SPAR:融合自對弈與樹搜索的高性能指令優化框架
大語言模型的指令遵循能力需要模型能夠準確識別指令中的細微要求,并在輸出中精確體現這些要求。現有方法通常采用偏好學習進行優化,在創建偏好對時直接從模型中采樣多個獨立響應。但是這種方法可能會引入與指令精確遵循無關的內容變化(例如,同一語義的不同表達方式),這干擾了模型學習識別能夠改進指令遵循的關鍵差異。
針對這一問題,這篇論文提出了SPAR框架,這是一個集成樹搜索自我改進的自對弈框架,用于生成有效且具有可比性的偏好對,同時避免干擾因素。通過自對弈機制,大語言模型采用樹搜索策略,基于指令對先前的響應進行改進,同時將不必要的變化降至最低。
主要創新點:
- 發現從獨立采樣響應中獲得的偏好對通常包含干擾因素,這些因素阻礙了通過偏好學習提升指令遵循能力
- 提出SPAR,一個創新的自對弈框架,能夠在指令遵循任務中實現持續性自我優化
- 構建了包含43K個復雜指令遵循提示的高質量數據集,以及一個能夠提升大語言模型指令遵循能力的監督微調數據集
方法論
整體框架
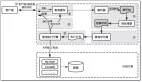
SPAR迭代訓練框架如圖所示:

- 在形式化定義中,每次迭代時,給定提示集中的指令x,執行模型生成響應y
- 改進模型負責識別未能準確遵循指令的響應,將其標記為負面響應
- 框架的核心目標是將負面響應優化為符合要求的正確響應
- 收集生成的改進對,通過直接偏好優化(DPO)來優化執行模型
- 同時,應用拒絕采樣微調(RFT)提升改進模型性能,為下一輪自我優化做好準備
數據構建方法
提示構建
- 種子提示:基于Infinity-Instruct數據集構建初始種子提示集,該數據集包含一千萬條高質量對話。經過基于長度、關鍵詞和自我-BLEU的規則過濾,最終獲得約50k條種子提示
- 分類法驅動的提示構建:采用基于分類法的機制確保約束類型的全面性和平衡性。在建立約束分類體系后,基于種子提示構建復雜指令遵循任務,最終生成約43k條提示
模型初始化
- 執行模型數據構建: 首先收集高性能語言模型對復雜提示的響應,生成用于執行模型的監督微調(SFT)數據(x, y) ∈ DActor,其中x表示復雜指令,y表示高性能模型的響應。隨后對基礎模型進行微調,得到初始執行模型M0
- 改進模型數據構建: 為使改進模型具備高質量的判斷和改進能力,從初始執行模型M0中采樣響應。收集高性能語言模型的判斷結果,形成數據集(x, y, j) ∈ DJSFT。識別并收集被判定為未能準確遵循指令的響應作為負面樣本。對這些負面響應,使用高性能語言模型進行最小化修正,避免引入無關變化
- 訓練策略: 執行模型和改進模型均采用標準監督微調,損失函數定義如下:

其中q代表輸入,r代表目標響應,N代表r的長度。執行模型訓練中,輸入q = x,目標r = y。改進模型訓練中,對于DJSFT,輸入q = (x, y),目標r = j;對于DRSFT,輸入q = (x, ynegative, j),目標r = yrefined。
集成樹搜索的自對弈訓練機制
a) 負面數據采集流程
- 對每個提示x,首先從執行模型中采樣K個響應{y1, y2, . . . , yK}
- 對每組提示-響應對,利用改進模型生成判斷結果,包含兩個核心要素:指令遵循程度的標簽判定和詳細的評估說明
- 為提高判斷準確性,引入自一致性機制,通過從改進模型獲取多個判斷結果并采用多數投票確定最終標簽
- 在完成多數投票后,隨機選取一個與投票標簽一致的判斷作為最終結果,這使論文提出的方法能夠識別出那些會導致指令遵循失敗的高難度提示,形成(x, ynegative, j)格式的數據元組,其中ynegative表示不合格響應,j為對應判斷結果
b) 樹搜索優化方法
- 考慮到直接改進往往導致較低的成功率,本研究采用樹搜索方法,實現了廣度優先搜索(BFS)和深度優先搜索(DFS)策略
- 以BFS為例,從不合格的指令-響應對及其判斷結果作為根節點出發,逐層擴展搜索樹,直至找到符合要求的響應
- 在每個中間節點,為當前響應生成潛在的改進方案,并由改進模型評估其正確性。生成的改進方案數量即為分支數
- 在樹的每一層,改進模型執行以下操作:1). 為當前層的所有節點生成潛在的改進方案;2). 評估這些改進方案的正確性。由此生成包含新響應及其對應判斷的子節點集合
- 搜索過程持續進行,直到獲得數據元組(x, ynegative, yrefined),其中yrefined為經過改進的合格響應
c) 執行模型訓練方法
- 利用改進對數據進行偏好學習,采用DPO方法優化執行模型
- 在第t次迭代中,使用改進對(ynegative, yrefined)訓練執行模型Mt,將ynegative作為被拒絕樣本(yl),yrefined作為被選擇樣本(yw)
- 訓練數據集記為Dtdpo,DPO損失函數定義如下:

其中π tθ表示執行模型Mt,參考模型π ref使用Mt初始化并在訓練過程中保持不變。這一過程產生新的執行模型Mt+1,用于下一輪迭代
d) 改進模型訓練方法
鑒于改進模型的輸入具有模板化特征,論文采用拒絕采樣微調(RFT)方法獲取新的改進模型Rt+1。RFT訓練數據包含兩個主要組成部分:
(1) 改進訓練數據集
- 改進訓練數據集由記錄不合格響應改進過程的數據元組構成
- 對于樹搜索改進過程中的每個不合格響應,收集(x, yp, jp, yrefined)格式的數據元組,其中(x, yp, jp)代表改進樹中最終合格響應的父節點,yrefined為經過改進的合格響應
(2) 判斷訓練數據集
- 判斷訓練數據來源于負面數據采集過程和樹搜索過程中的節點
- 該數據集由(x, yi, ji)格式的元組組成,其中x為提示,yi為對應響應,ji為與多數投票結果一致的判斷
- 隨后,基于構建的訓練數據進行監督微調
- 對于改進數據集Dtrefine,采用數據元組(x, yp, jp, yrefined),輸入q = (x, yp, jp),目標r = yrefined。對于判斷數據集Dtjudge,采用數據元組(x, yi, ji),輸入q = (x, yi),目標r = ji。
實驗研究
執行模型評估結果
SPAR在指令遵循能力方面的顯著提升
下表展示了經過迭代訓練的大語言模型在指令遵循基準測試上的核心性能指標

經過三輪迭代訓練后,SPAR-8B-DPO-iter3模型在IFEval評測中的表現超越了GPT-4-Turbo(后者的平均準確率為81.3%)。此外,在推理階段引入樹搜索優化技術后,模型性能獲得顯著提升
值得注意的是,SPAR在模型規模擴展方面表現出優異的特性,這極大地增強了LLaMA3-70B-Instruct模型的指令遵循能力
SPAR對模型通用能力的影響分析
下表呈現了在通用基準測試上的性能數據

實驗數據表明,SPAR不僅保持了模型的通用能力,在某些場景下還帶來了性能提升,尤其是在GSM8k和HumanEval基準測試中。這證實了增強的指令遵循能力有助于提升大語言模型的整體對齊效果
SPAR相較于基線方法的優勢
下圖展示了各輪訓練迭代在IFEval評測中的進步情況

在每輪迭代中,SPAR都展現出明顯的優勢。特別值得注意的是,其他方法即使經過三輪迭代,其性能仍未能達到SPAR首輪迭代的水平
改進模型評估結果
SPAR在判斷能力方面的迭代提升
下表展示了經過迭代訓練的大語言模型在LLMBar評測中的判斷能力表現

實驗結果顯示,SPAR迭代訓練顯著提升了模型評估指令遵循任務的能力
在第三輪迭代后,改進模型SPAR-8B-RFT-iter3的性能超越了用于構建判斷SFT數據集的GPT-4o-Mini模型
SPAR在改進能力方面的持續優化
下表呈現了改進能力的評估結果。其中Acc-GPT采用GPT-4o作為評判標準;Acc-SPAR則使用SPAR-8B-RFT-iter3進行評估

數據顯示,LLaMA3-8B-Instruct模型的改進準確率在每輪訓練迭代中均呈現穩定提升趨勢,最終達到了與用于SFT數據構建的高性能模型GPT-4o-Mini相當的水平
總結
本研究提出了創新性的自對弈框架SPAR,通過改進對訓練提升大語言模型的指令遵循能力。研究發現,與傳統方法采用獨立采樣響應構建偏好對相比,通過最小化外部因素并突出關鍵差異的改進對方法,能在指令遵循任務上實現顯著性能提升。采用本框架進行迭代訓練的LLaMA3-8B-Instruct模型在IFEval評測中展現出超越GPT-4-Turbo的性能。通過推理計算能力的擴展,模型性能還有進一步提升的空間