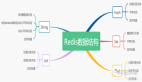
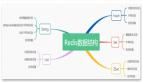
Redis 的九種數據結構,如何選擇?
作為一名合格的 Redis 使用者,我們一定要知道 Redis 有哪數據類型,以及每種數據類型的特征,操作方式和應用場景,這樣才能幫助我們更好地決策使用哪種數據類型。本文我們將詳細地介紹 Redis 9種數據類型:
- 字符串(String)
- 列表(List)
- 集合(Set)
- 有序集合(Sorted Set)
- 哈希(Hash)
- 位圖(Bitmap)
- HyperLogLog
- 流(Stream)
- 地理空間索引(Geospatial)

1. 字符串(String)
字符串是 Redis 中最基本、最常用的數據類型。一個字符串值可以包含任何數據,如文本、數字、二進制數據等,最大長度為 512MB。
(1) 常用命令
- SET key value [EX seconds] [PX milliseconds] [NX|XX] :設置指定鍵的值,可以選擇設置過期時間、僅在鍵不存在時設置(NX)、僅在鍵存在時設置(XX)。
- GET key:獲取指定鍵的值。
- DEL key:刪除指定鍵。
- INCR key:對存儲在指定鍵的值進行遞增,要求該值為整數。
- DECR key:對存儲在指定鍵的值進行遞減操作,要求該值為整數。
- APPEND key value:將指定值追加到鍵的現有值后面。
- MGET key1 key2 ... :批量獲取多個鍵值對。
- MSET key1 value1 key2 value2 ... :批量設置多個鍵值對。
- GETSET key value:將指定鍵的值設置為新值,并返回舊值。
(2) 應用場景
- 緩存:由于字符串的存取速度極快,廣泛應用于緩存常用數據,如網頁內容、用戶會話等。
- 計數器:使用 INCR/DECR 命令可以高效地實現訪問計數器、點贊數等。
- 分布式鎖:通過 SET 命令的 NX 選項,可以實現簡單的分布式鎖機制。
- 存儲小量數據:例如用戶的基本信息、配置參數等。
(3) 注意事項
- 內存限制:雖然單個字符串最大可達 512MB,但實際使用中需注意 Redis 的內存容量和內存分配策略。
- 數據類型一致性:在使用 INCR/DECR 等命令時,確保鍵對應的值是整數類型,否則會引發錯誤。
2. 列表
列表是 Redis 中的一種簡單的有序集合,內部使用雙向鏈表實現。列表中的元素按插入順序排列,允許重復的元素。Redis提供了一系列操作命令,可以在列表的頭部或尾部插入、刪除元素,也可以進行范圍查詢等操作。
(1) 常用命令
- LPUSH key value [value ...] : 將一個或多個值插入到列表的頭部。
- RPUSH key value [value ...] :將一個或多個值插入到列表的尾部。
- LPOP key:從列表的頭部移除并返回元素。
- RPOP key:從列表的尾部移除并返回元素。
- LRANGE key start stop:返回列表指定范圍內的元素。
- LLEN key:獲取列表的長度。
- LREM key count value:根據給定的值,從列表中移除元素,count參數定義移除的數量和方向。
- LTRIM key start stop:對列表進行修剪,只保留指定范圍內的元素。
- LINDEX key index:獲取列表中指定位置的元素。
- LINSERT key BEFORE|AFTER pivot value:在列表中指定元素的前或后插入新的元素。
(2) 應用場景
- 消息隊列:由于列表支持先進先出(FIFO)和后進先出(LIFO)的操作,可以用作簡單的消息隊列。
- 任務調度:將任務放入列表中,通過消費者從列表中取出并處理,實現任務的分發和調度。
- 排行榜:結合其它數據結構,可以實現簡單的排行榜功能。
- 實時聊天:存儲近期的聊天記錄或消息日志。
(3) 注意事項
- 內存消耗:由于列表底層使用雙向鏈表實現,對于大量元素的列表可能會消耗較多內存。
- 性能問題:頻繁地在列表的中間進行插入或刪除操作,可能會影響性能,建議盡量在兩端進行操作。
3. 集合
集合是一種無序的、唯一性的元素集合。Redis 中的 Set 使用哈希表來實現,因此具有快速的成員查找、添加和刪除等操作。集合支持豐富的集合運算,如求交集、并集和差集,非常適合處理無序且不重復的數據。
(1) 常用命令
- SADD key member [member ...] :向集合添加一個或多個成員。
- SREM key member [member ...] :從集合中移除一個或多個成員。
- SMEMBERS key:返回集合中的所有成員。
- SISMEMBER key member:判斷指定成員是否是集合的成員。
- SCARD key:獲取集合的成員數量。
- SRANDMEMBER key [count] :隨機返回集合中的一個或多個成員。
- SINTER key [key ...] :計算多個集合的交集
- SUNION key [key ...] :計算多個集合的并集
- SDIFF key [key ...] :分別計算多個集合的差集。
- SMOVE source destination member:將成員從一個集合移動到另一個集合。
(2) 應用場景
- 標簽系統:為對象打上多個標簽,并通過集合運算實現標簽的交叉查詢。
- 社交網絡:保存用戶的關注列表、粉絲列表等,利用集合的唯一性特性防止重復。
- 推薦系統:通過計算用戶行為集合的交集或并集,生成個性化推薦。
- 權限管理:存儲用戶的權限集合,通過集合運算實現權限的繼承和組合。
(3) 注意事項
- 無序性:集合不保證元素的順序,如果需要有序的數據,請考慮使用其他數據類型如有序集合。
- 唯一性:集合中的元素是唯一的,如果需要存儲重復的數據,需要使用其他數據結構或在元素中添加唯一標識符。
- 內存優化:對于大量元素的集合,可以通過RDB或AOF持久化策略進行優化,減少內存消耗。
4. 有序集合
有序集合是在集合的基礎上增加了“權重”或者“分數”(score)概念的集合類型。每個元素在有序集合中都關聯一個分數,Redis通過分數對集合中的元素進行排序。內部實現采用跳表(Skip List)數據結構,允許高效的范圍查詢和排名操作。
(1) 常用命令
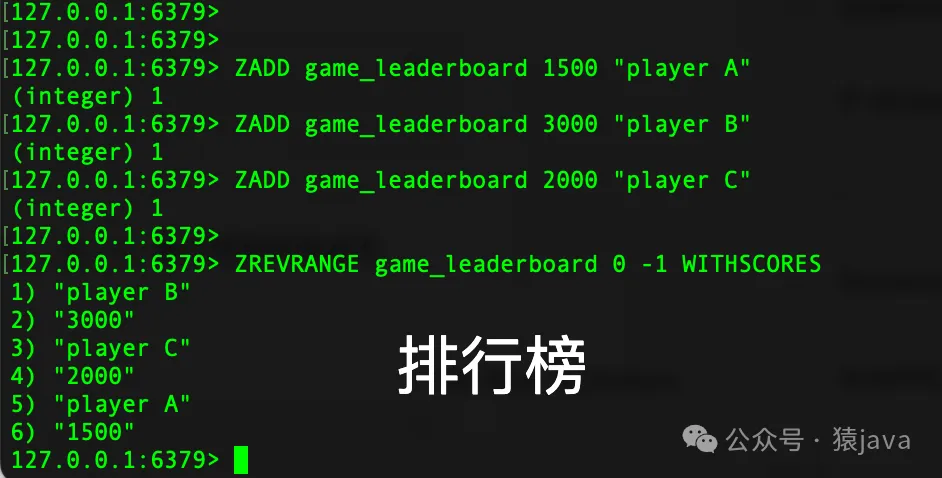
- ZADD key [NX|XX] [CH] [INCR] score member [score member ...] :向有序集合添加一個或多個成員,或者更新成員的分數。
- ZREM key member [member ...] :移除一個或多個成員。
- ZINCRBY key increment member:為有序集合中的成員的分數加上指定的增量值。
- ZRANGE key start stop [WITHSCORES] :返回有序集合中指定范圍內的成員,按分數正序排列。
- ZREVRANGE key start stop [WITHSCORES] :返回有序集合中指定范圍內的成員,按分數逆序排列。
- ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] :返回有序集合中分數在指定范圍內的成員。
- ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count] :返回有序集合中分數在指定范圍內的成員。
- ZSCORE key member:返回成員的分數。
- ZCARD key:獲取有序集合的成員數量。
- ZCOUNT key min max:統計有序集合中分數在指定范圍內的成員數量。
- ZRANK key member:返回成員在有序集合中的排名,從小到大
- ZREVRANK key member:返回成員在有序集合中的排名,從大到小。
- ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] :對多個有序集合進行并集運算,并將結果存儲到目標鍵。
- ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] :對多個有序集合進行交集運算,并將結果存儲到目標鍵。
(2) 應用場景
- 排行榜:有序集合非常適合實現游戲排行榜、銷售排行等功能,通過分數來定義排名。
- 延時隊列:利用分數表示任務的執行時間,實現延時任務的調度。
- 推薦系統:通過分數表示推薦的相關性或優先級,動態調整推薦結果。
- 地理位置排名:結合地理空間索引,按照距離或其他指標對地理位置進行排序。
- 計時任務:存儲定時任務的執行時間,并根據當前時間觸發相應的任務。
(3) 注意事項
- 分數的唯一性:有序集合中的成員可以有相同的分數,但成員本身必須唯一。
- 分數的精度:分數是雙精度浮點數,可能存在精度問題,需在應用層面做好相應處理。
- 性能優化:對于大量的有序集合操作,合理使用 pipeline 或批量操作命令,提升性能。
5. 哈希
哈希是 Redis 中用于存儲鍵值對映射的數據類型。類似于編程語言中的字典、Map 或對象,哈希適合存儲對象的屬性信息。內部實現使用哈希表或者壓縮列表(ziplist),當字段數量較少時,使用壓縮列表可以節省內存。
(1) 常用命令
- HSET key field value [field value ...] : 向哈希中設置一個字段及其值
- HMSET key field value [field value ...] :向哈希中設置多個字段及其值
- HGET key field:獲取哈希中指定字段的值
- HMGET key field [field ...] :獲取哈希中多個字段的值
- HDEL key field [field ...] :刪除哈希中的一個或多個字段
- HEXISTS key field:判斷哈希中是否存在指定字段
- HLEN key:獲取哈希中字段的數量
- HGETALL key:獲取哈希中所有的字段和值
- HINCRBY key field increment:為哈希中的整數字段值加上指定的增量
- HINCRBYFLOAT key field increment:為哈希中的浮點數字段值加上指定的增量
- HKEYS key:分別獲取哈希中的所有字段名
- HVALS key:分別獲取哈希中的所有字段值
- HSCAN key cursor [MATCH pattern] [COUNT count]:遍歷哈希中的字段和值
(2) 應用場景
- 對象存儲:將對象的屬性存儲在哈希中,方便獲取和修改單個屬性。
- 會話管理:存儲用戶會話信息,如登錄狀態、權限等。
- 配置管理:存儲應用的配置信息,通過哈希的字段結構組織數據。
- 統計數據:記錄頁面訪問次數、用戶行為等統計信息。
(3) 注意事項
- 字段數量:哈希在字段數量較少時性能和內存消耗較優,字段過多時可能不如使用字符串或有序集合高效。
- 數據一致性:在分布式環境中,更新哈希的某個字段時需注意數據的一致性和并發控制。
- 持久化策略:針對頻繁更新的哈希數據,需合理配置Redis的持久化策略,避免數據丟失。
6. 位圖
位圖并不是 Redis 官方的數據類型,而是基于字符串數據類型的二進制位操作,通過對字符串進行位級別的操作,實現高效的位圖功能。位圖適合用于存在性判斷、布隆過濾器、用戶簽到等場景。
(1) 常用命令
- SETBIT key offset value:將指定偏移量的位設置為0或1。
- GETBIT key offset:獲取指定偏移量的位的值。
- BITCOUNT key [start end] :統計位圖中值為1的位數量,可以指定范圍。
- BITOP operation destkey key [key ...] :對多個位圖進行位操作,如AND、OR、XOR、NOT,并將結果存儲到目標鍵。
- BITPOS key bit [start] [end] :查找位圖中第一個或最后一個指定值的位的位置。
(2) 應用場景
- 用戶簽到:通過位圖表示用戶的每日簽到狀態,高效存儲和查詢。
- 在線狀態:記錄用戶的在線狀態,通過位圖快速判斷用戶是否在線。
- 侵入檢測:利用位圖進行數據的快速存在性檢測,如防止重復提交。
- 布隆過濾器:與哈希算法結合,實現高效的布隆過濾器,用于防止緩存穿透等問題。
(3) 注意事項
- 偏移量管理:需要合理管理位圖的偏移量,確保數據的一致性和正確性。
- 內存優化:位圖基于字符串實現,設置較高的偏移量會導致內存浪費,需根據實際需求設計位圖的大小。
- 原子性操作:Redis的位圖操作是原子性的,但復雜的位操作需要在應用層進行邏輯控制。
7. HyperLogLog
HyperLogLog是一種用于基數估算的數據結構,Redis通過內置支持 HyperLogLog,實現了高效的基數統計功能。HyperLogLog在內存消耗極低的情況下,可以近似計算大規模數據的基數(如唯一用戶數),但不支持刪除操作。
(1) 常用命令
- PFADD key element [element ...]:將元素添加到HyperLogLog中。
- PFCOUNT key [key ...]:返回一個或多個HyperLogLog的數據基數估算。
- PFMERGE destkey sourcekey [sourcekey ...]:合并多個HyperLogLog,并將結果存儲到目標鍵。
(2) 應用場景
- UV統計:統計網站或應用的獨立訪客(Unique Visitors)。
- 數據去重:快速估算大規模數據的去重基數。
- 實時分析:在實時數據流中進行基數統計,如消息隊列中的唯一消費者數。
- 推薦系統:計算用戶的獨特行為,如瀏覽的獨特商品數量。
(3) 注意事項
- 精度問題:HyperLogLog提供的是基數的近似值,誤差在±0.81%左右,適用于大規模數據的估算場景。
- 不可刪除:一旦元素被添加到HyperLogLog中,無法單獨刪除元素,適用于無需精確刪除的場景。
- 多鍵合并:PFMERGE操作會合并多個HyperLogLog的數據,適用于分布式統計的合并需求。
8. 流
流是 Redis 5.0 引入的一種新的數據類型,用于處理消息隊列和事件流。流支持消息的生產和消費,具有持久化、可靠性和可擴展性等特性。內部通過雙端鏈表和索引實現,支持消費者組、消息確認等功能。
(1) 常用命令
- XADD key [MAXLEN ~|= maxlen] * field value [field value ...]:向流中添加一條消息,可以限制流的長度。
- XLEN key:獲取流的長度,即消息數量。
- XRANGE key start end [COUNT count]:按時間范圍獲取流中的消息,支持正向遍歷。
- XREVRANGE key end start [COUNT count]:按時間范圍獲取流中的消息,支持反向遍歷。
- XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]:阻塞讀取流中的新消息。
- XGROUP CREATE key groupname id [MKSTREAM]:消費者組管理命令。
- XGROUP SETID key groupname id:消費者組管理命令。
- XGROUP DELGROUP key groupname:消費者組管理命令。
- XREADGROUP groupname consumer [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]:消費者組內部的阻塞讀取命令。
- XACK key groupname id [id ...]:確認消息已被消費。
- XPENDING key groupname [start end count] [consumer]:查看消費者組的待處理消息。
- XDEL key id [id ...]:刪除指定消息或修剪流長度。
- XTRIM key MAXLEN ~|= maxlen:刪除指定消息或修剪流長度。
(2) 應用場景
- 消息隊列:實現可靠的消息隊列,支持消息的持久化和消費者組的負載均衡。
- 實時數據流處理:處理實時生成的數據流,如日志收集、事件追蹤等。
- 通知系統:實現實時通知推送,如即時通訊、系統告警等。
- 任務調度:將任務以消息的形式放入流中,由消費者組分發和處理任務。
(3) 注意事項
- 消費確認:使用消費者組時,需要正確進行消息的確認(XACK),以避免消息丟失或重復消費。
- 流長度控制:通過XADD命令的MAXLEN選項或XTRIM命令定期修剪流的長度,防止數據無限增長。
- 消費者組管理:合理設計消費者組和消費者數量,避免消費者過多導致的性能問題。
- 持久化策略:由于流支持持久化,需要根據業務需求合理配置RDB或AOF持久化策略。
9. 地理空間索引
Redis 的地理空間索引基于有序集合實現,通過經緯度數據存儲和地理空間計算,支持距離查詢和范圍查詢。常用于實現基于地理位置的應用,如附近的人/商家、地圖導航等。
(1) 常用命令
- GEOADD key longitude latitude member [longitude latitude member ...]:向地理空間索引中添加成員及其經緯度信息。
- GEODIST key member1 member2 [unit]:計算兩個成員之間的距離,可以指定單位(米、千米、英里、英尺)。
- GEORADIUS key longitude latitude radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ORDER ASC|DESC] [STORE key] [STOREDIST key]:根據給定的經緯度坐標和半徑,查找在指定范圍內的成員,可以選擇返回坐標、距離、哈希值等附加信息。
- GEORADIUSBYMEMBER key member radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ORDER ASC|DESC] [STORE key] [STOREDIST key]:根據給定的經緯度坐標和半徑,查找在指定范圍內的成員,可以選擇返回坐標、距離、哈希值等附加信息。
- GEOHASH key member [member ...]:返回一個或多個成員的Geohash編碼。
- GEOPOS key member [member ...]:返回一個或多個成員的經緯度坐標。
- GEOSEARCH key FROMMEMBER member BYRADIUS radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC]:基于成員或指定經緯度進行地理空間搜索。
- GEOSEARCH key FROMLONLAT longitude latitude BYRADIUS radius unit [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC]:基于成員或指定經緯度進行地理空間搜索。
(2) 應用場景
- 位置服務:實現基于位置的服務,如查找附近的餐廳、加油站、醫院等。
- 物流配送:優化配送路線,根據地理位置進行調度和分配。
- 社交網絡:查找附近的好友、動態或活動。
- 游戲開發:實現基于位置的游戲元素,如尋寶、位置打卡等。
(3) 注意事項
- 精度選擇:通過 GEORADIUS 命令的 unit 參數選擇合適的距離單位,確保計算的精度和性能。
- 數據分布:合理分布地理空間坐標,避免數據過于集中導致性能瓶頸。
- 索引維護:在添加或刪除地理空間數據時,確保有序集合的索引被正確維護,避免數據不一致。
- 距離計算:GEODIST命令基于地球的球面模型進行距離計算,不適用于需要高度精確距離的場景。
總結
本文我們分析了 Redis中常見的 9種數據類型,從最基本的字符串、列表、集合到復雜的有序集合、哈希,再到位圖、HyperLogLog、流和地理空間索引,每種數據類型都有其獨特的特性和應用場景。熟練掌握這些數據類型的使用及其底層實現,能夠幫助我們設計高效、可擴展的系統架構,充分發揮Redis的性能優勢。