入門 Transformer:概念、代碼與流程詳解
引言
論文《Attention is All You Need》(Vaswani等,2017)提出了Transformer架構,這一模型通過完全摒棄標準的循環神經網絡(RNN)組件,徹底改變了自然語言處理(NLP)領域。相反,它利用了一種稱為“注意力”的機制,讓模型在生成輸出時決定如何關注輸入的特定部分(如句子中的單詞)。在Transformer之前,基于RNN的模型(如LSTM)主導了NLP領域。這些模型一次處理一個詞元,難以有效捕捉長距離依賴關系。而Transformer則通過并行化數據流,并依賴注意力機制來識別詞元之間的重要關系。這一步驟帶來了巨大的影響,推動了機器翻譯、文本生成(如GPT)甚至計算機視覺任務等領域的巨大飛躍。
在深入Transformer模型的實現之前,強烈建議對深度學習概念有基本的了解。熟悉神經網絡、embedding、激活函數和優化技術等主題,將更容易理解代碼并掌握Transformer的工作原理。如果你對這些概念不熟悉,可以考慮探索深度學習框架的入門資源,以及反向傳播等基礎主題。

導入庫
我們將使用PyTorch作為深度學習框架。PyTorch提供了構建和訓練神經網絡所需的所有基本工具:
import torch
import torch.nn as nn
import math這些導入包括:
- torch:PyTorch主庫。
- torch.nn:包含與神經網絡相關的類和函數,如nn.Linear、nn.Dropout等。
- math:用于常見的數學操作。
Transformer架構
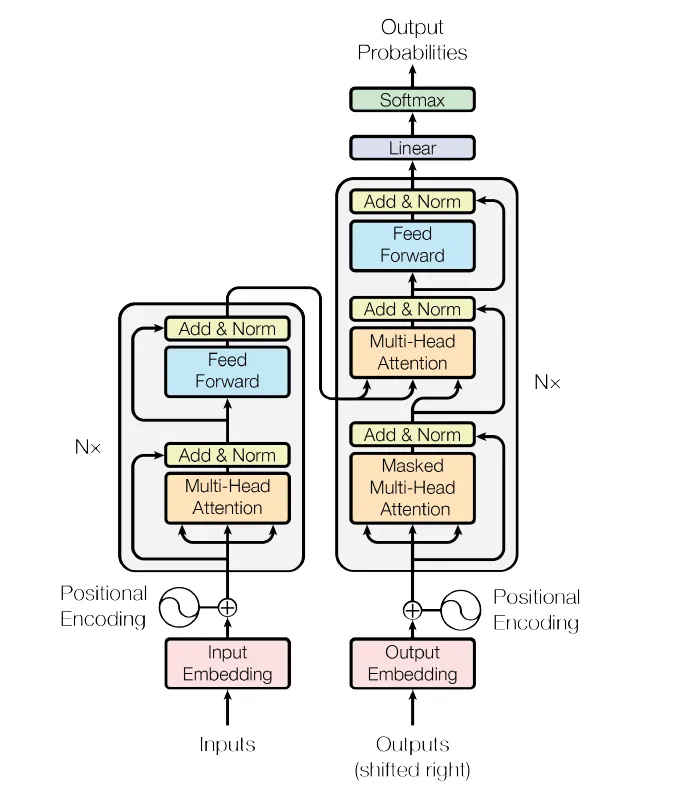
輸入embedding
什么是embedding?
embedding是單詞或詞元的密集向量表示。與將單詞表示為獨熱編碼向量不同,embedding將每個單詞映射到低維連續向量空間。這些embedding捕捉了單詞之間的語義關系。例如,“男人”和“女人”的詞embedding在向量空間中的距離可能比“男人”和“狗”更近。
以下是embedding層的代碼:
class InputEmbedding(nn.Module):
def __init__(self, d_model: int, vocab_size: int):
super().__init__()
self.d_model = d_model
self.vocab_size = vocab_size
self.embedding = nn.Embedding(vocab_size, d_model)
def forward(self, x):
return self.embedding(x) * math.sqrt(self.d_model)解釋:
- nn.Embedding:將單詞索引轉換為大小為d_model的密集向量。
- 縮放因子sqrt(d_model):論文中使用此方法在訓練期間穩定梯度。
示例:
如果詞匯表大小為6(例如,詞元如[“Bye”, “Hello”等]),且d_model為512,embedding層將每個詞元映射到一個512維向量。
位置編碼
什么是位置編碼?
Transformer并行處理輸入序列,因此它們缺乏固有的順序概念(與RNN不同,RNN是順序處理詞元的)。位置編碼被添加到embedding中,以向模型提供詞元在序列中的相對或絕對位置信息。
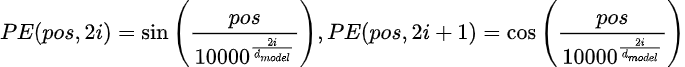
以下是位置編碼的代碼:
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, seq_len: int, dropout: float) -> None:
super().__init__()
self.d_model = d_model
self.seq_len = seq_len
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(seq_len, d_model)
position = torch.arange(0, seq_len).unsqueeze(1).float()
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + (self.pe[:, :x.shape[1], :]).requires_grad_(False)
return self.dropout(x)解釋:
- 正弦函數:編碼在偶數和奇數維度之間交替使用正弦和余弦函數。
- 為什么使用正弦函數?這些函數允許模型泛化到比訓練時更長的序列。
- register_buffer:確保位置編碼與模型一起保存,但在訓練期間不更新。
我們只需要計算一次位置編碼,然后為每個句子重復使用。
層歸一化
什么是層歸一化?
層歸一化是一種通過跨特征維度歸一化輸入來穩定和加速訓練的技術。它確保每個輸入向量的均值為0,方差為1。
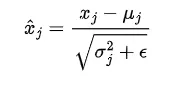
我們還引入了兩個參數,gamma(乘法)和beta(加法),它們會在數據中引入波動。網絡將學習調整這兩個可學習參數,以在需要時引入波動。
以下是代碼:
class LayerNormalization(nn.Module):
def __init__(self, eps: float = 1e-6) -> None:
super().__init__()
self.eps = eps
self.alpha = nn.Parameter(torch.ones(1))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
mean = x.mean(dim=-1, keepdim=True)
std = x.std(dim=-1, keepdim=True)
return self.alpha * (x - mean) / (std + self.eps) + self.bias解釋:
- alpha和bias:可學習參數,用于縮放和偏移歸一化后的輸出。
- eps:添加到分母中的小值,以防止除以零。
前饋塊
什么是前饋塊?
它是一個簡單的兩層神經網絡,獨立應用于序列中的每個位置。它幫助模型學習復雜的變換。以下是代碼:
class FeedForwardBlock(nn.Module):
def __init__(self, d_model: int, d_ff: int, dropout: float) -> None:
super().__init__()
self.linear_1 = nn.Linear(d_model, d_ff)
self.dropout = nn.Dropout(dropout)
self.linear_2 = nn.Linear(d_ff, d_model)
def forward(self, x):
return self.linear_2(self.dropout(torch.relu(self.linear_1(x))))解釋:
- 第一層線性層:將輸入維度從d_model擴展到d_ff,即512 → 2048。
- ReLU激活:增加非線性。
- 第二層線性層:投影回d_model。
多頭注意力
什么是注意力?
注意力機制允許模型在做出預測時關注輸入的相關部分。它計算值(V)的加權和,其中權重由查詢(Q)和鍵(K)之間的相似性決定。
什么是多頭注意力?
與計算單一注意力分數不同,多頭注意力將輸入分成多個“頭h”,以學習不同類型的關系。

注意力
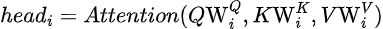
按頭計算的注意力
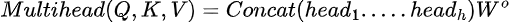
所有頭的注意力
- Q(查詢):代表當前單詞或詞元。
- K(鍵):代表序列中的所有單詞或詞元。
- V(值):代表與每個單詞或詞元相關的信息。
- Softmax:將相似性分數轉換為概率,使其總和為1。
- 縮放因子sqrt(d_k):防止點積變得過大,從而破壞softmax函數的穩定性。
每個頭計算自己的注意力,結果被拼接并投影回原始維度。以下是多頭注意力塊的代碼:
class MultiHeadAttentionBlock(nn.Module):
def __init__(self, d_model: int, h: int, dropout: float) -> None: # h is number of heads
super().__init__()
self.d_model = d_model
self.h = h
# Check if d_model is divisible by num_heads
assert d_model % h == 0, "d_model must be divisible by num_heads"
self.d_k = d_model // h
# Define matrices W_q, W_k, W_v , W_o
self.w_q = nn.Linear(d_model, d_model) # W_q
self.w_k = nn.Linear(d_model, d_model) # W_k
self.w_v = nn.Linear(d_model, d_model) # W_v
self.w_o = nn.Linear(d_model, d_model) # W_o
self.dropout = nn.Dropout(dropout)
@staticmethod
def attention(query, key, value, d_k, mask=None, dropout=nn.Dropout):
# Compute attention scores
attention_scores = (query @ key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
attention_scores.masked_fill(mask == 0, -1e9) # Mask padding tokens
attention_scores = torch.softmax(attention_scores, dim=-1)
if dropout is not None:
attention_scores = dropout(attention_scores)
return (attention_scores @ value), attention_scores
def forward(self, q, k, v, mask):
# Compute Q, K, V
query = self.w_q(q)
key = self.w_k(k)
value = self.w_v(v)
# Split into multiple heads
query = query.view(query.shape[0], query.shape[1], self.h, self.d_k).transpose(1, 2)
key = key.view(key.shape[0], key.shape[1], self.h, self.d_k).transpose(1, 2)
value = value.view(value.shape[0], value.shape[1], self.h, self.d_k).transpose(1, 2)
# Compute attention
x, self.attention_scores = MultiHeadAttentionBlock.attention(query, key, value, self.d_k, mask, self.dropout)
# Concatenate heads
x = x.transpose(1, 2).contiguous().view(x.shape[0], -1, self.h * self.d_k)
# Final linear projection
return self.w_o(x)解釋:
- 線性層(W_q, W_k, W_v):這些層將輸入轉換為查詢、鍵和值。
- 分割成頭:輸入被分割成h個頭,每個頭的維度較小(d_k = d_model / h)。
- 拼接:所有頭的輸出被拼接,并使用w_o投影回原始維度。
示例:
如果d_model=512且h=8,每個頭的維度為d_k=64。輸入被分割成8個頭,每個頭獨立計算注意力。結果被拼接回一個512維向量。
殘差連接和層歸一化
什么是殘差連接?
殘差連接將層的輸入添加到其輸出中。這有助于防止“梯度消失”問題。以下是殘差連接的代碼:
class ResidualConnection(nn.Module):
def __init__(self, dropout: float) -> None:
super().__init__()
self.dropout = nn.Dropout(dropout)
self.norm = LayerNormalization()
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))解釋:
- x:層的輸入。
- sublayer:表示層的函數(如注意力或前饋塊)。
- 輸出是輸入和子層輸出的和,隨后進行dropout。
1. 編碼器塊
編碼器塊結合了我們迄今為止討論的所有組件:多頭注意力、前饋塊、殘差連接和層歸一化。以下是編碼器塊的代碼:
class EncoderBlock(nn.Module):
def __init__(self, self_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout: float) -> None:
super().__init__()
self.self_attention_block = self_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(2)])
def forward(self, x, src_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, src_mask))
x = self.residual_connections[1](x, self.feed_forward_block)
return x解釋:
- 自注意力:輸入對自身進行注意力計算,以捕捉詞元之間的關系。
- 前饋塊:對每個詞元應用全連接網絡。
- 殘差連接:將輸入添加回每個子層的輸出。
2. 解碼器塊
解碼器塊與編碼器塊類似,但包含一個額外的交叉注意力層。這使得解碼器能夠關注編碼器的輸出。以下是解碼器塊的代碼:
class DecoderBlock(nn.Module):
def __init__(self, self_attention_block: MultiHeadAttentionBlock, cross_attention_block: MultiHeadAttentionBlock, feed_forward_block: FeedForwardBlock, dropout: float) -> None:
super().__init__()
self.self_attention_block = self_attention_block
self.cross_attention_block = cross_attention_block
self.feed_forward_block = feed_forward_block
self.residual_connections = nn.ModuleList([ResidualConnection(dropout) for _ in range(3)])
def forward(self, x, encoder_output, src_mask, tgt_mask):
x = self.residual_connections[0](x, lambda x: self.self_attention_block(x, x, x, tgt_mask))
x = self.residual_connections[1](x, lambda x: self.cross_attention_block(x, encoder_output, encoder_output, src_mask))
x = self.residual_connections[2](x, self.feed_forward_block)
return x解釋:
- 自注意力:解碼器對其自身輸出進行注意力計算。
- 交叉注意力:解碼器對編碼器的輸出進行注意力計算。
- 前饋塊:對每個詞元應用全連接網絡。
3. 最終線性層
該層將解碼器的輸出投影到詞匯表大小,將embedding為每個單詞的概率。該層將包含一個線性層和一個softmax層。這里使用log_softmax以避免下溢并使此步驟在數值上更穩定。以下是最終線性層的代碼:
class ProjectionLayer(nn.Module):
def __init__(self, d_model: int, vocab_size: int) -> None:
super().__init__()
self.proj = nn.Linear(d_model, vocab_size)
def forward(self, x):
return torch.log_softmax(self.proj(x), dim=-1)解釋:
- 輸入:解碼器的輸出(形狀:[batch, seq_len, d_model])。
- 輸出:詞匯表中每個單詞的對數概率(形狀:[batch, seq_len, vocab_size])。
Transformer模型
Transformer將所有內容結合在一起:編碼器、解碼器、embedding、位置編碼和投影層。以下是代碼:
class Transformer(nn.Module):
def __init__(self, encoder: Encoder, decoder: Decoder, src_embed: InputEmbedding, tgt_embed: InputEmbedding, src_pos: PositionalEncoding, tgt_pos: PositionalEncoding, projection_layer: ProjectionLayer) -> None:
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.src_pos = src_pos
self.tgt_pos = tgt_pos
self.projection_layer = projection_layer
def encode(self, src, src_mask):
src = self.src_embed(src)
src = self.src_pos(src)
return self.encoder(src, src_mask)
def decode(self, encoder_output, tgt, src_mask, tgt_mask):
tgt = self.tgt_embed(tgt)
tgt = self.tgt_pos(tgt)
return self.decoder(tgt, encoder_output, src_mask, tgt_mask)
def project(self, decoder_output):
return self.projection_layer(decoder_output)最終構建函數塊
最后一個塊是一個輔助函數,通過組合我們迄今為止看到的所有組件來構建整個Transformer模型。它允許我們指定論文中使用的超參數。以下是代碼:
def build_transformer(src_vocab_size: int, tgt_vocab_size: int, src_seq_len: int, tgt_seq_len: int,
d_model: int = 512, N: int = 6, h: int = 8, dropout: float = 0.1, d_ff: int = 2048) -> Transformer:
# Create the embedding layers for source and target
src_embed = InputEmbedding(d_model, src_vocab_size)
tgt_embed = InputEmbedding(d_model, tgt_vocab_size)
# Create positional encoding layers for source and target
src_pos = PositionalEncoding(d_model, src_seq_len, dropout)
tgt_pos = PositionalEncoding(d_model, tgt_seq_len, dropout)
# Create the encoder blocks
encoder_blocks = []
for _ in range(N):
encoder_self_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
feed_forward_block = FeedForwardBlock(d_model, d_ff, dropout)
encoder_block = EncoderBlock(encoder_self_attention_block, feed_forward_block, dropout)
encoder_blocks.append(encoder_block)
# Create the decoder blocks
decoder_blocks = []
for _ in range(N):
decoder_self_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
decoder_cross_attention_block = MultiHeadAttentionBlock(d_model, h, dropout)
feed_forward_block = FeedForwardBlock(d_model, d_ff, dropout)
decoder_block = DecoderBlock(decoder_self_attention_block, decoder_cross_attention_block, feed_forward_block, dropout)
decoder_blocks.append(decoder_block)
# Create the encoder and decoder
encoder = Encoder(nn.ModuleList(encoder_blocks))
decoder = Decoder(nn.ModuleList(decoder_blocks))
# Create the projection layer
projection_layer = ProjectionLayer(d_model, tgt_vocab_size)
# Create the Transformer model
transformer = Transformer(encoder, decoder, src_embed, tgt_embed, src_pos, tgt_pos, projection_layer)
# Initialize the parameters using Xavier initialization
for p in transformer.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return transformer該函數接受以下超參數作為輸入:
- src_vocab_size:源詞匯表的大小(源語言中唯一詞元的數量)。
- tgt_vocab_size:目標詞匯表的大小(目標語言中唯一詞元的數量)。
- src_seq_len:源輸入的最大序列長度。
- tgt_seq_len:目標輸入的最大序列長度。
- d_model:模型的維度(默認:512)。
- N:編碼器和解碼器塊的數量(默認:6)。
- h:多頭注意力機制中的注意力頭數量(默認:8)。
- dropout:防止過擬合的dropout率(默認:0.1)。
- d_ff:前饋網絡的維度(默認:2048)。
我們可以使用此函數創建具有所需超參數的Transformer模型。例如:
src_vocab_size = 10000
tgt_vocab_size = 10000
src_seq_len = 50
tgt_seq_len = 50
transformer = build_transformer(src_vocab_size, tgt_vocab_size, src_seq_len, tgt_seq_len)總結 — “Attention is All You Need” 核心貢獻
- 并行化:RNN按順序處理單詞,而Transformer并行處理整個句子。這大大減少了訓練時間。
- 多功能性:注意力機制可以適應各種任務,如翻譯、文本分類、問答、計算機視覺、語音識別等。
- 為基礎模型鋪路:該架構為BERT、GPT和T5等大規模語言模型鋪平了道路。