NeuRAD: 用于自動(dòng)駕駛的神經(jīng)渲染(多數(shù)據(jù)集SOTA)
論文"NeuRAD: Neural Rendering for Autonomous Driving",來(lái)自Zenseact,Chalmers科技大學(xué),Linkoping大學(xué)和Lund大學(xué)。
 神經(jīng)輻射場(chǎng)(NeRF)在自動(dòng)駕駛(AD)社區(qū)中越來(lái)越受歡迎。最近的方法顯示了NeRFs在閉環(huán)模擬、AD系統(tǒng)測(cè)試和訓(xùn)練數(shù)據(jù)增強(qiáng)技術(shù)方面的潛力。然而,現(xiàn)有的方法往往需要長(zhǎng)的訓(xùn)練時(shí)間、密集的語(yǔ)義監(jiān)督,缺乏可推廣性。這反過(guò)來(lái)又阻礙了NeRF在AD中的大規(guī)模應(yīng)用。本文提出NeuRAD,一種針對(duì)動(dòng)態(tài)AD數(shù)據(jù)的穩(wěn)健的新視圖合成方法。該方法具有簡(jiǎn)單的網(wǎng)絡(luò)設(shè)計(jì)、包括相機(jī)和激光雷達(dá)的傳感器建模(包括滾動(dòng)快門(mén)、光束發(fā)散和光線(xiàn)降落),適用于開(kāi)箱即用的多個(gè)數(shù)據(jù)集。
神經(jīng)輻射場(chǎng)(NeRF)在自動(dòng)駕駛(AD)社區(qū)中越來(lái)越受歡迎。最近的方法顯示了NeRFs在閉環(huán)模擬、AD系統(tǒng)測(cè)試和訓(xùn)練數(shù)據(jù)增強(qiáng)技術(shù)方面的潛力。然而,現(xiàn)有的方法往往需要長(zhǎng)的訓(xùn)練時(shí)間、密集的語(yǔ)義監(jiān)督,缺乏可推廣性。這反過(guò)來(lái)又阻礙了NeRF在AD中的大規(guī)模應(yīng)用。本文提出NeuRAD,一種針對(duì)動(dòng)態(tài)AD數(shù)據(jù)的穩(wěn)健的新視圖合成方法。該方法具有簡(jiǎn)單的網(wǎng)絡(luò)設(shè)計(jì)、包括相機(jī)和激光雷達(dá)的傳感器建模(包括滾動(dòng)快門(mén)、光束發(fā)散和光線(xiàn)降落),適用于開(kāi)箱即用的多個(gè)數(shù)據(jù)集。
如圖所示:NeuRAD是一種為動(dòng)態(tài)汽車(chē)場(chǎng)景量身定制的神經(jīng)渲染方法。可以改變自車(chē)和其他道路使用者的姿態(tài),也可以自由添加和/或移除參與者。這些功能使NeuRAD適合作為傳感器逼真的閉環(huán)模擬器或強(qiáng)大數(shù)據(jù)增強(qiáng)引擎等組件的基礎(chǔ)。
 本文目標(biāo)是學(xué)習(xí)一種表示,從中可以生成真實(shí)的傳感器數(shù)據(jù),其中可以改變自車(chē)平臺(tái)、行動(dòng)者的姿態(tài),或者兩者兼而有之。假設(shè)可以訪問(wèn)由移動(dòng)平臺(tái)收集的數(shù)據(jù),由設(shè)定的相機(jī)圖像和激光雷達(dá)點(diǎn)云組成,以及對(duì)任何移動(dòng)行動(dòng)者大小和姿態(tài)的估計(jì)。為了實(shí)用性,該方法需要在主要汽車(chē)數(shù)據(jù)集上的重建誤差方面表現(xiàn)良好,同時(shí)將訓(xùn)練和推理時(shí)間保持在最低限度。
本文目標(biāo)是學(xué)習(xí)一種表示,從中可以生成真實(shí)的傳感器數(shù)據(jù),其中可以改變自車(chē)平臺(tái)、行動(dòng)者的姿態(tài),或者兩者兼而有之。假設(shè)可以訪問(wèn)由移動(dòng)平臺(tái)收集的數(shù)據(jù),由設(shè)定的相機(jī)圖像和激光雷達(dá)點(diǎn)云組成,以及對(duì)任何移動(dòng)行動(dòng)者大小和姿態(tài)的估計(jì)。為了實(shí)用性,該方法需要在主要汽車(chē)數(shù)據(jù)集上的重建誤差方面表現(xiàn)良好,同時(shí)將訓(xùn)練和推理時(shí)間保持在最低限度。
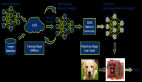
如圖是本文提出方法NeuRAD的概覽:學(xué)習(xí)一個(gè)用于汽車(chē)場(chǎng)景的靜態(tài)和動(dòng)態(tài)的聯(lián)合神經(jīng)特征場(chǎng),通過(guò)行動(dòng)者-覺(jué)察的哈希編碼來(lái)區(qū)分。落入行動(dòng)者邊框內(nèi)的點(diǎn)被轉(zhuǎn)換為行動(dòng)者局部坐標(biāo),并與行動(dòng)者索引一起用于查詢(xún)4D哈希網(wǎng)格。用上采樣CNN將體渲染的光線(xiàn)級(jí)特征解碼為RGB值,并用MLP將其解碼為光線(xiàn)降落概率和強(qiáng)度。
 在新視圖合成[4,47]的工作基礎(chǔ)上,作者用神經(jīng)特征場(chǎng)(NFF)、NeRFs[25]的推廣和類(lèi)似方法[23]對(duì)世界進(jìn)行建模。
在新視圖合成[4,47]的工作基礎(chǔ)上,作者用神經(jīng)特征場(chǎng)(NFF)、NeRFs[25]的推廣和類(lèi)似方法[23]對(duì)世界進(jìn)行建模。
為了渲染圖像,對(duì)一組相機(jī)射線(xiàn)進(jìn)行體渲染,生成特征圖F。如[47]所示,然后依靠CNN來(lái)渲染最終圖像。在實(shí)踐中,特征圖的分辨率低于圖像,并且用CNN進(jìn)行上采樣。這樣能夠大幅減少查詢(xún)的光線(xiàn)數(shù)量。
激光雷達(dá)傳感器允許自動(dòng)駕駛車(chē)輛測(cè)量一組離散點(diǎn)的深度和反射率(強(qiáng)度)。他們通過(guò)發(fā)射激光束脈沖和測(cè)量飛行時(shí)間來(lái)確定距離和反射率的返回功率。為了捕捉這些特性,將來(lái)自姿態(tài)激光雷達(dá)傳感器的傳輸脈沖建模為一組射線(xiàn),并使用類(lèi)似體渲染技術(shù)。
考慮不返回任何點(diǎn)的激光束射線(xiàn)。如果返回功率過(guò)低,就會(huì)出現(xiàn)一種現(xiàn)象,稱(chēng)為射線(xiàn)降落,這對(duì)于減少模擬-實(shí)際差別的建模非常重要[21]。通常,這樣的光線(xiàn)傳播得很遠(yuǎn)而不會(huì)碰到表面,或者碰到光束反彈到空地上的表面,例如鏡子、玻璃或潮濕的路面。對(duì)這些影響進(jìn)行建模對(duì)于傳感器真實(shí)模擬很重要,但如[14]所述,很難完全基于物理來(lái)捕捉,因?yàn)樗鼈円蕾?lài)于(通常未公開(kāi)的)低層傳感器檢測(cè)邏輯的細(xì)節(jié)。因此,選擇從數(shù)據(jù)中學(xué)習(xí)光線(xiàn)降落。與強(qiáng)度類(lèi)似,可體渲染光線(xiàn)特征,并將其通過(guò)一個(gè)小MLP來(lái)預(yù)測(cè)光線(xiàn)下降概率pd(r)。請(qǐng)注意,與[14]不同的是,不對(duì)激光雷達(dá)光束的二次回波進(jìn)行建模,因?yàn)閷?shí)驗(yàn)中五個(gè)數(shù)據(jù)集中不存在此信息。
將神經(jīng)特征場(chǎng)(NFF)的定義擴(kuò)展為學(xué)習(xí)函數(shù)(s,f)=NFF(x,t,d),其中x是空間坐標(biāo),t表示時(shí)間,d表示視角方向。重要的是,該定義引入了時(shí)間作為輸入,這對(duì)于場(chǎng)景的動(dòng)態(tài)方面建模至關(guān)重要。
神經(jīng)架構(gòu)
NFF架構(gòu)遵循NeRF[4,27]中公認(rèn)的最佳方法。給定位置x和時(shí)間t,查詢(xún)行動(dòng)者-覺(jué)察哈希編碼。然后,這種編碼輸入到一個(gè)小MLP中,該感知器計(jì)算有符號(hào)距離s和中間特征g。用球諧波[27]對(duì)視圖方向d進(jìn)行編碼,使模型能夠捕捉反射和其他與視圖相關(guān)的效果。最后,通過(guò)第二個(gè)MLP聯(lián)合處理方向編碼和中間特征,用g的跳躍連接來(lái)增強(qiáng),從而產(chǎn)生特征f。
場(chǎng)景構(gòu)成
與之前的工作[18,29,46,47]類(lèi)似,將世界分解為兩個(gè)部分,靜態(tài)背景和一組剛性動(dòng)態(tài)行動(dòng)者,每個(gè)行動(dòng)者由一個(gè)3D邊框和一組SO(3)姿態(tài)定義。提供雙重目的:簡(jiǎn)化學(xué)習(xí)過(guò)程,并允許一定程度的可編輯性,在訓(xùn)練后可以動(dòng)態(tài)行動(dòng)者生成新場(chǎng)景。與之前不同場(chǎng)景元素使用單獨(dú)NFF的方法不同,本文用一個(gè)單個(gè)統(tǒng)一NFF,其中所有網(wǎng)絡(luò)都是共享的,靜態(tài)和動(dòng)態(tài)組件之間的區(qū)別由行動(dòng)者-覺(jué)察的哈希編碼透明處理。編碼策略很簡(jiǎn)單:根據(jù)給定樣本(x,t)是否位于行動(dòng)者邊框內(nèi),用兩個(gè)函數(shù)中的一個(gè)對(duì)其進(jìn)行編碼。
無(wú)界靜態(tài)場(chǎng)景
用多分辨率哈希網(wǎng)格[27]表示靜態(tài)場(chǎng)景,因?yàn)檫@已被證明是一種高度表達(dá)和高效的表示。然而,為了將無(wú)界場(chǎng)景映射到網(wǎng)格上,采用MipNerf-360[3]中提出的收縮方法。這能夠用單個(gè)哈希網(wǎng)格準(zhǔn)確地表示附近的道路元素和遠(yuǎn)處的云。相比之下,現(xiàn)有的方法利用專(zhuān)用的NFF來(lái)捕捉天空和其他遙遠(yuǎn)的區(qū)域[47]。
剛性動(dòng)態(tài)行動(dòng)者
當(dāng)樣本(x,t)落在行動(dòng)者的邊框內(nèi)時(shí),其空間坐標(biāo)x和視角方向d在給定時(shí)間t轉(zhuǎn)換到行動(dòng)者的坐標(biāo)系。忽略之后的時(shí)間方面,并從與時(shí)間無(wú)關(guān)的多分辨率哈希網(wǎng)格中采樣特征,就像靜態(tài)場(chǎng)景一樣。簡(jiǎn)單地說(shuō),需要分別對(duì)多個(gè)不同的哈希網(wǎng)格進(jìn)行采樣,每個(gè)行動(dòng)者是一個(gè)。然而,轉(zhuǎn)而使用單個(gè)4D哈希網(wǎng)格,其中第四個(gè)維度對(duì)應(yīng)于行動(dòng)者索引。這種方法允許并行地對(duì)所有行動(dòng)者特征進(jìn)行采樣,在匹配單獨(dú)哈希網(wǎng)格性能的同時(shí)實(shí)現(xiàn)顯著的加速。
多尺度場(chǎng)景問(wèn)題
將神經(jīng)渲染應(yīng)用于汽車(chē)數(shù)據(jù)的最大挑戰(zhàn)之一是處理這些數(shù)據(jù)中存在的多個(gè)細(xì)節(jié)級(jí)。當(dāng)車(chē)輛行駛很長(zhǎng)距離時(shí),無(wú)論是從遠(yuǎn)處還是近距離都可以看到許多表面。在這些多尺度設(shè)置中天真地應(yīng)用iNGP[27]或NeRF的位置嵌入會(huì)導(dǎo)致混疊偽影[2]。為了解決這一問(wèn)題,許多方法將射線(xiàn)建模為截錐體,截錐體縱向由bin的大小決定,徑向由像素面積以及與傳感器的距離決定[2,3,13]。
Zip-NeRF[4]是目前iNGP哈希網(wǎng)格的唯一抗混疊(anti-aliasing)方法,它結(jié)合了兩種截頭體建模技術(shù):多采樣和降低權(quán)重。在多采樣中,對(duì)截頭體多個(gè)位置的位置嵌入進(jìn)行平均,捕捉縱向和徑向范圍。對(duì)于降低權(quán)重,每個(gè)樣本都被建模為各向同性高斯,網(wǎng)格特征的權(quán)重與單元(cell)大小和高斯方差之間比例成比,從而有效地抑制更精細(xì)的分辨率。雖然組合技術(shù)顯著提高了性能,但多重采樣也顯著增加了運(yùn)行時(shí)間。所以本文目標(biāo)是以最小的運(yùn)行影響結(jié)合規(guī)模信息。受Zip-NeRF的啟發(fā),作者提出了一種直觀的降低權(quán)重方案,根據(jù)哈希網(wǎng)格特征相對(duì)于截頭體的大小對(duì)其進(jìn)行權(quán)重降低。
高效采樣
渲染大規(guī)模場(chǎng)景的另一個(gè)困難是需要高效的采樣策略。在一張圖像中,可能想在附近的交通標(biāo)志上渲染詳細(xì)的文本,同時(shí)捕捉幾公里外摩天大樓之間的視差效果。為了實(shí)現(xiàn)這兩個(gè)目標(biāo),對(duì)射線(xiàn)進(jìn)行均勻采樣將需要每條射線(xiàn)數(shù)千個(gè)樣本,這在計(jì)算上是不可行的。以前的工作在很大程度上依賴(lài)激光雷達(dá)數(shù)據(jù)來(lái)修剪樣本[47],因此很難在激光雷達(dá)的工作之外進(jìn)行渲染。
相反,本文根據(jù)冪函數(shù)[4]沿射線(xiàn)渲染樣本,使得樣本之間的空間隨著與射線(xiàn)原點(diǎn)的距離而增加。即便如此,不可能在樣本數(shù)量急劇增加的情況下滿(mǎn)足所有相關(guān)條件。因此,還采用兩輪的提議采樣(proposal sampling)[25],其中查詢(xún)NFF(neural feature field)的輕量級(jí)版本,生成沿射線(xiàn)的權(quán)重分布。然后,根據(jù)這些權(quán)重渲染一組新的樣本。經(jīng)過(guò)兩輪這個(gè)過(guò)程后,得到了一組精細(xì)的樣本,這些樣本集中在射線(xiàn)上的相關(guān)位置,可以用來(lái)查詢(xún)?nèi)叽鏝FF。為了監(jiān)督所提出的網(wǎng)絡(luò),采用了一種抗混疊的在線(xiàn)蒸餾方法[4],并進(jìn)一步使用激光雷達(dá)進(jìn)行監(jiān)督。
建模滾動(dòng)快門(mén)
在基于NeRF的標(biāo)準(zhǔn)公式中,假設(shè)每個(gè)圖像都是從一個(gè)原點(diǎn)o捕獲的。然而,許多相機(jī)傳感器都有滾動(dòng)快門(mén),即像素行是按順序捕獲的。因此,相機(jī)傳感器可以在第一行的捕獲和最后一行的捕獲之間移動(dòng),打破了單一原點(diǎn)的假設(shè)。雖然合成數(shù)據(jù)[24]或慢速手持相機(jī)拍攝的數(shù)據(jù)不是問(wèn)題,但滾動(dòng)快門(mén)在快速移動(dòng)車(chē)輛的拍攝中變得明顯,尤其是側(cè)面相機(jī)。同樣的影響也存在于激光雷達(dá)中,每次掃描通常在0.1s內(nèi)收集,當(dāng)以高速公路速度行駛時(shí),這相當(dāng)于幾米移動(dòng)。即使對(duì)于自我運(yùn)動(dòng)補(bǔ)償?shù)狞c(diǎn)云,這些差異也可能導(dǎo)致有害的視線(xiàn)誤差,即3D點(diǎn)轉(zhuǎn)化為穿過(guò)其他幾何的射線(xiàn)。為了減輕這些影響,為每條光線(xiàn)指定單獨(dú)的時(shí)間并根據(jù)估計(jì)的運(yùn)動(dòng)調(diào)整其原點(diǎn),這樣對(duì)滾動(dòng)快門(mén)進(jìn)行建模。由于滾動(dòng)快門(mén)會(huì)影響場(chǎng)景的所有動(dòng)態(tài)元素,因此會(huì)對(duì)每個(gè)單獨(dú)的光線(xiàn)時(shí)間,行動(dòng)者姿態(tài)做線(xiàn)性插值。
不同的相機(jī)設(shè)置
模擬自動(dòng)駕駛序列時(shí)的另一個(gè)問(wèn)題是,圖像來(lái)自不同的相機(jī),具有潛在的不同捕獲參數(shù),如曝光。在這里,從“NeRFs in the wild”[22]的研究中獲得了靈感,其中為每個(gè)圖像學(xué)習(xí)外觀嵌入,并與其特征一起傳遞到第二個(gè)MLP。然而,當(dāng)知道哪個(gè)圖像來(lái)自哪個(gè)傳感器時(shí),反而為每個(gè)傳感器學(xué)習(xí)單個(gè)嵌入,從而最大限度地減少過(guò)擬合的可能性,并允許在生成新視圖時(shí)使用這些傳感器嵌入。當(dāng)渲染特征而不是顏色時(shí),在體渲染后應(yīng)用這些嵌入,顯著減少了計(jì)算開(kāi)銷(xiāo)。
含噪的行動(dòng)者姿態(tài)
模型依賴(lài)于對(duì)動(dòng)態(tài)行動(dòng)者姿態(tài)的估計(jì),無(wú)論其是以注釋的形式還是作為跟蹤輸出。為了解決缺陷,將行動(dòng)者姿態(tài)作為可學(xué)習(xí)的參數(shù)納入模型中,并對(duì)其進(jìn)行聯(lián)合優(yōu)化。姿態(tài)參數(shù)化為平移t和旋轉(zhuǎn)R,用6D-表示[50]。
注:NeuRAD是在開(kāi)源項(xiàng)目Nerfstudio[33]中實(shí)現(xiàn)的。用Adam[17]optimizer訓(xùn)練方法,進(jìn)行20000次迭代。使用一臺(tái)英偉達(dá)A100,訓(xùn)練大約需要1個(gè)小時(shí)。
復(fù)現(xiàn)UniSim:UniSim[47]是一種神經(jīng)閉環(huán)傳感器模擬器。它具有逼真的渲染效果,對(duì)可用的監(jiān)督幾乎沒(méi)有任何假設(shè),即它只需要相機(jī)圖像、激光雷達(dá)點(diǎn)云、傳感器姿態(tài)和帶有動(dòng)態(tài)行動(dòng)者軌跡的3D邊框。這些特性使UniSim成為一個(gè)合適的基線(xiàn),因?yàn)樗苋菀讘?yīng)用于新自動(dòng)駕駛數(shù)據(jù)集。然而,該代碼是封閉源代碼,也沒(méi)有非官方的實(shí)現(xiàn)。因此,本文選擇重新實(shí)現(xiàn)UniSim,作為自己的模型,在Nerfstudio[33]中這樣實(shí)現(xiàn)。由于UniSim的主要文章沒(méi)有詳細(xì)說(shuō)明許多模型細(xì)節(jié),只能依賴(lài)于IEEE Xplore提供的補(bǔ)充材料。盡管如此,一些細(xì)節(jié)仍然是未知的,作者已經(jīng)調(diào)整了這些超參數(shù),匹配10個(gè)選定PandaSet[45]序列的報(bào)告性能。