













港科技最新DrivingRecon:可泛化自動駕駛4D重建新SOTA!
寫在前面&筆者的個人理解
從這一兩年發表的論文數量可以看出,自動駕駛街景的重建與仿真備受關注,由此構建的自動駕駛仿真器對corner case的生成以及端到端模型的閉環評估/測試都非常重要,本次分享的是一篇關于自動駕駛場景4D重建的工作DrivingRecon。
- 論文鏈接: https://arxiv.org/abs/2412.09043
- 開源地址: https://github.com/EnVision-Research/DriveRecon
過去有很多使用3DGS或者Diffusion來做自動駕駛街景重建/生成的工作,比較具有代表性的是StreetGaussian,OmniRe這一類借助3D bbox將靜態背景和動態物體解耦的框架,后來又出現了使用4D NeRF學習動態信息的方法,雖然取得了不錯的效果,但這些方法都有一個共性,就是需要不斷的訓練來進行重建,即每個場景訓練一個模型,非常耗時。因此作者提出了一種可泛化的自動駕駛4D重建模型DrivingRecon。在模型中,作者引入了PD-Block來更好的融合相鄰視角的圖像特征,消除重疊區域的高斯;也引入了Temporal Cross-attention來增強時序的信息融合,并且解耦動態和靜態物體來更好的學習幾何和運動特征。實驗結果表明,與現有的視圖合成方法相比,DrivingRecon 方法顯著提高了場景重建質量和新視圖合成。此外,作者還探討了 DrivingRecon 在模型預訓練、車輛自適應和場景編輯中的應用。
相關工作回顧
駕駛場景重建
現有的自動駕駛模擬引擎如 CARLA或 AirSim,在創建虛擬環境時需要花費很多時間,而且生成的數據缺乏現實性。Block-NeRF和 Mega-NeRF提出將場景分割成不同的Block用于單獨建模。Urban輻射場利用來自 LiDAR 的幾何信息增強了 NeRF 訓練,而 DNMP利用預先訓練的可變形mesh primitive來表示場景。Streetsurf將場景分為近景、遠景和天空類別,獲得較好的城市街道表面的重建效果。MARS使用單獨的網絡對背景和車輛進行建模,建立了一個實例感知的仿真框架。隨著3DGS的引入,DrivingGaussian引入了復合動態高斯圖和增量靜態高斯,而 StreetGaussian優化了動態高斯的跟蹤姿態(位姿),并引入了四維球諧函數,用于不同時刻的車輛外觀建模。Omnire進一步關注駕駛場景中非剛性對象的建模,例如運動的行人。然而,這些重建算法需要耗時的迭代來建立一個新的場景。
大型重建模型
一些工作提出通過訓練神經網絡來直接學習完整的重建任務,從而大大提高了重建速度。LRM利用大規模多視圖數據集來訓練基于Transformer的 NeRF 重建模型,訓練完的模型具有更好的泛化性,在單次模型前向傳遞中,從稀疏姿態圖像中重建以物體為中心的3D形狀質量更高。類似的工作研究了將場景表示改變為高斯濺射,也有一些方法改變模型的架構以支持更高的分辨率,并將方法擴展到3D 場景。L4GM 利用時間交叉注意力融合多幀信息來預測動態物體的高斯表示。然而,對于自動駕駛,還沒有人探索融合多視圖的特殊方法。簡單的模型會預測相鄰視圖的重復高斯點,顯著降低了重建性能。此外,稀疏的圖像監督和大量的動態物體進一步讓重建的任務變得更復雜。
文章主要貢獻如下:
- DrivingRecon是第一個專門為環繞視圖駕駛場景設計的前饋4D 重建模型
- 提出了 PD-Block,學習從不同的視角和背景區域去除冗余的高斯點。該模塊還學會了對復雜物體的高斯點進行擴張,提高了重建的質量
- 為靜態和動態組件設計了渲染策略,允許渲染圖像跨時間序列進行有效監督
- 驗證了算法在重建、新視圖合成和跨場景泛化方面的性能
- 探索了 DrivingRecon 在預訓練、車輛適應性和場景編輯任務中的有效性
方法詳解
通常,先看一下論文的框架圖有益于對整體的理解,DrivingRecon的整體框架如下:


以上是DrivingRecon的整體思路,下面看一些細節:
3D Position Encoding
這部分主要是為了融合不同視角和不同時間間隔的特征:首先用DepthNet獲得uv坐標下的像素深度d_(u,v),方法也很簡單,直接使用Tanh激活函數來處理第一個通道的圖像特征,然后再將深度投影到世界坐標系:

最后結合圖像特征一起輸入到PD-Block進行多視角特征融合。為了更好的融合,作者在訓練時使用lidar得到的稀疏深度進行約束,即lidar點投影到圖像上與之對應的深度算loss,具體計算為:

其中Md為有效深度的mask。
Temporal Cross Attention
因為視角的稀疏性,精確的街景甚至其他場景的重建是非常困難的。為了獲取更多的有用特征,增強場景建模效果,在時間維度或空間維度來融合特征是比較常見的方法。文章中的方法可以簡單表示為:

其中x是輸入的特征,B表示Batch size, T表示時間維度,V表示視角個數,H,W,C表示特征的高,寬以及通道數。注意,與更為常見的時序交叉注意力不一樣的是,這里同時考慮時間空間的信息融合, 從倒數第二維度可以看出。
Gaussian Adapter


這里為啥要預測坐標偏移量?是因為作者使用的方法不是嚴格的像素對齊的,原因是PD -Block通過將資源從簡單場景重新分配到更復雜的物體上,有效的管理空間的計算冗余。此時世界坐標的計算變為:

這里輸出的光流可以用來獲得每一個世界坐標下的點在下一幀的位置,即:

Prune and Dilate Block(PD-Block)

如上圖所示,自動駕駛車輛上的相鄰相機視野通常會存在重疊部分,就會導致不同視角中的同一個物體會出現重復gaussian預測,疊加后生成的效果會變差,另外在場景表示中,像天空這些區域不需要太多的gaussian來表達,而對于物體邊緣處(高頻處)則需要更多的gaussian來表示,因此作者提出了一個PD-Block的模塊,它可以對復雜實例的高斯點進行擴張,并對相似背景或不同視圖的高斯點進行修剪,步驟如下:
(1)將相鄰視角的特征圖以range view的形式拼接起來,那重疊部分的特征在位置上是比較靠近的,易于融合
(2)然后為了減少內存的使用將range view特征分割成多個區域
(3)在空間中均勻地選擇K個中心,中心特征通過平均其Z個最近點來計算
(4)計算區域特征和中心點之間的余弦相似矩陣S
(5)根據閾值生成生成mask

動靜解耦

分割
主要有兩個作用:一是為了獲得動態物體的mask(例如車輛和行人),靜態物體的mask,以及天空的mask,另外引入語義監督有利網絡對整個場景的理解(建模),作者用的模型是DeepLabv3plus。作者還將3D bbox投影到2D圖像上,以此做為prompt通過SAM獲得更精確的mask,這里使用一個簡單的“或”邏輯合并兩種處理的方式,確保所有動態的物體都獲得對應的mask,相當于雙重保障了。
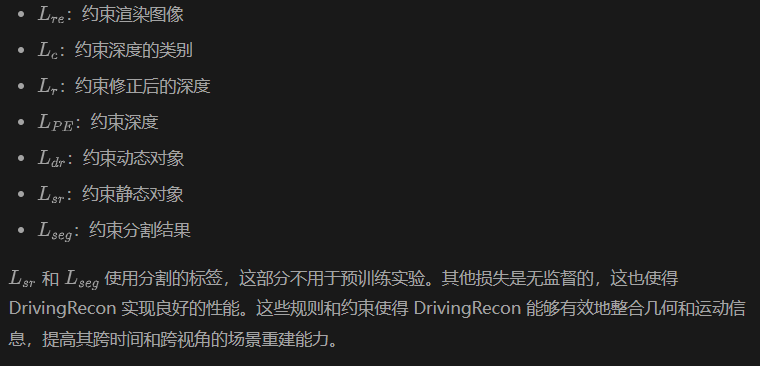
損失函數
訓練中的損失函數為:

實驗分析
與現有方法的渲染結果對比:

與現有方法的指標對比:


從表1和表2可以看出,不管是動態還是靜態對象,指標提升的還是很大的。
重建結果可視化:


泛化性測試結果如下:

消融實驗:

最后,文章最后還討論幾個潛在的應用:
車輛適應性:新車型的引入可能導致攝像機參數的變化,如攝像機類型(內參)和攝像機位置(外參)。所提出的四維重建模型能夠用不同的攝像機參數來渲染圖像,以減小這些參數的潛在過擬合。實驗中作者在 Waymo 上使用隨機的內參渲染圖像,并以隨機的方式渲染新的視角圖像作為一種數據增強的形式。渲染的圖像也會使用圖像檢測中的數據增強方式,包括調整大小和裁剪,然后結合原始數據訓練BEVDepth,結果如下:

預訓練模型:四維重建網絡能夠理解場景的幾何信息、動態物體的運動軌跡和語義信息。這些能力反映在圖像編碼中,其中這些編碼器的權重是共享的。為了利用這些能力進行預訓練,作者用 ResNet-50替換了編碼器。然后重新訓練DrivingRecon,沒有使用任何語義注釋,屬于完全無監督的預訓練。隨后,用預先訓練好的模型替換了 UniAD 的編碼器,并在 nuScenes 數據集上對其進行了微調。與 ViDAR 相比,使用新的預訓練模型取得了更好的性能。

場景編輯:四維場景重建模型能夠獲得一個場景的全面的四維幾何信息,這允許刪除,插入和控制場景中的對象。文中給出了一個例子,在場景中的固定位置添加了帶有人臉的廣告牌,表示汽車停下的corner case:

結論
文章中提出了一種新的4D重建模型DrivingRecon,輸入全景視頻(環視)即可快速重建出4D自動駕駛場景。其中關鍵的創新點是提出了PD-Block,可以刪除相鄰視角的冗余高斯點,并允許復雜邊緣周圍進行點擴張,增強了動態和靜態物體的重建。另外,文章中也引入了一種使用光流預測的動靜態渲染方法,可以更好的監督跨時間序列的動態對象。實驗表明,與現有方法對比,DrivingRecon在場景重建和新視角生成方面具有更優越的性能。并通過實驗證明了可以用于模型的預訓練,車輛自適應,場景編輯等任務。



























