













作者 | 崔皓
審校 | 重樓
摘要
TAG(Table-Augmented Generation)模型通過結合關系型數據庫的精準計算能力和大語言模型的語義推理能力,為復雜的自然語言查詢提供了高效解決方案。TAG 的核心流程分為查詢合成、查詢執行和答案生成三步,能夠靈活處理多數據源的交互式查詢任務。通過引入語言模型,TAG 不僅可以執行傳統 SQL 查詢,還能在情感分析、趨勢總結等語義推理任務中展現卓越性能。本文詳細解析了 TAG 的功能和機制,同時引入 LOTUS 系統作為其具體實現,展示了如何通過模塊化語義操作符進一步優化數據查詢效率與推理能力。
什么是 TAG
在現代商業和數據分析場景中,許多重要的信息都存儲在關系型數據庫中,用戶需要通過自然語言查詢來獲取反饋。例如,一個零售經理可能會問:“過去一個月,某個商品類別的銷售趨勢是什么?”或者“客戶對新產品的評價有哪些共性?”這些問題的答案不僅需要從數據庫中提取相關信息,還需要進一步結合上下文進行語義推理和總結。
為了解決這些復雜的問題,Table-Augmented Generation (TAG) 應運而生。TAG 模型不僅能夠高效處理結構化數據,還通過引入語言模型實現語義推理和復雜的多步推斷。這一特性使 TAG 成為解決復雜查詢的強大工具。
TAG 模型通過三個主要步驟——查詢合成(Query Synthesis)、查詢執行(Query Execution)和答案生成(Answer Generation)——結合了語言模型(LM)和數據庫系統的優點。例如,在電商分析場景中,TAG 可以從多個數據源提取銷售記錄,結合時間信息進行趨勢分析,并進一步利用語言模型總結出關鍵洞察,例如“本月銷售額增長的主要原因是某爆款商品的熱銷”。
此外,在情感分析場景中,TAG 也展現了獨特的優勢。例如,用戶查詢“客戶對某產品的評價是正面還是負面?”時,TAG 能夠提取評價文本,結合語言模型進行情感分類,并生成總結,例如“90%的客戶反饋是正面的,主要提到產品的性價比和質量”。TAG 在處理多樣化的查詢時比傳統方法表現更好,尤其是在涉及到情感分析、趨勢總結等需要推理和通用知識的任務時,表現尤為突出。
為什么需要使用TAG
大家有沒有遇到過這種場景,用戶提出比較復雜的問題,而系統需要通過關系型數據庫進行搜索并給予反饋。比如“總結經典最賣座浪漫電影的評論”。我們需要搜索出最賣座的電影,然后找到該電影的評論信息(多條),最后將這些信息進行匯總形成摘要返回給用戶。基本思路是,在數據庫中進行多表查詢、匯總、聚合等操作,還需要配合大語言模型結合上下文給出答復。
其中最容易讓人想到的方式是,通過將自然語言請求轉化為數據庫查詢,執行查詢后返回相關結果。這種方式可以準確定位符合條件的數據記錄,但這種方式無法進一步總結或推理。這類功能背后的技術實現被稱為 Text2SQL,它將自然語言翻譯為 SQL 查詢語句并在數據庫中執行。然而,Text2SQL 的能力僅限于數據的直接檢索,對于更復雜的分析或多層次推理,它顯得力不從心。
另一種方法是通過語義檢索技術實現。這種方法將文本信息存儲在向量數據庫中,隨后通過相似度計算(如余弦相似度)來找到最相關的記錄。這一技術被稱為 RAG (Retrieval-Augmented Generation)。RAG 的優勢在于,它能夠結合語言模型生成自然語言答案,并通過向量檢索高效處理文本匹配問題。然而,當需要對來自多個數據表的信息進行聚合或復雜推理時,RAG 同樣面臨挑戰。
為了克服這些局限性,TAG (Table-Augmented Generation) 提供了更強大的解決方案,特別是在多數據源和跨表操作場景中展現了其獨特的優勢。TAG 不僅能夠像 Text2SQL 一樣將自然語言查詢轉化為 SQL 并高效執行,還可以靈活地處理來自多個表的數據關聯,同時引入語言模型的推理能力,進一步豐富查詢結果的語義表達。
例如,針對“總結經典最賣座浪漫電影的評論”這一請求,TAG 不僅能找到“泰坦尼克號”的相關評論,還能利用語言模型深入分析這些評論內容并生成總結,例如“泰坦尼克號的評論主要提到其出色的敘事和視覺效果”。通過結合數據庫的精確計算能力與語言模型的語義推理能力,TAG 成為處理復雜查詢和提供上下文豐富答案的最優選擇。
Text2SQL、RAG和TAG之間的區別
通過上面“浪漫電影”的例子,我們提到了三個技術,分別是:Text2SQL、RAG以及TAG,他們是AIGC發展不同時代的產物。下面,我們對他們進行一個橫向比較。
Text2SQL
它主要通過將自然語言查詢轉換為SQL查詢來執行,適用于那些有明確數據庫關系映射的查詢。它的問題很明顯,無法處理需要語義推理、情感分析或其他復雜推理的查詢。例如,無法理解用戶查詢中的隱含含義,如“哪些客戶對產品X的評價是正面的”。
RAG (Retrieval-Augmented Generation)
基于檢索的生成方法,它從外部數據庫中檢索與查詢相關的信息,然后通過LM生成答案。通常用于執行基于相關性簡單查找的任務。RAG只能處理點查找類問題,不能有效地進行數據聚合、復雜計算或多步推理。例如,無法處理“為什么我的銷售在這段時間下降”這樣的查詢,它涉及到復雜的數據匯總和推理。
TAG (Table-Augmented Generation)
TAG結合了Text2SQL和RAG的優點,通過三個主要步驟(查詢合成、查詢執行和答案生成)高效地回答自然語言查詢。其優勢比較明顯:
查詢合成:將用戶的自然語言查詢轉換為可執行的數據庫查詢(SQL)。
查詢執行:在數據庫中高效執行查詢,獲取相關數據。
答案生成:結合數據庫中的數據和語言模型生成最終的自然語言答案,進行復雜的推理和總結。
TAG的創新在于,除了處理傳統數據庫查詢(如SQL),它還能夠處理需要推理、推斷世界知識的查詢,適用于需要復雜推理和多層次數據交互的查詢。
我們將三者的區別整理為如下表格。
從表格可以看出,Text2SQL 的強項在于直接提取結構化數據,RAG 在文本相關性查找方面表現優異,而 TAG 通過結合 SQL 查詢和語言模型的語義推理能力,實現了前兩者無法完成的復雜查詢。TAG 特別適合需要跨表分析、數據聚合和復雜推理的場景,例如總結最經典的浪漫愛情電影評論,或分析客戶對新產品的綜合反饋。

TAG 的內部機制
TAG 系統在解決復雜自然語言查詢時,與傳統方法的處理流程有顯著不同,特別是在引入推理能力和豐富上下文答案方面表現卓越。
如下圖所示,TAG通過以下三個主要步驟, 實現了高效的自然語言查詢回答:
查詢合成(Query Synthesis): 首先,將用戶的自然語言請求轉換為可執行的數據庫查詢。與 Text2SQL 不同,TAG 不僅可以生成 SQL 查詢,還能夠合成結合多個數據源和類型的復雜查詢。例如,請注意以下示例:
用戶查詢“總結被認為是‘經典’的最賣座浪漫電影的評論”,TAG 將其翻譯為如下 SQL 查詢:
WITH CRM AS (SELECT * FROM movies WHERE genre = 'Romance'
AND LLM('{movie_title} is a classic') = 'True')
SELECT * FROM CRM
WHERE revenue = (SELECT MAX(revenue) FROM CRM);在此過程中,TAG 使用 LLM 調用 LLM('{movie_title} is a classic') = 'True' 來引入新的推理能力。這一步驟被稱為“增強”步驟,因為它擴展了 SQL 查詢的能力,讓其能夠結合數據庫之外的上下文信息(例如電影是否被認為是“經典”)。
查詢執行(Query Execution): 一旦查詢被合成,它就會在數據庫中高效執行。TAG 利用數據庫的計算能力來處理大規模數據檢索和精確計算,而這是語言模型難以直接執行的。
答案生成(Answer Generation): 在最后一步,AI 模型基于檢索到的數據生成上下文的答案。通過增強步驟提供的語義推理能力,TAG 能夠將上下文信息、通用知識以及特定領域的理解融入答案中,從而顯著提升回答的準確性和自然性。例如,TAG 在答案生成過程中,利用大語言模型的多層次推理能力,對檢索到的內容進行深度語義解析,并結合額外的上下文知識(如領域術語和用戶查詢背景)生成自然語言答案。
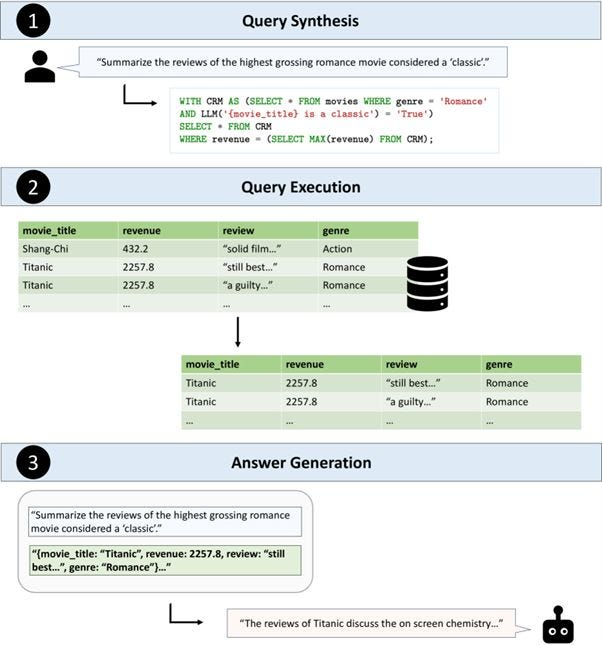
在上述示例中,TAG 系統可以總結返回的電影評論,生成答案如“泰坦尼克號的評論主要提到其出色的敘事和視覺效果”,而這種總結得益于語言模型對評論內容的多步推理與聚合分析能力。
下面讓我們近距離解析,TAG 處理自然語言查詢的三個步驟:
查詢合成(Query Synthesis)
查詢合成的核心是將用戶的自然語言請求轉化為數據庫可以執行的查詢 。這一過程包含兩個關鍵任務:
推斷相關數據:確定回答查詢所需的數據,例如從數據庫表的模式(schema)中推斷出相關字段。
語義解析:利用語言模型的語義推理能力,將自然語言請求轉化為可執行的查詢(例如 SQL)。
當用戶查詢:“總結最高票房的經典浪漫電影的評論”,系統生成的 SQL 查詢:結合了關系表字段(如 movie_title、review、revenue 和 genre),并利用語言模型過濾符合“經典”條件的記錄。
查詢執行(Query Execution)
查詢執行步驟的核心是利用數據庫引擎高效地執行生成的查詢 ,并返回相關數據表 。此步驟可以通過支持 LM(語言模型) 操作的數據庫 API 實現更復雜的計算和推理。在上述示例中,生成的 SQL 查詢首先過濾出浪漫電影,并通過 LM 判斷哪些電影屬于“經典”范疇,接著按票房排名找到最高票房的電影,并返回與該電影相關的評論數據表 。
答案生成(Answer Generation)
答案生成步驟通過語言模型的語義推理能力,根據用戶請求 和查詢結果數據 生成最終的自然語言答案 。
TAG 系統對返回的 (例如“泰坦尼克號”的評論數據)進行語義分析,總結評論內容,并生成自然語言答案,例如“泰坦尼克號的評論大多是積極的,觀眾對其敘事和視覺效果贊譽有加”。
TAG 的研究方向
除了上面對多表查詢方面的表現以外,TAG 模型在查詢類型、數據模型、執行引擎以及生成模式等多個方面都展現了獨特的優勢和擴展可能性。
首先,TAG 在查詢類型的多樣性上表現出色。它不僅能夠處理簡單的點查詢,比如用戶希望快速檢索單行或少量數據的任務,還能應對復雜的聚合查詢。例如,一個零售經理可能需要總結過去一個月內的銷售趨勢,這需要 TAG 在數據庫中整合多行數據并利用語言模型進行邏輯推理。此外,TAG 還能勝任情感分析和分類等需要語義推理的高級任務。
其次,TAG 的底層數據模型設計靈活,能夠適配多種數據類型。傳統的結構化數據,如關系型數據庫中的表格信息,能夠通過 TAG 得到高效處理。同時,TAG 還能處理半結構化和非結構化數據,比如自由文本、圖像、視頻和音頻,這為多模態數據的集成提供了可能性。這種靈活性讓 TAG 在多樣化的數據場景中都有應用空間。
TAG 的數據庫執行引擎支持多種實現方式,使其適用于不同的查詢需求。對于結構化數據,TAG 通過 SQL 查詢的生成和執行實現高效數據檢索。對于語義檢索場景,TAG 能夠將自然語言查詢轉化為向量嵌入,并通過相似性匹配實現高效數據查找。此外,TAG 還可以集成新興的增強型執行方法,比如語義操作符模型,它允許開發者在數據庫中直接執行復雜的語義過濾和排序操作。
在生成模式方面,TAG 提供了從簡單到復雜的多種實現選項。簡單的生成模式如單次語言模型調用,適用于快速回答的任務。而復雜的生成模式則通過多步迭代或遞歸的方式實現更深層次的推理和數據整合。例如,對于需要在多行數據中發現隱含關系的任務,TAG 能夠利用語言模型多次調用生成完整且語義豐富的答案。
TAG功能雖然強大,如果需要落地應用必須經過最佳實踐,于是就有了 LOTUS。LOTUS 構建在 TAG 的理論基礎之上,進一步優化了查詢執行的效率,并提供了類似 Pandas 的直觀 API,使開發者可以通過聲明式的語義操作符快速實現復雜的數據查詢任務。LOTUS 還通過模塊化設計支持擴展,能夠集成不同的數據源和多種 AI 模型,從而為復雜自然語言查詢提供了更加高效的解決方案。
LOTUS:基于LLM的數據查詢引擎
LOTUS 是一個結合了結構化和非結構化數據處理能力的查詢引擎,它讓基于大語言模型(LLM)的數據處理變得快速且簡單。
基本介紹
LOTUS(LLMs Over Tables of Unstructured and Structured Data)提供了一種聲明式編程模型和優化的查詢引擎,可以針對結構化和非結構化數據構建強大的基于推理的查詢管道。LOTUS 通過類似 Pandas 的簡單直觀 API 實現語義操作符,簡化了開發人員編寫 AI 驅動查詢的復雜性。
基本概念
LOTUS 的核心是語義操作符(Semantic Operator)編程模型:
- 語義操作符:對一個或多個數據集進行聲明式轉換,這些轉換通過自然語言表達式參數化,并可由多種 AI 算法實現。
- 擴展關系模型:語義操作符能夠對包含傳統結構化數據和非結構化字段(如自由文本)的表操作。
- 模塊化與組合性:操作符支持編寫高級邏輯的 AI 管道,查詢引擎負責高效執行。
LOTUS 支持的主要語義操作符包括:
- sem_map:將每條記錄映射為基于自然語言描述的屬性。例如,可以將商品描述轉換為更具體的類別標簽,例如將“iPhone 13”映射為“智能手機”。
- sem_filter:篩選符合自然語言謂詞的記錄。例如,篩選出所有“價格大于100元且評分高于4星”的商品,通過語言模型解析謂詞條件進行精確篩選。
- sem_agg:對所有記錄進行聚合,例如總結出“所有商品的平均價格”和“評分最高的商品”。
- sem_topk:根據自然語言指定的排序規則選出前K條記錄。例如,“找出評分最高的前5個商品”。
- sem_join:基于自然語言謂詞連接兩個數據集。例如,將訂單數據與用戶數據通過自然語言謂詞“匹配下單金額大于500元的用戶及其訂單”進行跨表關聯。
- sem_sim_join:基于語義相似性連接兩個數據集。例如,將一列文章標題與另一列新聞摘要通過內容相似度進行匹配。
- sem_search:在文本列中執行語義搜索。例如,“在評論列中查找提到‘服務很好’的所有記錄”。
支持模型
LOTUS 支持以下三種主要模型類別:
LM(語言模型):
基于 LiteLLM 庫構建,支持所有 LiteLLM 支持的模型(如 OpenAI、Ollama 和 vLLM)。
可參考 LiteLLM 文檔了解更多使用示例。
RM(檢索模型):
使用 SentenceTransformers 提供的模型進行語義檢索。
可通過 SentenceTransformersRM 類加載任意模型。
Reranker(重排序模型):
使用 SentenceTransformers 提供的 CrossEncoder 模型進行語義重排序。
安裝指南
要安裝 LOTUS,請按照以下步驟操作:
創建 Conda 環境:
conda create -n lotus python=3.10 -y
conda activate lotus使用 pip 安裝 LOTUS:
pip install lotus-ai如果在 Mac 上運行,請通過 Conda 安裝 FAISS:
僅 CPU 版本:
conda install -c pytorch faiss-cpu=1.8.0GPU (+CPU) 版本:
conda install -c pytorch -c nvidia faiss-gpu=1.8.0通過上述步驟,你即可快速搭建 LOTUS 環境,為后續的代碼開發和測試做好準備。
LOTUS 的模塊化設計使得它能夠靈活支持各種應用場景,并為復雜自然語言查詢提供了高效解決方案。
示例代碼與解釋
以下代碼展示了 LOTUS 的一個簡單用例,通過 sem_join 操作實現課程和技能的語義匹配。用戶通過自然語言定義查詢邏輯,LOTUS 結合語言模型執行查詢,最終返回結果。
import pandas as pd
import lotus
from lotus.models import LM
# configure the LM, and remember to export your API key
lm = LM(model="gpt-4o-mini")
lotus.settings.configure(lm=lm)
# create dataframes with course names and skills
courses_data = {
"Course Name": [
"History of the Atlantic World",
"Riemannian Geometry",
"Operating Systems",
"Food Science",
"Compilers",
"Intro to computer science",
]
}
skills_data = {"Skill": ["Math", "Computer Science"]}
courses_df = pd.DataFrame(courses_data)
skills_df = pd.DataFrame(skills_data)
# lotus sem join
res = courses_df.sem_join(skills_df, "Taking {Course Name} will help me learn {Skill}")
print(res)
# Print total LM usage
lm.print_total_usage()我們將上述代碼代碼進行詳細拆解如下:
初始化環境和數據:
import pandas as pd
courses_data = {
"Course Name": [
"History of the Atlantic World",
"Riemannian Geometry",
"Operating Systems",
"Food Science",
"Compilers",
"Intro to computer science",
]
}
skills_data = {"Skill": ["Math", "Computer Science"]}
courses_df = pd.DataFrame(courses_data)
skills_df = pd.DataFrame(skills_data)
print("Courses DataFrame:")
print(courses_df)
print("\nSkills DataFrame:")
print(skills_df)配置 gpt-4o-mini 作為語言模型。創建兩個數據框 courses_df 和 skills_df,分別包含課程名稱和技能。courses_df 包含課程名稱,這些課程可能涉及到多個領域。skills_df 列出了技能名稱,這些技能對應課程的學習目標。數據框為后續的語義連接操作提供了清晰的輸入。兩個集合的對象"Course Name"和"Skill" 會在后面的代碼中進行語義關聯。
語義連接操作:
from lotus.models import LM
import lotus
# 配置語言模型
lm = LM(model="gpt-4o-mini")
lotus.settings.configure(lm=lm)
# 語義連接
res = courses_df.sem_join(skills_df, "Taking {Course Name} will help me learn {Skill}")
print("\nResult of Semantic Join:")
print(res)sem_join 操作基于自然語言模板,通過語言模型解析 Course Name 和 Skill 之間的語義關系。這里通過”{}” 包括兩個數據集中的對象,用來表示需要處理具體對象的語義關系。想判斷課程(Course Name)與技能(Skill)之間的關系,“History of the Atlantic World” 是否與“Math”匹配由語言模型判斷。
執行上述代碼得到如下結果:

清楚地看到課程(Course Name)與技能(Skill)之間的關系。Sem_join是LOTUS眾多操作之中的一種,它的功能就是將兩個不同數據集的數據進行關聯。通過執行過程我們發現它也遵循TAG的三個步驟:
查詢合成(Query Synthesis):
自然語言模板定義了匹配邏輯(如 "Taking {Course Name} will help me learn {Skill}")。
查詢執行(Query Execution):
LOTUS 的 sem_join 調用語言模型完成語義匹配,并返回匹配結果。
答案生成(Answer Generation):
匹配結果以 Pandas 數據框形式返回,便于進一步分析和使用。
深入源代碼
由于好奇sem_join 功能是如何實現的,我們通過Github查看了對應的源碼。

通過分析,sem_join 的功能主要通過以下五個步驟實現,每個步驟對應不同的核心函數和邏輯。
第一步:輸入數據的準備與轉換
首先,sem_join 接收兩個輸入數據序列(l1 和 l2),并將它們轉換為多模態信息,為后續的語義處理提供基礎。
代碼中使用了 task_instructions.df2multimodal_info 函數,將輸入的 Pandas Series 轉換為模型可處理的格式:
left_multimodal_data = task_instructions.df2multimodal_info(l1.to_frame(col1_label), [col1_label])
right_multimodal_data = task_instructions.df2multimodal_info(l2.to_frame(col2_label), [col2_label])這一步的主要作用是將數據框的列名與具體的上下文綁定,為語言模型生成語義匹配提供豐富的背景信息。
第二步:構造語義連接任務
通過自然語言模板描述連接邏輯,例如 "Taking {Course Name} will help me learn {Skill}",并將其傳遞給語言模型進行解析和處理。
在代碼中,模板被注入到語義過濾器中,通過調用
task_instructions.merge_multimodal_info 函數合并多模態數據:
modified_docs = task_instructions.merge_multimodal_info([i1], right_multimodal_data)合并后的數據被傳遞給語言模型,用于執行語義匹配任務。
第三步:語義過濾與模型推理
語義過濾是 sem_join 的核心部分。通過調用 sem_filter 函數,sem_join 利用語言模型對數據對進行語義推理,判斷哪些記錄匹配。
語義過濾的核心代碼如下:
output = sem_filter(
modified_docs,
model,
user_instruction,
examples_multimodal_data=examples_multimodal_data,
examples_answers=examples_answers,
cot_reasoning=cot_reasoning,
default=default,
strategy=strategy,
show_progress_bar=False,
)模型的輸出包括匹配結果、原始輸出和解釋信息,為最終的連接結果提供依據。
第四步:結果組合與優化
在語義過濾的基礎上,sem_join 將所有匹配記錄整合為一個結果集合。對于高置信度和低置信度的匹配記錄,系統通過優化策略減少模型調用次數,提升運行效率。
結果組合部分的代碼如下:
join_results.extend(
[
(id1, ids2[i], explanation)
for i, (output, explanation) in enumerate(zip(outputs, explanations))
if output
]
)優化邏輯通過函數 join_optimizer 實現,選擇成本最低的連接計劃,進一步提升連接效率。
第五步:輸出結果與分析
最后,sem_join 將語義連接的結果封裝為 SemanticJoinOutput 對象,包含匹配記錄、過濾結果、模型原始輸出和解釋信息。用戶可以通過返回的數據框進一步分析連接結果。
返回結果的代碼如下:
return SemanticJoinOutput(
join_results=join_results,
filter_outputs=filter_outputs,
all_raw_outputs=all_raw_outputs,
all_explanations=all_explanations,
)總結
TAG 模型的出現填補了傳統數據查詢技術與現代語義推理需求之間的空白。通過結合 SQL 查詢和大語言模型,TAG 在復雜查詢、推理和結果生成方面展現了強大的能力。本文不僅分析了 TAG 的理論基礎,還通過 LOTUS 系統的實例演示了其實際應用潛力。LOTUS 的模塊化設計和直觀 API 為開發者實現復雜語義查詢提供了便利工具,表明 TAG 和 LOTUS 在多數據源、跨領域數據分析中的重要地位和廣闊前景。
作者介紹
崔皓,51CTO社區編輯,資深架構師,擁有18年的軟件開發和架構經驗,10年分布式架構經驗。


















