Transformer 模型結(jié)構(gòu)詳解及代碼實現(xiàn)!
一、Transformer簡要發(fā)展史
以下是Transformer模型發(fā)展歷史中的關(guān)鍵節(jié)點:

Transformer架構(gòu)于2017年6月推出。原本研究的重點是翻譯任務(wù)。隨后推出了幾個有影響力的模型,包括:
時間 | 模型 | 簡要說明 |
2017 年 6 月 | 「Transformer」 | Google 首次提出基于 Attention 的模型,用于機器翻譯任務(wù) |
2018 年 6 月 | 「GPT」 | 第一個使用 Transformer 解碼器模塊進行預(yù)訓(xùn)練的語言模型,適用于多種 NLP 任務(wù) |
2018 年 10 月 | 「BERT」 | 使用 Transformer 編碼器模塊,通過掩碼語言建模生成更強大的句子表示 |
2019 年 2 月 | 「GPT-2」 | 更大更強的 GPT 版本,由于潛在風(fēng)險未立即發(fā)布,具備出色的文本生成能力 |
2019 年 10 月 | 「DistilBERT」 | BERT 的輕量化版本,在保留 97% 性能的同時,速度更快、內(nèi)存占用更低 |
2019 年 10 月 | 「BART、T5」 | 使用完整的 Encoder-Decoder 架構(gòu),在各種 NLP 任務(wù)中表現(xiàn)優(yōu)異 |
2020 年 5 月 | 「GPT-3」 | 超大規(guī)模語言模型,支持“零樣本學(xué)習(xí)”,無需微調(diào)即可完成新任務(wù) |
這個列表并不全面,只是為了突出一些不同類型的 Transformer 模型。大體上,它們可以分為三類:
類別 | 構(gòu)成 | 特點 | 典型模型 |
「GPT-like」 (自回歸 Transformer) | 只使用解碼器 | 自回歸方式預(yù)測下一個詞,適合文本生成任務(wù) | GPT、GPT-2、GPT-3 |
「BERT-like」 (自動編碼 Transformer) | 只使用編碼器 | 掩碼機制學(xué)習(xí)上下文表示,適合理解類任務(wù)如問答、情感分析 | BERT、RoBERTa、DistilBERT |
「BART/T5-like」 (序列到序列 Transformer) | 編碼器 + 解碼器 | 完整的 encoder-decoder 架構(gòu),適合翻譯、摘要等生成+理解結(jié)合的任務(wù) | BART、T5 |
Transformer 默認都是大模型,除了一些特例(如 DistilBERT)外,實現(xiàn)更好性能的一般策略是增加模型的大小以及預(yù)訓(xùn)練的數(shù)據(jù)量。其中,GPT-2 是使用「transformer 解碼器模塊」構(gòu)建的,而 BERT 則是通過「transformer 編碼器」模塊構(gòu)建的。

二、Transformer 整體架構(gòu)
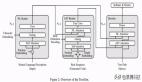
論文中給出用于中英文翻譯任務(wù)的 Transformer 整體架構(gòu)如下圖所示:

可以看出Transformer架構(gòu)由Encoder和Decoder兩個部分組成:其中Encoder和Decoder都是由N=6個相同的層堆疊而成。Multi-Head Attention 結(jié)構(gòu)是 Transformer 架構(gòu)的核心結(jié)構(gòu),其由多個 Self-Attention 組成的。其中,
部件 | 結(jié)構(gòu) | 層數(shù) | 主要模塊 |
Encoder | 編碼器層堆疊 | N=6層 | Self-Attention+Feed Forward |
Decoder | 解碼器層堆疊 | N=6層 | Self-Attention+Encoder-Decoder Attention+Feed Forward |
Transformer 架構(gòu)更詳細的可視化圖如下所示:

1. 輸入模塊
(1) Tokenizer預(yù)處理
在基于Transformer的大模型LLM中,輸入通常為字符串文本。由于模型無法直接處理自然語言,因此需要借助Tokenizer對輸入進行預(yù)處理。具體流程如下:
- 分詞(Tokenization):將輸入文本按規(guī)則切分為一個個詞元(token),如單詞、子詞或特殊符號。
- 詞表映射(Vocabulary Mapping):每個 token 被映射到一個唯一的整數(shù) ID,該 ID 來自預(yù)訓(xùn)練模型所使用的詞匯表。
- 生成 input_ids 向量(矩陣):最終輸出是一個由 token ID 構(gòu)成的向量(或矩陣),作為模型輸入。
以下是以 Hugging Face 的 transformers 庫為例,展示如何使用 BertTokenizer 和 BertModel 完成輸入文本的預(yù)處理和編碼:
from transformers import BertTokenizer, BertModel
import torch
# 1. 加載預(yù)訓(xùn)練的 BERT tokenizer 和模型
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 2. 輸入文本
text = "A Titan RTX has 24GB of VRAM"
# 3. 分詞并映射為 token ID 序列
inputs = tokenizer(text, return_tensors="pt", truncatinotallow=True, padding=True)
# 輸出 token IDs
print("Token IDs:", inputs['input_ids'])
# 4. 傳入模型,獲取輸出
outputs = model(**inputs)
# 5. 獲取最后一層的隱藏狀態(tài)表示
last_hidden_states = outputs.last_hidden_state
print("Last hidden states shape:", last_hidden_states.shape)原始輸入文本 "A Titan RTX has 24GB of VRAM" 通過 tokenizer 完成分詞和詞表映射工作,生成的輸入 ID 列表:
[101, 138, 28318, 56898, 12674, 10393, 10233, 32469, 10108, 74727, 36535, 102]其中,
- 101 表示 [CLS] 標記;
- 102 表示 [SEP] 標記;
- 其余為對應(yīng) token 在詞表中的索引。
在所有基于 Transformer 的 LLM 中,唯一必須的輸入是 input_ids,它是由 Tokenizer 映射后的 token 索引組成的整數(shù)向量,代表了輸入文本在詞表中的位置信息。
(2) Embedding 層
在基于 Transformer 的大型語言模型(LLM)中,嵌入層(Embedding Layer)是將輸入 token ID 映射為向量表示的核心組件。其作用是將離散的整數(shù)索引轉(zhuǎn)換為連續(xù)、稠密的向量空間表示,從而便于后續(xù)神經(jīng)網(wǎng)絡(luò)進行語義建模。
? 萬物皆可 Embedding:雖然最常見的是詞嵌入(Word Embedding),但圖像、語音等也可以通過嵌入層映射為向量形式,實現(xiàn)統(tǒng)一建模。
例如,mnist 數(shù)據(jù)集中的圖片,可以通過嵌入層來表示,如下圖所示,每個點代表一個圖片(10000*784),通過嵌入層,將圖片的像素點轉(zhuǎn)化為稠密的向量,然后通過 t-SNE/pca 降維,可以看到圖片的空間分布。

LLM 中,單詞 token 需要經(jīng)過 Embedding 層,Embedding 層的作用是將輸入的離散化表示(例如 token ids)轉(zhuǎn)換為連續(xù)的低維向量表示,其由單詞 Embedding 和位置 Embedding (Positional Encoding)相加得到,通常定義為 TransformerEmbedding 層。
① 單詞嵌入(Token Embedding)」
自然語言處理中,輸入文本通常是以符號形式存在的詞匯,而這些離散符號無法直接被神經(jīng)網(wǎng)絡(luò)處理。因此需要一個可學(xué)習(xí)的嵌入矩陣將每個 token 轉(zhuǎn)換為固定維度的向量。
工作原理:
a. 輸入是一個形狀為 [batch_size, seq_len] 的整數(shù)張量,表示每個 token 在詞表中的索引;
b. 輸出是一個形狀為 [batch_size, seq_len, d_model] 的三維張量,其中:
- d_model 是嵌入維度(如 512 或 768);
- 每個 token 對應(yīng)一個 d_model 維的向量;
c. 嵌入層權(quán)重矩陣大小為 [vocab_size, d_model],參數(shù)量為:
在 PyTorch 中,詞嵌入層通常使用 torch.nn.Embedding 模塊實現(xiàn),其作用是將 token 的索引轉(zhuǎn)換為低維語義向量表示。
? 輸入與輸出說明
類型 | 描述 |
輸入 | 一個整數(shù)張量,表示每個 token 在詞表中的索引 |
輸入形狀 | (batch_size, sequence_length) |
輸出 | 每個 token 被映射到 embedding_dim 維度的稠密向量 |
輸出形狀 | (batch_size, sequence_length, embedding_dim) |
- embedding_dim 是嵌入向量的維度,也稱為詞向量維度;
- 它通常被設(shè)置為 d_model 或 h,即后續(xù) Transformer 層使用的隱藏層維度(如 512 或 768).
?? 示例代碼:構(gòu)建 Token Embedding 層
from transformers import BertTokenizer
import torch.nn as nn
## 1, 使用 BERT tokenizer 將批量輸入的字符串文本序列轉(zhuǎn)化為 input_ids
tokenizer = BertTokenizer.from_pretrained("bert-base-multilingual-cased")
batch_text = ["A Titan RTX has 24GB of VRAM", "I have a dog and cat"]
inputs = tokenizer(batch_text, return_tensors="pt", truncation=True, padding=True)
input_ids = inputs["input_ids"]
# 2. 創(chuàng)建一個 nn.Embedding 層
vocab_size = tokenizer.vocab_size # 詞表大小取決于你加載的具體 tokenizer 模型
embedding_dim = 512 # 嵌入向量的維度,參考 transformer 論文的大小
embedding_layer = nn.Embedding(vocab_size, embedding_dim)
# 3. 通過 nn.Embedding 層,將輸入的 IDs 映射到嵌入向量
embedded_output = embedding_layer(input_ids)
# 4. 輸出嵌入向量的形狀
print("嵌入向量的形狀:", embedded_output.shape) # (batch_size, sequence_length, embedding_dim), torch.Size([2, 12, 512])
# 5. 打印嵌入向量
print(embedded_output)程序運行后輸出結(jié)果如下所示:

② 位置嵌入(Positional Encoding)」
由于 Transformer 不依賴于 RNN 的順序性建模方式,它必須顯式地引入位置信息,以保留 token 在序列中的位置特征。
為此,Transformer 使用了 Sinusoidal Positional Encoding(正弦/余弦位置編碼):

其中:
- pos:token 在序列中的位置;
- i:維度索引;
- d_model:嵌入維度。
③ TransformerEmbedding 層集成
transformer 輸入模塊有三個組成部分:文本/提示詞、分詞器(Tokenizer)和嵌入層(Embeddings)。輸入模塊的工作流程和代碼實現(xiàn)如下所示:

矩陣的每一列表示一個 token 的嵌入向量。
class PositionalEncoding(nn.Module):
"""
compute sinusoid encoding.
"""
def __init__(self, d_model, max_len, device):
"""
constructor of sinusoid encoding class
:param d_model: dimension of model
:param max_len: max sequence length
:param device: hardware device setting
"""
super(PositionalEncoding, self).__init__()
# same size with input matrix (for adding with input matrix)
self.encoding = torch.zeros(max_len, d_model, device=device)
self.encoding.requires_grad = False # we don't need to compute gradient
pos = torch.arange(0, max_len, device=device)
pos = pos.float().unsqueeze(dim=1)
# 1D => 2D unsqueeze to represent word's position
_2i = torch.arange(0, d_model, step=2, device=device).float()
# 'i' means index of d_model (e.g. embedding size = 50, 'i' = [0,50])
# "step=2" means 'i' multiplied with two (same with 2 * i)
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / d_model)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model)))
# compute positional encoding to consider positional information of words
def forward(self, x):
# self.encoding
# [max_len = 512, d_model = 512]
batch_size, seq_len = x.size()
# [batch_size = 128, seq_len = 30]
return self.encoding[:seq_len, :]
# [seq_len = 30, d_model = 512]
# it will add with tok_emb : [128, 30, 512]
class TokenEmbedding(nn.Embedding):
"""
Token Embedding using torch.nn
they will dense representation of word using weighted matrix
"""
def __init__(self, vocab_size, d_model):
"""
class for token embedding that included positional information
:param vocab_size: size of vocabulary
:param d_model: dimensions of model
"""
super(TokenEmbedding, self).__init__(vocab_size, d_model, padding_idx=1)
class TransformerEmbedding(nn.Module):
"""
token embedding + positional encoding (sinusoid)
positional encoding can give positional information to network
"""
def __init__(self, vocab_size, max_len, d_model, drop_prob, device):
"""
class for word embedding that included positional information
:param vocab_size: size of vocabulary
:param d_model: dimensions of model
"""
super(TransformerEmbedding, self).__init__()
self.tok_emb = TokenEmbedding(vocab_size, d_model)
# self.position_embedding = nn.Embedding(max_len, embed_size)
self.pos_emb = PositionalEncoding(d_model, max_len, device)
self.drop_out = nn.Dropout(p=drop_prob)
def forward(self, x):
tok_emb = self.tok_emb(x)
pos_emb = self.pos_emb(x)
return self.drop_out(tok_emb + pos_emb)2. Multi-Head Attention 結(jié)構(gòu)
Encoder 和 Decoder 結(jié)構(gòu)中公共的 layer 之一是 Multi-Head Attention,其是由多個 Self-Attention 并行組成的。Encoder block 只包含一個 Multi-Head Attention,而 Decoder block 包含兩個 Multi-Head Attention (其中有一個用到 Masked)。

(1) Self-Attention 結(jié)構(gòu)
Self-Attention 中文翻譯為自注意力機制,論文中叫作 Scale Dot Product Attention,它是 Transformer 架構(gòu)的核心,使得每個 token 能夠關(guān)注整個序列中的其他 token,從而建立全局依賴關(guān)系。其結(jié)構(gòu)如下圖所示:

? 在本文中,Self-Attention 層與論文中的 ScaleDotProductAttention 層意義一致,實現(xiàn)方式完全相同。
?? 數(shù)學(xué)定義
Self-Attention 的計算過程可以表示為:

其中:
 :Query 向量;
:Query 向量; :Key 向量;
:Key 向量; :Value 向量;
:Value 向量; :Query 和 Key 的維度;
:Query 和 Key 的維度;- Softmax 對注意力分數(shù)按最后一個維度歸一化;
 :用于縮放點積,防止 softmax 梯度消失;
:用于縮放點積,防止 softmax 梯度消失;
輸入來源:
- 輸入詞向量經(jīng)過 Embedding 層后,進入位置編碼層;
- 再通過線性變換(Linear 層),分別生成 Query、Key 和 Value 向量;
- 這三個向量的形狀通常為 [batch_size, seq_len, d_k] 或 [seq_len, d_k]。
計算步驟如下:
① 計算注意力分數(shù)矩陣

- 其中
 是 Key 張量的轉(zhuǎn)置;
是 Key 張量的轉(zhuǎn)置; - 點積結(jié)果是一個 [seq_len, seq_len] 的注意力得分矩陣;
- 使用 softmax 歸一化,得到注意力權(quán)重。
② 應(yīng)用掩碼(可選)
- 在 Decoder 中使用 Masked Self-Attention,防止未來信息泄露;
- 若傳入 mask,將對應(yīng)位置設(shè)為極小值(如 -1e9)以抑制其影響。
③ 加權(quán)聚合 Value 向量
- 將 softmax 后的注意力權(quán)重與 Value 相乘,得到上下文感知的輸出張量;
- 輸出維度保持與輸入一致:[batch_size, seq_len, d_v]。
?? 代碼實現(xiàn):
import torch
import math
import torch.nn as nn
class ScaleDotProductAttention(nn.Module):
def __init__(self):
"""
初始化 Self-Attention 層,僅包含一個 softmax 操作。
"""
super(ScaleDotProductAttention, self).__init__()
self.softmax = nn.Softmax(dim=-1)
def forward(self, Q: torch.Tensor, K: torch.Tensor, V: torch.Tensor, mask: torch.Tensor = None):
"""
Self-Attention 前向傳播函數(shù)
:param Q: Query 向量,形狀為 [batch_size, seq_len, d_k]
:param K: Key 向量,形狀為 [batch_size, seq_len, d_k]
:param V: Value 向量,形狀為 [batch_size, seq_len, d_v]
:param mask: 掩碼張量,形狀為 [batch_size, seq_len, seq_len]
:return:
output: 加權(quán)后的 Value 向量,形狀為 [batch_size, seq_len, d_v]
attn_weights: 注意力權(quán)重矩陣,形狀為 [batch_size, seq_len, seq_len]
"""
# 1. 計算 QK^T 得到注意力分數(shù)
K_T = K.transpose(-1, -2) # [batch_size, d_k, seq_len]
scores = torch.matmul(Q, K_T) / math.sqrt(Q.size(-1)) # [batch_size, seq_len, seq_len]
# 2. 如果有 mask,應(yīng)用掩碼(例如 Decoder 中防止看到未來詞)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 3. 應(yīng)用 softmax 得到注意力權(quán)重
attn_weights = self.softmax(scores) # [batch_size, seq_len, seq_len]
# 4. 權(quán)重 × Value 得到最終輸出
output = torch.matmul(attn_weights, V) # [batch_size, seq_len, d_v]
return output, attn_weights?? 示例調(diào)用與輸出解析:
# 創(chuàng)建 Q、K、V 張量
Q = torch.randn(5, 10, 64) # [batch_size=5, seq_len=10, d_k=64]
K = torch.randn(5, 10, 64)
V = torch.randn(5, 10, 64)
# 創(chuàng)建 Self-Attention 層
attention = ScaleDotProductAttention()
# 前向傳播
output, attn_weights = attention(Q, K, V)
# 打印輸出形狀
print(f"ScaleDotProductAttention output shape: {output.shape}") # [5, 10, 64]
print(f"attn_weights shape: {attn_weights.shape}") # [5, 10, 10]變量 | 形狀 | 描述 |
Q, K, V | [5, 10, 64] | batch=5,序列長度=10,嵌入維度=64 |
scores | [5, 10, 10] | 注意力得分矩陣,反映 token 之間的相似度 |
attn_weights | [5, 10, 10] | softmax 后的注意力權(quán)重,用于加權(quán)聚合 Value |
output | [5, 10, 64] | 最終輸出,融合了上下文信息的 Value 加權(quán)表示 |
(3) Multi-Head Attention
Multi-Head Attention(MHA)是在Self-Attention基礎(chǔ)上引入的一種增強機制。其核心理念是:將輸入向量空間劃分為多個子空間,在每個子空間中獨立計算Self-Attention,最后將多個子空間的輸出拼接在一起并進行線性變換,從而得到最終的輸出。
對于 MHA,之所以需要對 Q、K、V 進行多頭(head)劃分,其目的是為了增強模型對不同信息的關(guān)注。具體來說,多組 Q、K、V 分別計算 Self-Attention,每個頭自然就會有獨立的 Q、K、V 參數(shù),從而讓模型同時關(guān)注多個不同的信息,這有些類似 CNN 架構(gòu)模型的多通道機制。
下圖是論文中 Multi-Head Attention 的結(jié)構(gòu)圖。

從圖中可以看出, MHA 結(jié)構(gòu)的計算過程可總結(jié)為下述步驟:
- 將輸入 Q、K、V 張量進行線性變換(Linear 層),輸出張量尺寸為 [batch_size, seq_len, d_model];
- 將前面步驟輸出的張量,按照頭的數(shù)量(n_head)拆分為 n_head 子張量,其尺寸為 [batch_size, n_head, seq_len, d_model//n_head];
- 每個子張量并行計算注意力分數(shù),即執(zhí)行 dot-product attention 層,輸出張量尺寸為 [batch_size, n_head, seq_len, d_model//n_head];
- 將這些子張量進行拼接 concat ,并經(jīng)過線性變換得到最終的輸出張量,尺寸為 [batch_size, seq_len, d_model]。
?? 數(shù)學(xué)表達式

其中:

 :第 i 個 head 的可學(xué)習(xí)參數(shù);
:第 i 個 head 的可學(xué)習(xí)參數(shù); :最終輸出的線性變換矩陣;
:最終輸出的線性變換矩陣;- Concat表示將各個 head 的輸出拼接在一起。
(4) Multi-Head Attention 實現(xiàn)
import torch
import math
import torch.nn as nn
class MultiHeadAttention(nn.Module):
"""Multi-Head Attention Layer"""
def __init__(self, d_model, n_head):
"""
Args:
d_model: 模型嵌入維度(通常為 512 或 768);
n_head: 注意力頭的數(shù)量(如 8);
"""
super(MultiHeadAttention, self).__init__()
# 初始化參數(shù)
self.n_head = n_head
self.attention = ScaleDotProductAttention() # 使用前面定義的 Self-Attention
# 線性變換層
self.w_q = nn.Linear(d_model, d_model) # Query 變換
self.w_k = nn.Linear(d_model, d_model) # Key 變換
self.w_v = nn.Linear(d_model, d_model) # Value 變換
self.fc = nn.Linear(d_model, d_model) # 輸出投影層
def forward(self, q, k, v, mask=None):
"""
Args:
q: Query 張量,[batch_size, seq_len, d_model]
k: Key 張量,[batch_size, seq_len, d_model]
v: Value 張量,[batch_size, seq_len, d_model]
mask: 掩碼張量,[batch_size, seq_len, seq_len]
"""
# Step 1: 線性變換
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
# Step 2: 拆分到多個 head
q = self.split(q) # [batch_size, n_head, seq_len, d_tensor]
k = self.split(k) # [batch_size, n_head, seq_len, d_tensor]
v = self.split(v) # [batch_size, n_head, seq_len, d_tensor]
# Step 3: 計算每個 head 的 attention
sa_output, attn_weights = self.attention(q, k, v, mask)
# Step 4: 拼接所有 head 的輸出
mha_output = self.concat(sa_output) # [batch_size, seq_len, d_model]
# Step 5: 最終線性變換
mha_output = self.fc(mha_output)
return mha_output, attn_weights
def split(self, tensor):
"""
拆分輸入張量為多個 head
Args:
tensor: [batch_size, seq_len, d_model]
Returns:
[batch_size, n_head, seq_len, d_tensor]
"""
batch_size, seq_len, d_model = tensor.size()
d_tensor = d_model // self.n_head # 每個 head 的維度
# reshape + transpose 實現(xiàn)拆分
tensor = tensor.view(batch_size, seq_len, self.n_head, d_tensor)
tensor = tensor.transpose(1, 2) # [batch_size, n_head, seq_len, d_tensor]
return tensor
def concat(self, sa_output):
"""
拼接多個 head 的輸出
Args:
sa_output: [batch_size, n_head, seq_len, d_tensor]
Returns:
[batch_size, seq_len, d_model]
"""
batch_size, n_head, seq_len, d_tensor = sa_output.size()
d_model = n_head * d_tensor
# transpose + reshape 實現(xiàn)合并
sa_output = sa_output.transpose(1, 2).contiguous().view(batch_size, seq_len, d_model)
return sa_output?? 示例調(diào)用與輸出解析:
# 定義參數(shù)
d_model = 512
n_head = 8
seq_len = 10
batch_size = 32
# 創(chuàng)建 Q、K、V 張量
Q = torch.randn(batch_size, seq_len, d_model)
K = torch.randn(batch_size, seq_len, d_model)
V = torch.randn(batch_size, seq_len, d_model)
# 構(gòu)建 MHA 層
mha_layer = MultiHeadAttention(d_model=d_model, n_head=n_head)
# 前向傳播
output, weights = mha_layer(Q, K, V)
# 打印輸出形狀
print("MHA Output Shape:", output.shape) # [32, 10, 512]
print("Attn Weights Shape:", weights.shape) # [32, 8, 10, 10]變量 | 形狀 | 描述 |
Q, K, V | [32, 10, 512] | 輸入張量,表示 batch=32,seq_len=10,d_model=512 |
q, k, v | [32, 8, 10, 64] | 拆分后的 Q/K/V,每個 head 64 維 |
sa_output | [32, 8, 10, 64] | 每個 head 的 attention 輸出 |
mha_output | [32, 10, 512] | 拼接后的最終輸出 |
attn_weights | [32, 8, 10, 10] | 每個 head 的注意力權(quán)重矩陣 |
3. Encoder結(jié)構(gòu)
Transformer 中的 Encoder 是整個模型中用于編碼輸入序列的部分。它由 N=6 個相同的 encoder block 堆疊而成。每個 encoder block 主要包含兩個子層(sub-layers):多頭自注意力機制(Multi-Head Self-Attention)和位置全連接前饋網(wǎng)絡(luò)(Position-wise Feed Forward Network)。
這兩個子層之間都使用了 殘差連接(Residual Connection) 和 層歸一化(Layer Normalization),以增強訓(xùn)練穩(wěn)定性和模型表達能力。
下圖中紅色框選部分表示一個標準的 Encoder Block,其內(nèi)部結(jié)構(gòu)如下:

由以下四個關(guān)鍵部分構(gòu)成。
模塊 | 描述 |
Multi-Head Attention | 使用多個 attention head 并行提取序列中的不同特征 |
Add & Norm (1) | 殘差連接(Residual Connection)+ 層歸一化(LayerNorm) |
Position-wise FeedForward | 兩層線性變換 + 激活函數(shù),對每個詞獨立建模 |
Add & Norm (2) | 同樣應(yīng)用殘差連接和 LayerNorm |
(1) 每一層的計算流程(以單個 encoder block 為例)
① 多頭自注意力機制(Multi-Head Self-Attention)
- 輸入:嵌入后的張量

- 輸出:通過自注意力加權(quán)后的新張量 sa_output
sa_output, attn_weights = MultiHeadAttention(q=x, k=x, v=x, mask=src_mask)其中,
- Query、Key 和 Value 來自同一個輸入 ;
- 可選 mask 通常用于屏蔽 padding token 或控制位置感知范圍。
② 殘差連接 + 層歸一化(Sublayer 1)
x = x + dropout(sa_output)
x = layer_norm(x)- 應(yīng)用殘差映射,緩解梯度消失問題;
- 使用 LayerNorm 對每個 token 的向量進行標準化處理;
- 整體目標:提升模型表達能力與訓(xùn)練穩(wěn)定性。
③ 位置全連接前饋網(wǎng)絡(luò)(Position-wise FeedForward)
定義為:

nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model),
nn.Dropout(drop_prob)
)- d_model:模型隱層維度(如 512);
- d_ff:FeedForward 網(wǎng)絡(luò)中間維度(如 2048);
- ReLU 導(dǎo)致非線性更強的語義表達。
④ 再次殘差連接 + 層歸一化(Sublayer 2)
x = x + dropout(ffn_output)
x = layer_norm(x)- 保證模型在經(jīng)過復(fù)雜變換后仍能保留原始信息;
- 達成對上下文感知表示的穩(wěn)定學(xué)習(xí)。
(2) 維度變化說明(輸入輸出保持一致)
無論經(jīng)過多少層 Encoder block,每個 block 的輸入與輸出形狀始終一致:
張量 | 形狀 | 描述 |
輸入 | [batch_size, seq_len, d_model] | 批次大小 × 序列長度 × 模型維度 |
MHA 輸出 | [batch_size, seq_len, d_model] | 注意力加權(quán)后的輸出 |
FFN 輸出 | [batch_size, seq_len, d_model] | 每個 Token 的前饋網(wǎng)絡(luò)輸出 |
最終輸出 | [batch_size, seq_len, d_model] | 經(jīng)過兩次 Sublayer 后仍然保持相同維度 |
(3) PyTorch 模塊封裝示例
import torch
import torch.nn as nn
class EncoderBlock(nn.Module):
def __init__(self, d_model, n_head, d_ff, drop_prob=0.1):
"""
Args:
d_model: 嵌入維度(例如 512)
n_head: 多頭數(shù)量(通常設(shè)為 8)
d_ff: Feed Forward 網(wǎng)絡(luò)中間維度(通常為 2048)
drop_prob: Dropout 概率
"""
super(EncoderBlock, self).__init__()
self.attention = MultiHeadAttention(d_model, n_head)
self.norm1 = nn.LayerNorm(d_model)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.ReLU(),
nn.Linear(d_ff, d_model),
nn.Dropout(drop_prob)
)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(drop_prob)
def forward(self, x, src_mask=None):
# Step 1: Multi-Head Self-Attention
sa_output, _ = self.attention(x, x, x, src_mask)
x = self.norm1(x + self.dropout(sa_output))
# Step 2: Position-wise FeedForward
ffn_output = self.ffn(x)
x = self.norm2(x + self.dropout(ffn_output))
return x(4) 封裝整個 Encoder 模塊
有了 EncoderBlock 后,我們可以將它 重復(fù) N 次 構(gòu)建完整的 Encoder:
class TransformerEncoder(nn.Module):
def __init__(self, num_layers, d_model, n_head, d_ff, drop_prob=0.1):
"""
Args:
num_layers: encoder block 堆疊層數(shù)(原論文為 6)
d_model: 模型維度(如 512)
n_head: 注意力頭數(shù)(如 8)
d_ff: FeedForward 網(wǎng)絡(luò)維度(如 2048)
"""
super(TransformerEncoder, self).__init__()
self.blocks = nn.ModuleList([
EncoderBlock(d_model, n_head, d_ff, drop_prob)
for _ in range(num_layers)
])
def forward(self, x, mask=None):
for block in self.blocks:
x = block(x, mask)
return x?? 示例調(diào)用
# 創(chuàng)建輸入張量
x = torch.randn(batch_size=32, seq_len=20, d_model=512) # [32, 20, 512]
# 構(gòu)建 Encoder
encoder = TransformerEncoder(num_layers=6, d_model=512, n_head=8, d_ff=2048)
output = encoder(x)
print("Encoder 輸出形狀:", output.shape) # [32, 20, 512]4. Decoder結(jié)構(gòu)
Decoder是Transformer架構(gòu)中用于生成輸出序列的部分。與Encoder類似,它由N=6個相同的Decoder block堆疊而成,但結(jié)構(gòu)更為復(fù)雜。
(1) Decoder Block 的核心組件
一個標準的Decoder block包含三個主要子層:
- Masked Multi-Head Self-Attention
- Encoder-Decoder Attention
- Position-wise Feed Forward Network
每個子層后面都跟隨 殘差連接(Residual Connection) 和 層歸一化(Layer Normalization)。
如下圖右側(cè)紅框表示一個標準的 Decoder Block。

①「Masked Multi-Head Self-Attention」
這是Decoder的第一個注意力機制,用于處理目標語言的輸入序列(即解碼器自身的輸入)。
- 使用 masking 技術(shù) 防止在預(yù)測當前詞時看到未來的詞,保持因果關(guān)系。
- 實現(xiàn)方式:通過 trg_mask 屏蔽未來信息。
x = self.mha1(q=dec_out, k=dec_out, v=dec_out, mask=trg_mask)②「Encoder-Decoder Attention」
這是 Decoder 的第二個注意力機制,用于將 Encoder 的輸出信息融合到 Decoder 中。
- Query (Q) 來自上一層 Decoder 的輸出;
- Key (K) 和 Value (V) 來自 Encoder 的輸出;
- 這樣 Decoder 在生成每個詞時都能關(guān)注到整個輸入句子的信息。
x = self.mha2(q=x, k=enc_out, v=enc_out, mask=src_mask)③ 「Position-wise Feed Forward Network」
這是一個簡單的兩層全連接網(wǎng)絡(luò),對每個位置的向量進行非線性變換。
x = self.ffn(x)④「殘差連接 + 層歸一化(Add & Norm)」
每個子層都應(yīng)用:
x = self.ln(x_residual + dropout(sublayer_output))- 提升訓(xùn)練穩(wěn)定性;
- 緩解梯度消失問題。
⑤「Decoder的完整實現(xiàn)」
DecoderLayer類:
class DecoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(DecoderLayer, self).__init__()
# 第一個 Multi-Head Attention: Masked Self-Attention
self.mha1 = MultiHeadAttention(d_model, n_head)
self.ln1 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
# 第二個 Multi-Head Attention: Encoder-Decoder Attention
self.mha2 = MultiHeadAttention(d_model, n_head)
self.ln2 = nn.LayerNorm(d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
# 前饋網(wǎng)絡(luò)
self.ffn = PositionwiseFeedForward(d_model, ffn_hidden)
self.ln3 = nn.LayerNorm(d_model)
self.dropout3 = nn.Dropout(p=drop_prob)
def forward(self, dec_out, enc_out, trg_mask, src_mask):
x_residual1 = dec_out
# Step 1: Masked Self-Attention
x = self.mha1(q=dec_out, k=dec_out, v=dec_out, mask=trg_mask)
x = self.ln1(x_residual1 + self.dropout1(x))
if enc_out is not None:
# Step 2: Encoder-Decoder Attention
x_residual2 = x
x = self.mha2(q=x, k=enc_out, v=enc_out, mask=src_mask)
x = self.ln2(x_residual2 + self.dropout2(x))
# Step 3: Position-wise Feed Forward
x_residual3 = x
x = self.ffn(x)
x = self.ln3(x_residual3 + self.dropout3(x))
return xDecoder 類:
class Decoder(nn.Module):
def __init__(self, dec_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
# 輸入嵌入 + 位置編碼
self.emb = TransformerEmbedding(
d_model=d_model,
drop_prob=drop_prob,
max_len=max_len,
vocab_size=dec_voc_size,
device=device
)
# 堆疊多個 Decoder Layer
self.layers = nn.ModuleList([
DecoderLayer(
d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob
) for _ in range(n_layers)
])
# 最終輸出層:映射到目標詞匯表大小
self.linear = nn.Linear(d_model, dec_voc_size)
def forward(self, trg, src, trg_mask, src_mask):
# trg: 目標序列 [batch_size, trg_seq_len]
# src: Encoder 輸出 [batch_size, src_seq_len, d_model]
trg = self.emb(trg)
for layer in self.layers:
trg = layer(trg, src, trg_mask, src_mask)
# 輸出:[batch_size, trg_seq_len, dec_voc_size]
output = self.linear(trg)
return output三、Transformer實現(xiàn)
基于前面實現(xiàn)的 Encoder 和 Decoder 組件,我們就可以實現(xiàn) Transformer 模型的完整代碼,如下所示:
import torch
from torch import nn
class Transformer(nn.Module):
def __init__(self, src_pad_idx, trg_pad_idx, trg_sos_idx, enc_voc_size, dec_voc_size,
d_model, n_head, max_len, ffn_hidden, n_layers, drop_prob, device):
super().__init__()
# 保存特殊標記的索引
self.src_pad_idx = src_pad_idx # 源語言填充索引
self.trg_pad_idx = trg_pad_idx # 目標語言填充索引
self.trg_sos_idx = trg_sos_idx # 目標語言起始符號索引
self.device = device # 設(shè)備信息
# 構(gòu)建 Encoder
self.encoder = Encoder(
d_model=d_model, # 模型維度
n_head=n_head, # 注意力頭數(shù)量
max_len=max_len, # 最大序列長度
ffn_hidden=ffn_hidden, # 前饋網(wǎng)絡(luò)隱藏層維度
enc_voc_size=enc_voc_size, # 源語言詞匯表大小
drop_prob=drop_prob, # Dropout 概率
n_layers=n_layers, # Encoder 層數(shù)
device=device # 設(shè)備信息
)
# 構(gòu)建 Decoder
self.decoder = Decoder(
d_model=d_model, # 模型維度
n_head=n_head, # 注意力頭數(shù)量
max_len=max_len, # 最大序列長度
ffn_hidden=ffn_hidden, # 前饋網(wǎng)絡(luò)隱藏層維度
dec_voc_size=dec_voc_size, # 目標語言詞匯表大小
drop_prob=drop_prob, # Dropout 概率
n_layers=n_layers, # Decoder 層數(shù)
device=device # 設(shè)備信息
)
def forward(self, src, trg):
# 創(chuàng)建源序列的 padding mask
src_mask = self.make_pad_mask(src, src, self.src_pad_idx, self.src_pad_idx)
# 創(chuàng)建目標序列到源序列的 mask
src_trg_mask = self.make_pad_mask(trg, src, self.trg_pad_idx, self.src_pad_idx)
# 創(chuàng)建目標序列的 padding mask 和因果mask的組合
trg_mask = self.make_pad_mask(trg, trg, self.trg_pad_idx, self.trg_pad_idx) * \
self.make_no_peak_mask(trg, trg)
# 編碼器前向傳播
enc_src = self.encoder(src, src_mask)
# 解碼器前向傳播
output = self.decoder(trg, enc_src, trg_mask, src_trg_mask)
return output
def make_pad_mask(self, q, k, q_pad_idx, k_pad_idx):
# 獲取輸入序列長度
len_q, len_k = q.size(1), k.size(1)
# 創(chuàng)建針對 key 的 mask
# batch_size x 1 x 1 x len_k
k_mask = k.ne(k_pad_idx).unsqueeze(1).unsqueeze(2)
# batch_size x 1 x len_q x len_k
k_mask = k_mask.repeat(1, 1, len_q, 1)
# 創(chuàng)建針對 query 的 mask
# batch_size x 1 x len_q x 1
q_mask = q.ne(q_pad_idx).unsqueeze(1).unsqueeze(3)
# batch_size x 1 x len_q x len_k
q_mask = q_mask.repeat(1, 1, 1, len_k)
# 組合兩個 mask
mask = k_mask & q_mask
return mask
def make_no_peak_mask(self, q, k):
# 創(chuàng)建因果mask,防止解碼器看到未來信息
len_q, len_k = q.size(1), k.size(1)
# 創(chuàng)建下三角矩陣,保證解碼器只能關(guān)注當前詞及之前的詞
mask = torch.tril(torch.ones(len_q, len_k)).type(torch.BoolTensor).to(self.device)
return mask