













LeCun預言的自監督模型來了:首個多模態高性能自監督算法
自監督學習能在各種任務中學習到分層特征,并以現實生活中可使用的海量數據作為資源,因此是走向更通用人工智能的一種途徑,也是深度學習三巨頭之一、圖靈獎得主 Yann LeCun 一直推崇的研究方向。
LeCun 認為:相比于強化學習,自監督學習(SSL)可以產生大量反饋,能夠預測其輸入的任何一部分(如預測視頻的未來畫面),從而具有廣泛的應用前景。
自監督學習通過直接觀察環境來進行學習,而非通過有標簽的圖像、文本、音頻和其他數據源進行學習。然而從不同模態(例如圖像、文本、音頻)中學習的方式存在很大差異。這種差異限制了自監督學習的廣泛應用,例如為理解圖像而設計的強大算法不能直接應用于文本,因此很難以相同的速度推動多種模態的進展。
現在,MetaAI(原 Facebook AI)提出了一種名為 data2vec 的自監督學習新架構,在多種模態的基準測試中超越了現有 SOTA 方法。

data2vec 是首個適用于多模態的高性能自監督算法。Meta AI 將 data2vec 分別應用于語音、圖像和文本,在計算機視覺、語音任務上優于最佳單一用途算法,并且在 NLP 任務也能取得具有競爭力的結果。此外,data2vec 還代表了一種新的、全面的自監督學習范式,其提高了多種模態的進步,而不僅僅是一種模態。data2vec 不依賴對比學習或重建輸入示例,除了幫助加速 AI 的進步,data2vec 讓我們更接近于制造能夠無縫地了解周圍世界不同方面的機器。data2vec 使研究者能夠開發出適應性更強的 AI,Meta AI 相信其能夠在多種任務上超越已有系統。

- 論文地址:https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language
- 項目地址:https://github.com/pytorch/fairseq/tree/main/examples/data2vec
論文一作 Meta AI 研究員 Alexei Baevski 表示:我們發布了最新 SSL 方法 data2vec,與單獨訓練相比,我們在具有相同預訓練任務的視覺、語音和 NLP 上獲得了 SOTA。語音和文本的代碼和模型已經發布,視覺模型代碼即將到來!
即將成為 Meta CTO 的 Boz(領導 Reality Labs 團隊的 AR、VR、AI、Portal 等)也發推表示:很高興 data2vec 能夠幫助為跨多種模態的、更通用的自監督學習鋪平道路——這項工作還將對我們正在構建的 AR 眼鏡開發情境化 AI 產生重大影響。

data2vec 是如何工作的?
大部分 AI 仍然基于監督學習,它只適用于具有標注數據的任務。但是,假如我們希望機器可以完更多的任務,那么收集所有的標注數據將變得不現實。例如,雖然研究人員在為英語語音和文本創建大規模標注數據集方面做了大量工作,但對于地球上成千上萬的語言來說,這樣做是不可行的。
自監督使計算機能夠通過觀察世界,然后弄清楚圖像、語音或文本的結構來了解世界。不需要專門訓練就能對圖像進行分類或理解語音的機器,其擴展性也會大大提高。
data2vec 訓練方式是通過在給定輸入的部分視圖的情況下預測完整輸入模型表示(如下動圖所示):首先 data2vec 對訓練樣本的掩碼版本(學生模型)進行編碼,然后通過使用相同模型參數化為模型權重的指數移動平均值(教師模型)對輸入樣本的未掩碼版本進行編碼來構建訓練目標表示。目標表示對訓練樣本中的所有信息進行編碼,學習任務是讓學生在給定輸入部分視圖的情況下預測這些表示。

data2vec 以相同的方式學習圖像、語音和文本。
模型架構
Meta AI 使用標準的 Transformer 架構(Vaswani 等人,2017):對于計算機視覺,Meta AI 使用 ViT 策略將圖像編碼為一系列 patch,每個 patch 跨越 16x16 像素,然后輸入到線性變換(Dosovitskiy 等人, 2020;Bao 等人,2021)。語音數據使用多層 1-D 卷積神經網絡進行編碼,該網絡將 16 kHz 波形映射到 50 Hz 表示(Baevski 等人,2020b)。對文本進行預處理以獲得子詞(sub-word)單元(Sennrich 等人,2016;Devlin 等人,2019),然后通過學習的嵌入向量將其嵌入到分布空間中。
data2vec 還可以為不同模態預測不同的單元:圖像的像素或視覺 token、文本的單詞以及語音的學習清單。像素的集合與音頻波形或文本段落非常不同,因此,算法設計與特定的模態緊密聯系在一起。這意味著算法在每種模式下的功能仍然不同。

掩碼:在輸入樣本作為 token 序列嵌入后,Meta AI 用學習的掩碼嵌入 token 替換掩碼單元的一部分,并將序列饋送到 Transformer 網絡。對于計算機視覺,Meta AI 遵循 Bao 等人的分塊掩碼(block-wise)策略;對于語音,Meta AI 掩碼潛在語音表示的跨度 ;對于語言,Meta AI 使用掩碼 token 。
訓練目標:Meta AI 預測的表示是上下文表示,不僅對特定的時間步長進行編碼,還對來自樣本的其他信息進行編碼,這是由于在 Transformer 網絡中使用了自注意力,這是與 BERT、wav2vec 2.0 或 BEiT、MAE、SimMIM 和 MaskFeat 重要區別,這些預測目標缺乏上下文信息。
面向多種模態:data2vec 通過訓練模型來簡化其方法,以預測輸入數據的表征。沒有預測視覺 token、詞、聲音等的方法,而是專注于預測輸入數據的表征,單個算法就可以處理完全不同類型的輸入。這消除了學習任務中對特定模態目標的依賴。
直接預測表征并不簡單,它需要為任務定義一個穩健的特征歸一化,以對不同的模態都是可靠的。該研究使用教師網絡首先從圖像、文本或語音中計算目標表征。然后掩碼部分輸入并使用學生網絡重復該過程,然后預測教師網絡的潛在表征。即使只能查看部分信息,學生模型也必須預測完整輸入數據的表征。教師網絡與學生模型相同,但權重略有不同。
實驗及結果
該研究在 ImageNet 計算機視覺基準上測試了該方法,結果如下。
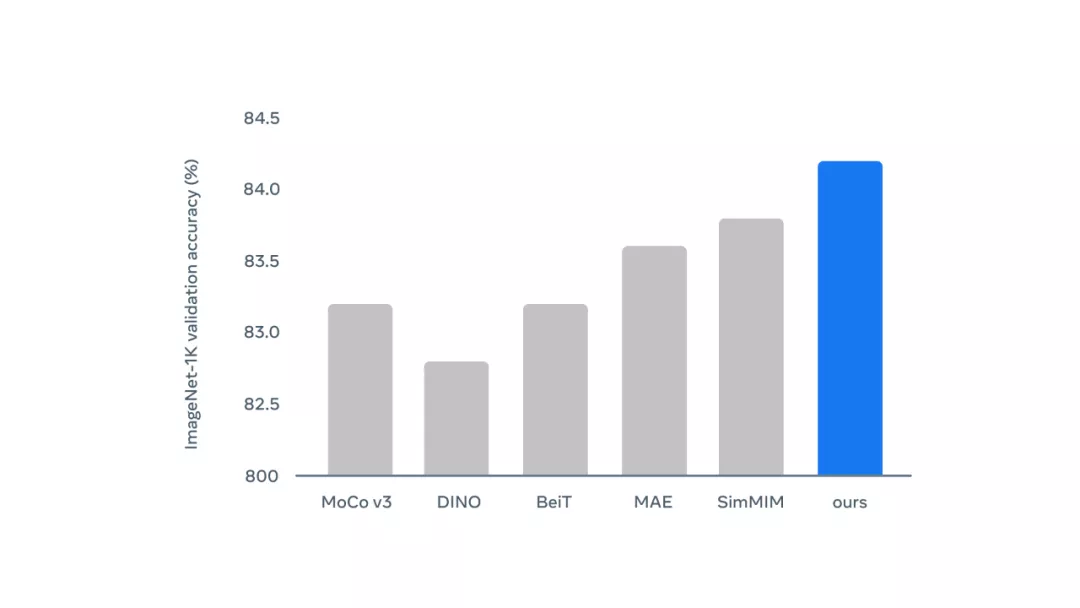
用于計算機視覺的 data2vec:在 ImageNet 基準上,ViT-B 模型與其他方法的性能比較結果。
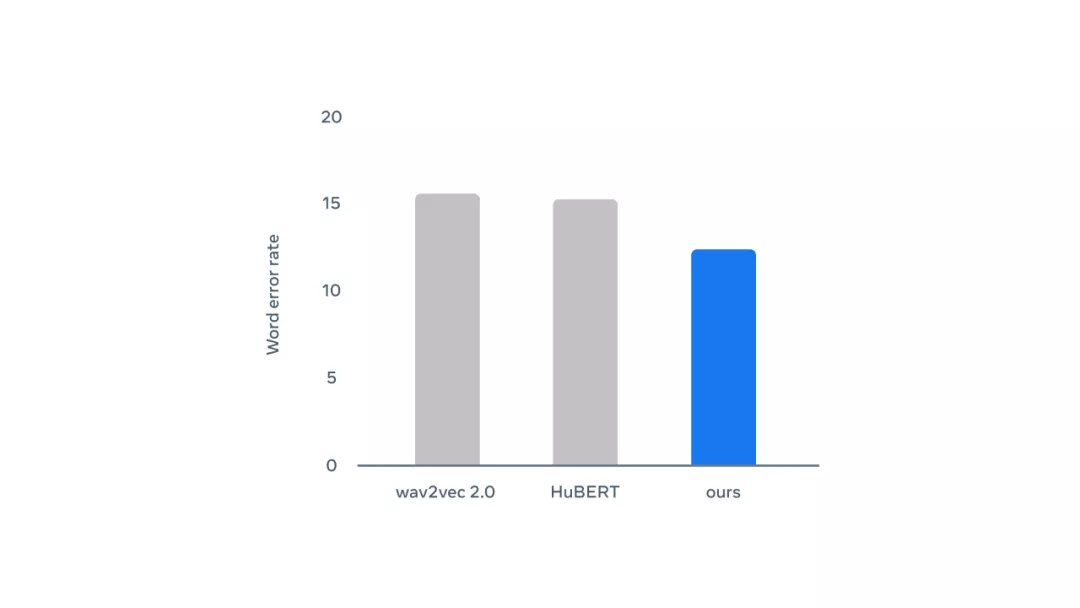
應用于語音的 data2vec:在 LibriSpeech 基準測試中使用 10h 標記數據的 Base 模型與其他方法的性能比較結果,錯誤率越低,性能越好。
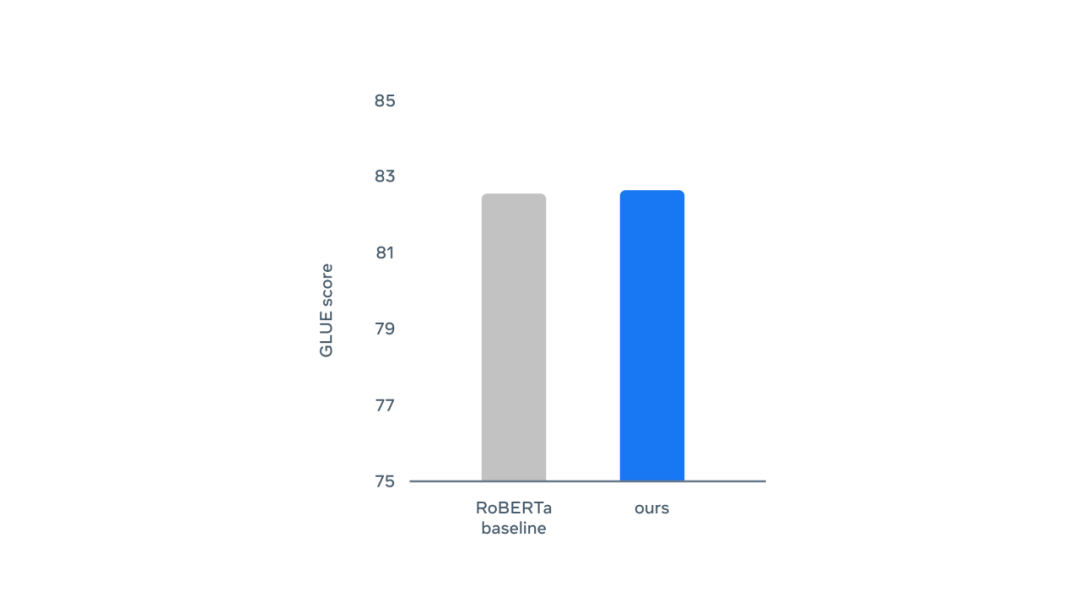
應用于文本的 data2vec:在使用原始 BERT 設置重新訓練時,與 RoBERTa 相比,Base 模型在 GLUE 自然語言理解基準上的性能。分數越高,性能越好。
通過觀察進行學習
自監督學習在計算機視覺、視頻等多種模態方面取得了很大進展。這種方法的核心思想是為了更廣泛地學習,以使人工智能可以學習完成各種任務,包括完全未見過的任務。研究者希望機器不僅能夠識別訓練數據中顯示的動物,而且還能通過給定描述識別新生物。
data2vec 證明其自監督算法可以在多種模態下良好執行,甚至比現有最佳算法更好。這為更一般的自監督學習鋪平了道路,并讓人工智能更接近使用視頻、文本、音頻來學習復雜世界的目標。
由于收集高質量數據成本很高,因此該研究還希望 data2vec 能讓計算機僅用很少的標記數據來完成任務。data2vec 是邁向更通用人工智能的重要一步,未來有望消除對特定模態特征提取器的需求。



























