PyTorch vs PyTorch Lightning 框架對比
在不斷發展的深度學習領域,PyTorch 已經成為開發者和研究人員家喻戶曉的名字。其動態計算圖、靈活性以及廣泛的社區支持使其成為構建從簡單神經網絡到復雜前沿模型的首選框架。然而,靈活性也帶來了編寫大量樣板代碼的責任——尤其是在訓練循環、日志記錄和分布式學習方面。這就是 PyTorch Lightning 的用武之地,它提供了一個結構化的高級接口,自動化了許多底層細節。

在本文中,我們將深入探討普通 PyTorch 和 PyTorch Lightning 之間的區別,通過實際示例突出它們的關鍵差異,并探討每種方法如何適應您的工作流程。我們還將包括一個比較訓練流程的流程圖、相關引文以供深入研究,以及一些有用的視頻鏈接,以便您可以在這兩個框架之間進行有指導的探索。
一、背景:PyTorch 基礎
在比較 PyTorch 和 PyTorch Lightning 之前,有必要回顧一下 PyTorch 最初吸引人的地方。
1. 動態計算圖
PyTorch 使用動態計算圖,這意味著圖是即時生成的,使開發者能夠編寫感覺更自然、更直觀的 Python 代碼,便于調試。在早期框架(如 TensorFlow 的早期版本)中,您必須在運行之前定義一個靜態圖,這在處理動態輸入或特殊架構時引入了復雜性。
2. Pythonic API
PyTorch 與 Python 深度集成。這種協同作用使其特別適合開發者,因為您可以利用原生 Python 功能和調試工具。代碼流暢,使實驗變得簡單直接。
3. 精細控制
能力越大,責任越大。在普通的 PyTorch 中,您需要負責編寫訓練循環、更新權重(優化器、調度器)、將數據移動到設備上或從設備上移出,并自行處理任何特殊的日志記錄或回調。如果您想要精細控制或正在構建高度專業化的研究模型,這是理想的選擇。
二、介紹 PyTorch Lightning
PyTorch Lightning 旨在減少樣板代碼并促進最佳實踐,通常被描述為 PyTorch 上的輕量級封裝。它沒有重新發明輪子,而是專注于簡化訓練過程:
- 減少樣板代碼:您不再需要從頭編寫訓練循環;PyTorch Lightning Trainer 會處理它。
- 強制執行結構:鼓勵采用模塊化方法構建神經網絡。您定義一個包含模型架構、training_step、validation_step 和其他步驟(如果需要)的 LightningModule。
- 內置功能:內置日志記錄(通過 Lightning 的日志記錄器)、分布式訓練支持、檢查點、早停等。
PyTorch Lightning 不會限制您,而是保留了 PyTorch 的底層靈活性。如果您需要深入研究,可以覆蓋方法或合并自定義邏輯,而不會失去框架結構的好處。
三、一對一差異
1. 訓練循環與樣板代碼
PyTorch:
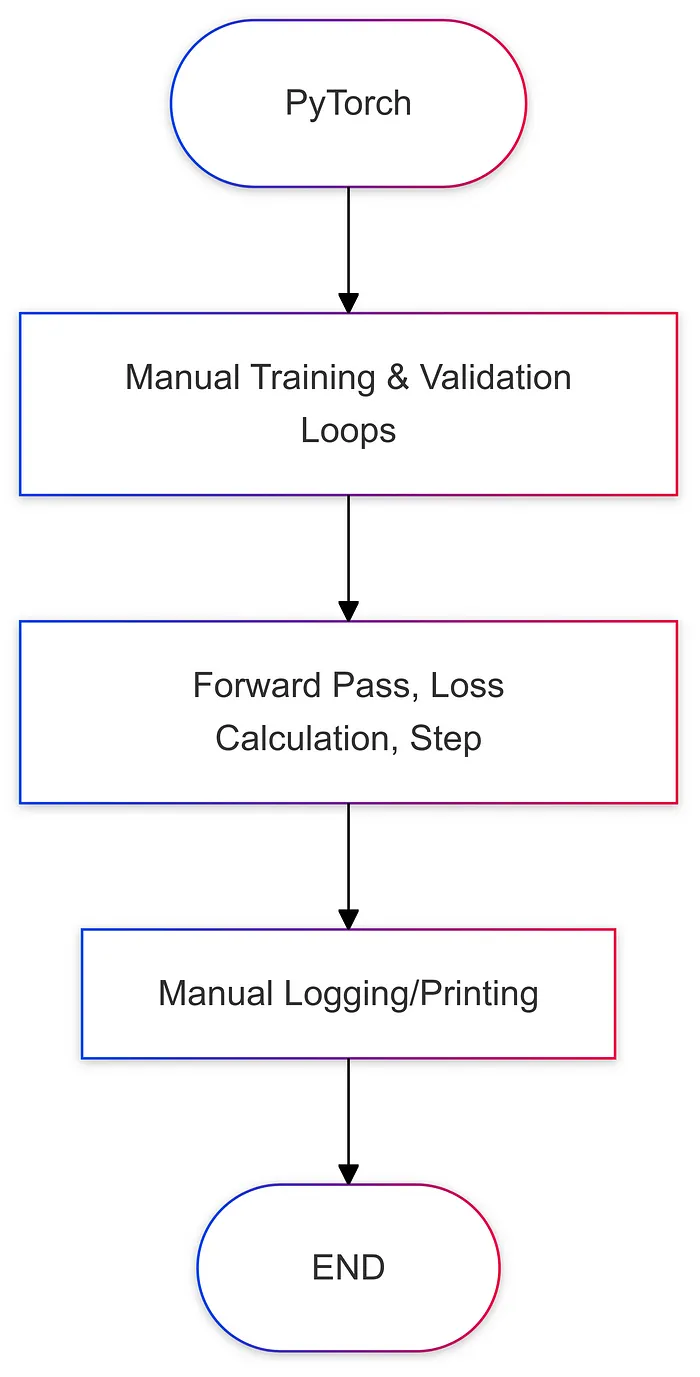
- 您需要手動編寫訓練、驗證和測試循環。
- 您必須跟蹤批次迭代、前向傳播、反向傳播、優化器和日志記錄(如果需要)。
PyTorch Lightning:
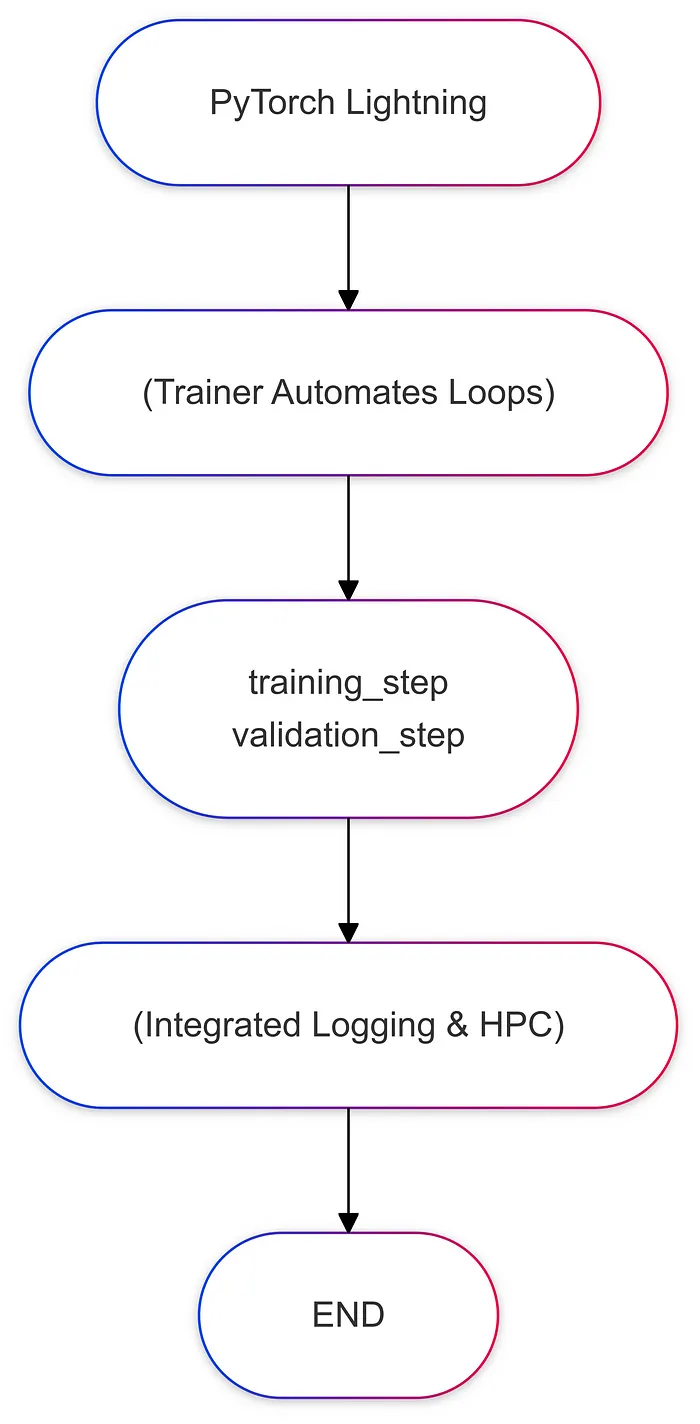
- 可以在 LightningModule 中實現 training_step()、validation_step() 和 configure_optimizers() 等方法。
- Trainer 負責協調循環,在后臺調用這些方法,并抽象出重復的部分(例如,for batch in train_loader: ...)。
優勢:在 Lightning 中,您可以專注于邏輯(如何訓練)而不是腳手架(在哪里放置循環、如何記錄日志等)。
2. 日志記錄與實驗跟蹤
PyTorch:
- 通常通過自定義解決方案完成:tensorboardX、日志記錄庫或手動打印語句。
- 您需要編寫代碼來保存指標、寫入日志或生成 TensorBoard 可視化。
PyTorch Lightning:
- 集成日志記錄器:TensorBoard、Comet、MLflow、Neptune 等。
- 簡單的調用如 self.log('train_loss', loss, on_step=True) 在后臺處理指標記錄。
- 內置檢查點,根據驗證指標自動保存最佳或最新模型。
優勢:日志記錄和檢查點幾乎自動化,鼓勵更好的可重復性。
3. 分布式與多 GPU 支持
PyTorch:
- 需要 nn.DataParallel 或更高級的方法如 DistributedDataParallel。
- 您必須仔細處理設備分配、批次分割和同步。
PyTorch Lightning:
- 通過單個參數啟動多進程或多 GPU 訓練(例如,Trainer(gpus=2, accelerator='gpu'))。
- Lightning 管理分布式采樣、梯度同步等。
優勢:它簡化了 HPC(高性能計算)或多 GPU 使用,讓您專注于模型而不是并行化的細節。
4. 代碼組織
PyTorch:
- 靈活,但如果不強制執行一致的代碼結構,可能會變得混亂。
- 典型的模式是將模型定義放在一個文件中,訓練邏輯放在另一個文件中,但您可以自由選擇。
PyTorch Lightning:
- 強制執行最佳實踐結構:一個類用于 LightningModule,一個類用于數據模塊或數據加載器,一個 Trainer 用于協調運行。
- 這可以在生產場景中創建更易維護的代碼。
四、實踐示例
為了更好地說明,讓我們考慮一個在虛擬數據集上的簡單前饋網絡。我們將看一個最小的 PyTorch 方法,然后是 PyTorch Lightning 中的等效方法。雖然以下代碼片段是簡化的,但它們展示了代碼結構的典型差異。
1. PyTorch 中的最小訓練循環
import torch
import torch.nn as nn
import torch.optim as optim
# dataset (features, labels)
X = torch.randn(100, 10)
y = torch.randint(0, 2, (100,))
# Simple feedforward model
model = nn.Sequential(
nn.Linear(10, 16),
nn.ReLU(),
nn.Linear(16, 2)
)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
# Training loop
epochs = 5
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(X)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
# Validation step (just a demonstration - not a separate set)
with torch.no_grad():
val_outputs = model(X)
val_loss = criterion(val_outputs, y)
# Logging
print(f"Epoch: {epoch+1}, Train Loss: {loss.item():.4f}, Val Loss: {val_loss.item():.4f}")關鍵點:
- 手動清零梯度、計算前向傳播、反向傳播和記錄日志。
- 如果要分離訓練集和驗證集,必須添加額外的代碼。
- 除非自己編寫代碼,否則沒有內置的檢查點或高級功能。
2. PyTorch Lightning 中的等效訓練
import torch
import torch.nn as nn
import torch.optim as optim
import pytorch_lightning as pl
from torch.utils.data import TensorDataset, DataLoader
class SimpleModel(pl.LightningModule):
def __init__(self):
super(SimpleModel, self).__init__()
self.model = nn.Sequential(
nn.Linear(10, 16),
nn.ReLU(),
nn.Linear(16, 2)
)
self.criterion = nn.CrossEntropyLoss()
def forward(self, x):
return self.model(x)
def training_step(self, batch, batch_idx):
X, y = batch
outputs = self.forward(X)
loss = self.criterion(outputs, y)
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
X, y = batch
outputs = self.forward(X)
loss = self.criterion(outputs, y)
self.log("val_loss", loss)
def configure_optimizers(self):
return optim.Adam(self.parameters(), lr=1e-3)關鍵點:
- 沒有手動循環 epoch,也沒有手動清零梯度。
- 分離的 training_step 和 validation_step。
- 日志記錄通過 self.log("train_loss", loss) 自動完成,并與 Lightning 的系統集成。
五、流程圖比較
以下是每個框架中訓練流程的簡化圖示:
六、最佳實踐與使用場景
1. 何時堅持使用普通 PyTorch
研究原型:如果您正在試驗全新的架構,可能會頻繁更改訓練循環。
完全控制:您需要做一些高度定制的事情,比如每次迭代修改梯度更新或實現可能不適合 Lightning 回調結構的奇特優化程序。
2. 何時使用 PyTorch Lightning
生產與團隊項目:如果您需要一致、可讀的代碼以便多個開發者加入。
分布式訓練或多 GPU:Lightning 大大減少了多 GPU 或多節點訓練的開銷。
快速實驗:如果您重視以最少的樣板代碼、集成日志記錄和易于調試的速度構建實驗。
3. 混合方法
這并不總是一個二選一的決定。一些團隊在普通 PyTorch 中構建原型,然后將穩定的代碼遷移到 Lightning 以用于生產。如果您需要部分自動化和部分自定義邏輯,也可以通過覆蓋某些鉤子在 Lightning 中編寫自定義循環。
七、結論
在 PyTorch 和 PyTorch Lightning 之間做出選擇最終取決于您對靈活性與自動化的重視程度。PyTorch 提供了無與倫比的控制水平,非常適合前沿研究或需要大量自定義訓練循環的場景。另一方面,PyTorch Lightning 將這種能力封裝在一個結構化、一致的接口中,減少了樣板代碼,簡化了多 GPU 訓練,并鼓勵了內置日志記錄和模塊化設計等最佳實踐。
對于許多從事生產級代碼的數據科學家和機器學習工程師來說,Lightning 可以幫助保持代碼的可讀性、可重復性和效率。如果您是研究人員或喜歡微管理訓練過程的每個方面,您可能會繼續偏愛普通的 PyTorch。事實上,真正的美在于 PyTorch Lightning 仍然由 PyTorch 驅動:如果您需要深入了解,自由仍然存在。