













有bug!用Pytorch Lightning重構代碼速度更慢,修復后速度倍增
PyTorch Lightning 是一種重構 PyTorch 代碼的工具,它可以抽出代碼中復雜重復的部分,使得 AI 研究可擴展并且可以快速迭代。然而近日一位名為 Florian Ernst 的博主卻發現 PyTorch Lightning 存在一個 bug——讓原本應該加速的訓練變得更慢了。
本文作者 Florian Ernst
Ernst 撰寫博客詳細描述了他發現這個 bug 的過程,以下是博客原文。
兩周前,我將一些深度學習代碼重構為 Pytorch Lightning,預計大約有 1.5 倍的加速。然而,訓練、評估和測試任務的速度卻降為原來的 1/4。重構之后的神經網絡需要運行幾天才能得出結果,因此我想找出原因,并盡可能地減少訓練時間。
事情是這樣的,我使用的是一些開源深度學習代碼,這些代碼是用來展示某些機器學習任務最新架構的。然而這些代碼本身既不整潔也沒進行優化。我注意到幾個可以加速的地方,并將代碼重構為 Pytorch 代碼,讓訓練大約快了 3 倍。
但我認為還有改進的余地。Pytorch Lightning 是一個非常好的工具:它刪除了大量樣板代碼,并配備了一些優化方法,因此我決定使用 Lightning 重構這些代碼。
我原本希望代碼大約能提速 1.5 倍,但完成重構時,我驚訝地發現迭代時間從 4 秒變成了 15 秒,這使訓練時間多了近 3 倍。
問題出在哪里?
我首先運行 Lightning 的分析器來找出問題所在。
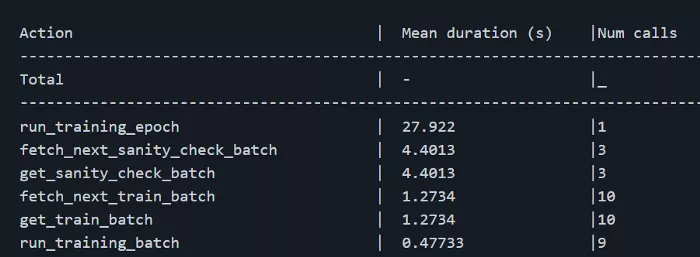
基礎分析器給了我一個起點:大部分時間都花在運行一個 epoch 上;高級分析器沒有給我更多信息。
我想知道我是否在神經網絡上錯誤地配置了一些超參數。我打亂了其中一些超參數,訓練速度沒有任何變化。
然后我調整了數據加載器,發現改變作業數 n_jobs 會對總訓練時間產生影響。然而影響不是加快了計算速度,而是減慢了。
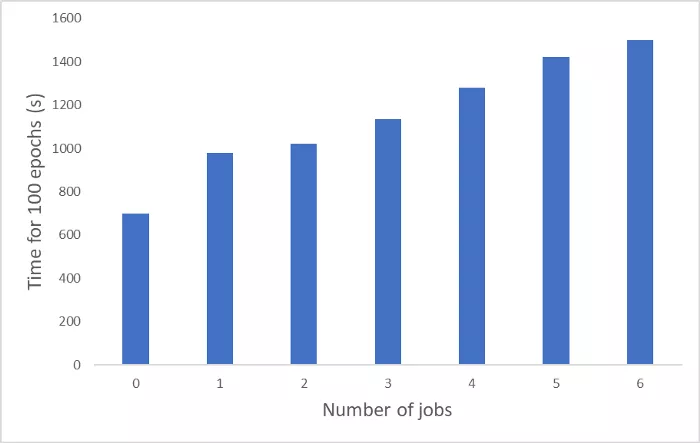
隨著 job 數變化,100 個 epoch 花費的時間。
使用 n_jobs=0 完全禁用多處理使我的迭代幾乎比使用 6 個內核快了 2 倍。默認情況下,Pytorch 在兩個 epoch 之間會 kill 掉運行中的進程(worker)并重新加載,因而需要重新加載數據集。
在我這個例子中,加載數據集非常慢。我將 DataLoader 里的 persistent_workers 參數設置為 True,以防止運行中的進程被殺死,進而防止重新加載數據。
- # My data Loader parameters
- DataLoader(
- train_dataset, batch_size=64, shuffle=True, num_workers=n_workers,
- persistent_workers=True, pin_memory=True,
- )
因此,有兩種可能性:
- Pytorch Lightning kill 掉 worker,沒有考慮 persistent_workers 參數;
- 問題出在別的地方。
我在 GitHub 上創建了一個 issue,希望 Lightning 團隊意識這個問題,接下來我要尋找問題根源。
GitHub 地址:https://github.com/PyTorchLightning/pytorch-lightning/issues/10389
尋找問題根源
Lightning 的 profiler 與上下文管理器一起運行并計算給定塊花費的時間。它可以輕松搜索特定的 profiler 操作,以運行「run_training_epoch」為例 。
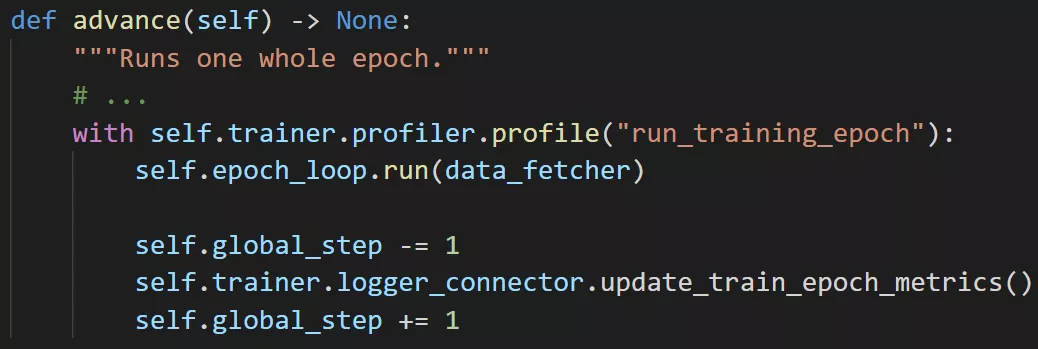
我開始探究 Lightning 源碼,查看導致循環(loops)變慢的指令,我發現了一些問題:Loop.run 調用 Loop.on_run_start、Loop.on_run_start 重新加載 dataloader,如下圖所示:
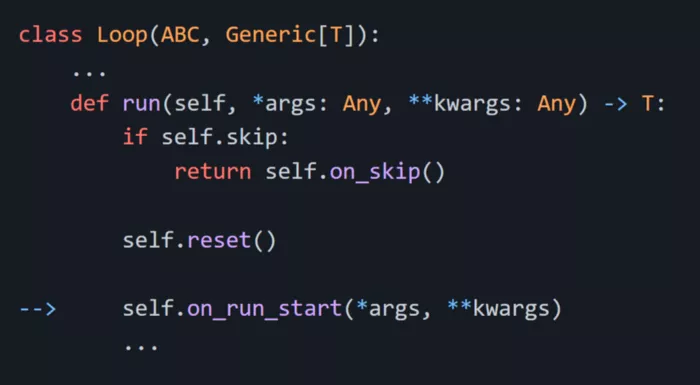
Loop.run 調用 Loop.on_run_start…
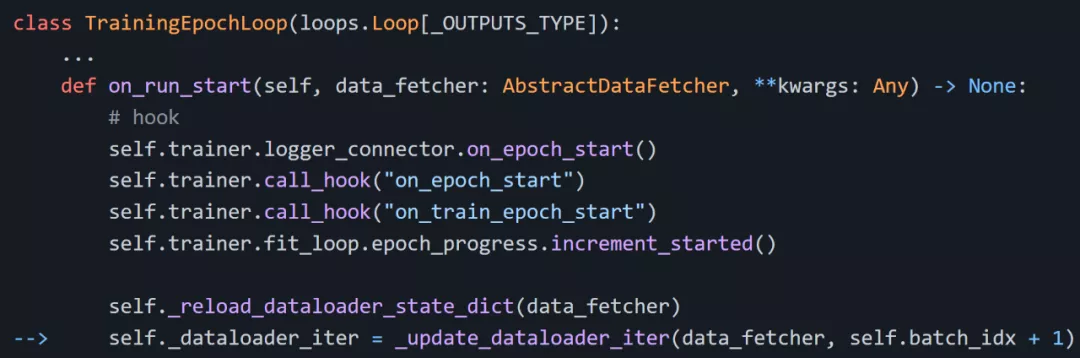
Loop.on_run_start 重新調用 dataloader
問題看起來確實來自在每個 epoch 中重新加載 DataLoader。查看 DataLoader 的源碼,發現是這樣的:
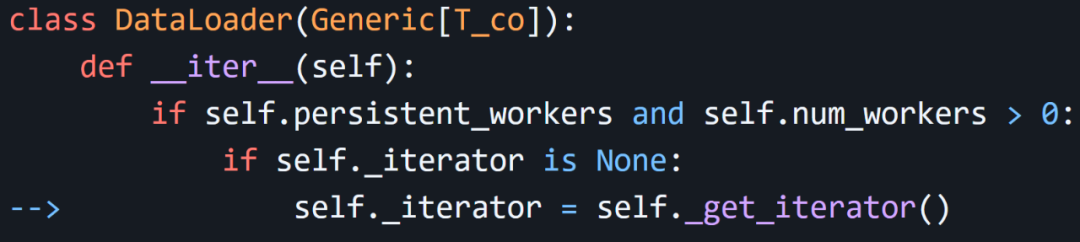
當使用 persistent_workers > 0 迭代 DataLoader 時,如果_iterator` 為 None,則使用_get_iterator() 重新加載整個數據集。可以確定的是 Pytorch Lightning 錯誤地重置了 _iterator,從而導致了這個問題。
為了證實這一發現,我用一個自定義的只能重載的__iter__方法替換了 DataLoader:

正如預期的那樣,在迭代之后,_iterator 屬性被正確設置,但在下一個 epoch 開始之前被重置為 None。

n_jobs=1,persistent_workers=True
現在,我只需要知道屬性何時被設置為 None ,這樣就可找到問題的根源。我嘗試使用調試器,但由于多進程或 CUDA 而導致程序崩潰。我開始采用 Python 的 getter & setter 用法:
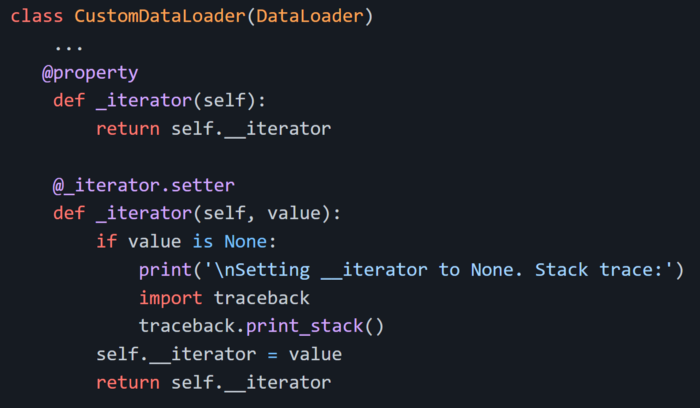
當 DataLoader._iterator 設置為 None 時,將會打印 stack trace
這樣做非常有效,會輸出如下內容:
- File "trainer\trainer.py", line 1314, in _run_train
- self.fit_loop.run()
- ...
- File "loops\fit_loop.py", line 234, in advance
- self.epoch_loop.run(data_fetcher)
- File "loops\base.py", line 139, in run
- self.on_run_start(*args, **kwargs)
- File "loops\epoch\training_epoch_loop.py", line 142, in on_run_start
- self._dataloader_iter = _update_dataloader_iter(...)
- File "loops\utilities.py", line 121, in _update_dataloader_iter
- dataloader_iter = enumerate(data_fetcher, batch_idx)
- File "utilities\fetching.py", line 198, in __iter__
- self.reset()
- File "utilities\fetching.py", line 212, in reset
- self.dataloader.reset()
- ...
- File "trainer\supporters.py", line 498, in _shutdown_workers_and_reset_iterator
- dataloader._iterator = None
通過跟蹤發現每次開始運行時都會調用 DataLoader.reset。通過深入研究代碼后,我發現每次迭代都會重置 DataFetcher,從而導致 DataLoader 也被重置。代碼中沒有條件來避免重置:每個 epoch 都必須重置 DataLoader。
這就是我發現迭代緩慢的根本原因。
修復 bug
既然發現了 bug,就要想辦法修復。修復 bug 非常簡單:我將 self.reset 行從 DataFetcher 的__iter__ 方法中移除:
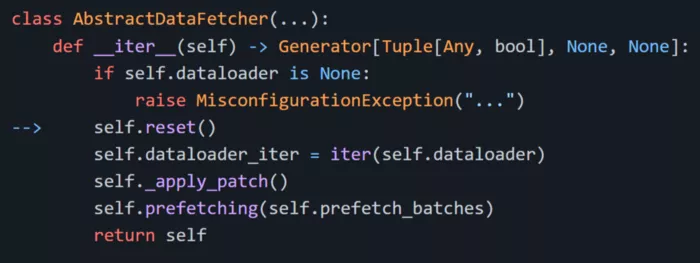
通過修改后再次訓練,現在一次迭代只需要 1.5 秒,而此前需要 15 秒,使用 vanilla Pytorch 也需要 3 秒,相比較而言,速度確實提升了很多。
我將發現的這個 bug 報告給了 Lightning 團隊,他們對問題進行了修復并在第二天推送了修補程序。我隨后更新了庫,更新后發現他們的修復確實有效。相信更多人將從這次修復中受益,并且他們的 Lightning 模型的訓練和測試時間會得到改善。如果你最近還沒有更新依賴項,請嘗試安裝 pytorch-lightning==1.5.1 或更高版本!





















