self, embed_dim, num_heads, sparse_ratio=0.1):
super(TurboAttention, self).__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.sparse_ratio = sparse_ratio
self.head_dim = embed_dim // num_heads
assert (
self.head_dim * num_heads == embed_dim
), "嵌入維度必須能被注意力頭數(shù)整除"
# 定義線性投影層
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
# 定義輸出投影層
self.out_proj = nn.Linear(embed_dim, embed_dim)
# 定義e^-x近似的多項式系數(shù) (SAS)
# P(x) = a3*x^3 + a2*x^2 + a1*x + a0
self.poly_a3 = -0.1025
self.poly_a2 = 0.4626
self.poly_a1 = -0.9922
self.poly_a0 = 0.9996
def forward(self, x):
batch_size, seq_length, embed_dim = x.size()
# 第1步:執(zhí)行線性投影并可選進行量化
Q_fp = self.q_proj(x)
K_fp = self.k_proj(x)
V_fp = self.v_proj(x)
# 注:此處省略漸進式量化實現(xiàn)代碼
# 實際應(yīng)用中需要將Q、K、V量化為低位格式
# 并在需要時進行部分反量化以支持矩陣乘法
# 重排張量以支持多頭注意力計算
Q = Q_fp.view(batch_size, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
K = K_fp.view(batch_size, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
V = V_fp.view(batch_size, seq_length, self.num_heads, self.head_dim).transpose(1, 2)
# 第2步:計算縮放點積注意力
# 使用多項式近似替代標(biāo)準(zhǔn)指數(shù)函數(shù)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.head_dim)
# 將注意力分?jǐn)?shù)限制在[0, 1]范圍內(nèi)以適應(yīng)多項式計算
scores_clamped = torch.clamp(scores, 0, 1)
# 使用多項式近似計算e^-x
# softmax中根據(jù)分?jǐn)?shù)符號使用e^score或e^-score
# 此處展示e^-x的近似計算
exponent_approx = (
self.poly_a3 * scores_clamped ** 3 +
self.poly_a2 * scores_clamped ** 2 +
self.poly_a1 * scores_clamped +
self.poly_a0
)
# 第3步:實現(xiàn)top-k稀疏化
top_k = max(1, int(seq_length * self.sparse_ratio))
top_scores, _ = torch.topk(scores, top_k, dim=-1)
threshold = top_scores[:, :, :, -1].unsqueeze(-1)
mask = (scores >= threshold)
# 將多項式近似結(jié)果轉(zhuǎn)換為帶掩碼的注意力分布
exponent_approx = exponent_approx.masked_fill(~mask, float('-inf'))
# 第4步:執(zhí)行softmax歸一化
attn = F.softmax(exponent_approx, dim=-1)
# 第5步:應(yīng)用dropout進行正則化
attn = F.dropout(attn, p=0.1, training=self.training)
# 第6步:計算注意力加權(quán)和
context = torch.matmul(attn, V)
# 恢復(fù)原始張量形狀
context = context.transpose(1, 2).contiguous().view(batch_size, seq_length, embed_dim)
out = self.out_proj(context)
return outTurboAttention可通過替換標(biāo)準(zhǔn)多頭注意力模塊(如nn.MultiheadAttention)的方式集成到PyTorch Transformer架構(gòu)中:
class TransformerBlock(nn.Module):
def __init__(self, embed_dim, num_heads):
super(TransformerBlock, self).__init__()
self.attention = TurboAttention(embed_dim, num_heads)
self.layer_norm1 = nn.LayerNorm(embed_dim)
self.feed_forward = nn.Sequential(
nn.Linear(embed_dim, embed_dim * 4),
nn.ReLU(),
nn.Linear(embed_dim * 4, embed_dim)
)
self.layer_norm2 = nn.LayerNorm(embed_dim)
def forward(self, x):
# 注意力層計算
attn_out = self.attention(x)
x = self.layer_norm1(x + attn_out)
# 前饋網(wǎng)絡(luò)計算
ff_out = self.feed_forward(x)
x = self.layer_norm2(x + ff_out)
return x生產(chǎn)環(huán)境部署方案
在工程實踐中,除算法實現(xiàn)外,TurboAttention的生產(chǎn)部署還需要完善的DevOps支持。主要技術(shù)環(huán)節(jié)包括容器化管理、服務(wù)編排和分布式推理工作流設(shè)計。
容器化實現(xiàn)
采用Docker實現(xiàn)環(huán)境一致性管理: # 基礎(chǔ)鏡像選擇 FROM pytorch/pytorch:1.12.1-cuda11.3-cudnn8-runtime
# 環(huán)境變量配置
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
# 工作目錄設(shè)置
WORKDIR /app
# 依賴項安裝
COPY requirements.txt .
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
# 項目文件復(fù)制
COPY . .
# 服務(wù)啟動命令
CMD ["python", "deploy_model.py"]依賴配置文件requirements.txt內(nèi)容示例:
torch==1.12.1
torchvisinotallow==0.13.1
flask==2.0.3
gunicorn==20.1.0服務(wù)編排配置
使用Kubernetes實現(xiàn)自動化部署和彈性伸縮:
apiVersion: apps/v1
kind: Deployment
metadata:
name: turboattention-deployment
spec:
replicas: 3
selector:
matchLabels:
app: turboattention
template:
metadata:
labels:
app: turboattention
spec:
containers:
- name: turboattention-container
image: your-docker-repo/turboattention:latest
ports:
- containerPort: 8000
resources:
limits:
memory: "2Gi"
cpu: "1"
requests:
memory: "1Gi"
cpu: "0.5"
---
apiVersion: v1
kind: Service
metadata:
name: turboattention-service
spec:
selector:
app: turboattention
ports:
- protocol: TCP
port: 80
targetPort: 8000
type: LoadBalancer工作流自動化
基于Airflow實現(xiàn)模型更新和部署自動化:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime
default_args = {
'owner': 'airflow',
'start_date': datetime(2023, 1, 1),
}
with DAG('deploy_turboattention', default_args=default_args, schedule_interval='@daily') as dag:
build_docker = BashOperator(
task_id='build_docker_image',
bash_command='docker build -t your-docker-repo/turboattention:latest .'
)
push_docker = BashOperator(
task_id='push_docker_image',
bash_command='docker push your-docker-repo/turboattention:latest'
)
update_kubernetes = BashOperator(
task_id='update_kubernetes_deployment',
bash_command='kubectl apply -f k8s-deployment.yaml'
)
# 定義任務(wù)執(zhí)行順序
build_docker >> push_docker >> update_kubernetes# **性能評估方法**TurboAttention的性能評估需要從多個維度與基準(zhǔn)注意力機制進行對比,包括計算速度、精度、內(nèi)存使用效率和運行穩(wěn)定性等指標(biāo)。
4、基準(zhǔn)測試實現(xiàn)
以下代碼展示了一種基于合成數(shù)據(jù)的性能測試方法:
import time
import torch
def benchmark_attention(attention_layer, x):
start_time = time.time()
for _ in range(100):
output = attention_layer(x)
end_time = time.time()
avg_time = (end_time - start_time) / 100
return avg_time
# 構(gòu)造測試數(shù)據(jù)
batch_size = 32
seq_length = 512
embed_dim = 1024
x = torch.randn(batch_size, seq_length, embed_dim).cuda()
# 標(biāo)準(zhǔn)注意力機制測試
standard_attention = nn.MultiheadAttention(embed_dim, num_heads=8).cuda()
standard_time = benchmark_attention(standard_attention, x)
print(f"標(biāo)準(zhǔn)注意力機制平均執(zhí)行時間:{standard_time:.6f}秒")
# TurboAttention測試
turbo_attention = TurboAttention(embed_dim, num_heads=8, sparse_ratio=0.1).cuda()
turbo_time = benchmark_attention(turbo_attention, x)
print(f"TurboAttention平均執(zhí)行時間:{turbo_time:.6f}秒")實驗結(jié)果顯示,TurboAttention可實現(xiàn)1.5到3倍的推理速度提升,具體提升幅度取決于多個關(guān)鍵參數(shù)的配置,如sparse_ratio(稀疏率)、軟最大值近似的多項式次數(shù)以及漸進式量化的位深度設(shè)置。重要的是,這種顯著的性能提升僅帶來很小的精度損失(根據(jù)具體應(yīng)用場景,絕對精度下降通常控制在1-2%以內(nèi))。
5、技術(shù)發(fā)展方向
TurboAttention為大規(guī)模模型優(yōu)化開辟了新的研究方向:
自適應(yīng)稀疏化機制
開發(fā)基于上下文的動態(tài)稀疏率調(diào)整機制。對于復(fù)雜度較高的輸入?yún)^(qū)域降低稀疏度,而對簡單區(qū)域采用更激進的剪枝策略。
高階近似方法
研究分段多項式或混合查表方案,在保持計算效率的同時提高指數(shù)函數(shù)近似精度。
跨模態(tài)注意力優(yōu)化
隨著多模態(tài)模型的普及,針對不同模態(tài)特征的多項式近似方法需要進一步優(yōu)化。
硬件協(xié)同設(shè)計
下一代GPU或AI專用加速器可考慮在硬件層面直接支持多項式近似計算和多級量化操作。
設(shè)備端學(xué)習(xí)優(yōu)化
利用漸進式量化帶來的內(nèi)存效率提升,探索在資源受限設(shè)備上實現(xiàn)模型微調(diào)和個性化適配。
總結(jié)
TurboAttention在大型語言和視覺模型的注意力機制優(yōu)化方面實現(xiàn)了重要突破,其核心創(chuàng)新包括:
? 稀疏激活軟最大值(SAS):通過多項式近似和重要性篩選,顯著降低了指數(shù)運算開銷。
? 漸進式量化(PQ):采用兩階段量化策略(INT8至INT4/INT2),實現(xiàn)了有效的精度-性能平衡。
? 差異化量化策略:基于敏感度分析的選擇性壓縮方案,確保關(guān)鍵注意力頭的性能不受影響。
TurboAttention通過這些技術(shù)創(chuàng)新顯著降低了計算和內(nèi)存開銷,同時保持了注意力機制捕獲上下文依賴關(guān)系的核心能力。
在工程實踐中,通過現(xiàn)代DevOps工具鏈(Docker、Kubernetes、Airflow等)的支持,TurboAttention可實現(xiàn)平穩(wěn)的生產(chǎn)環(huán)境部署。隨著機器學(xué)習(xí)技術(shù)的持續(xù)發(fā)展,這類高效注意力機制將在降低大規(guī)模模型部署成本方面發(fā)揮重要作用。采用這些優(yōu)化技術(shù)的組織可在保持模型性能的同時,顯著降低硬件投入和能源消耗。





















