Redis中8種數據結構的底層數據結構源碼詳解
redis存儲類型
主要提供了5種數據結構:字符串(String)、哈希(hash)、列表(list)、集合(set)、有序集合(short set);
redis底層實現的8種數據結構
- SDS simple synamic string:支持自動動態擴容的字節數組
- list :鏈表
- dict :使用雙哈希表實現的, 支持平滑擴容的字典
- zskiplist :附加了后向指針的跳躍表
- intset : 用于存儲整數數值集合的自有結構
- ziplist :一種實現上類似于TLV, 但比TLV復雜的, 用于存儲任意數據的有序序列的數據結構
- quicklist:一種以ziplist作為結點的雙鏈表結構, 實現的非常不錯
- zipmap : 一種用于在小規模場合使用的輕量級字典結構
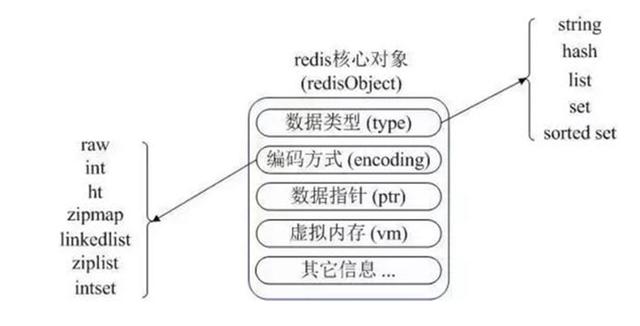
其中5種存儲類型與8種數據結構的橋梁, 是redisObject;
Redis中的Key與Value在表層都是一個redisObject實例, 所以該結構有所謂的"類型", 即是ValueType. 對于每一種Value Type類型的redisObject;
其底層至少支持兩種不同的底層數據結構來實現. 以應對在不同的應用場景中, Redis的運行效率, 或內存占用等
底層數據結構分析
1、SDS - simple dynamic string
可以在安裝目錄的src文件夾下看到sds.c和sds.h的源碼文件
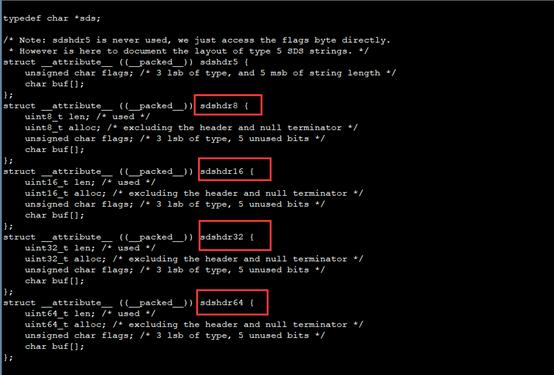
- typedef char *sds;
- /* Note: sdshdr5 is never used, we just access the flags byte directly.
- * However is here to document the layout of type 5 SDS strings. */
- struct __attribute__ ((__packed__)) sdshdr5 {
- unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
- char buf[];
- };
- struct __attribute__ ((__packed__)) sdshdr8 {
- uint8_t len; /* used */
- uint8_t alloc; /* excluding the header and null terminator */
- unsigned char flags; /* 3 lsb of type, 5 unused bits */
- char buf[];
- };
- struct __attribute__ ((__packed__)) sdshdr16 {
- uint16_t len; /* used */
- uint16_t alloc; /* excluding the header and null terminator */
- unsigned char flags; /* 3 lsb of type, 5 unused bits */
- char buf[];
- };
- struct __attribute__ ((__packed__)) sdshdr32 {
- uint32_t len; /* used */
- uint32_t alloc; /* excluding the header and null terminator */
- unsigned char flags; /* 3 lsb of type, 5 unused bits */
- char buf[];
- };
- struct __attribute__ ((__packed__)) sdshdr64 {
- uint64_t len; /* used */
- uint64_t alloc; /* excluding the header and null terminator */
- unsigned char flags; /* 3 lsb of type, 5 unused bits */
- char buf[];
- };s
sdshdr的存儲結構

sdshdr是頭部, buf是真實存儲用戶數據的地方.(buf="數據" + "\0" );sds有四種不同的頭部. sdshdr5未 使用,未顯示

en分別以uint8, uint16, uint32, uint64表示用戶數據的長度(不包括末尾的\0)
alloc分別以uint8, uint16, uint32, uint64表示整個SDS, 除過頭部與末尾的\0, 剩余的字節數.
flag始終為一字節, 以低三位標示著頭部的類型, 高5位未使用.
創建一個SDS實例的三個接口
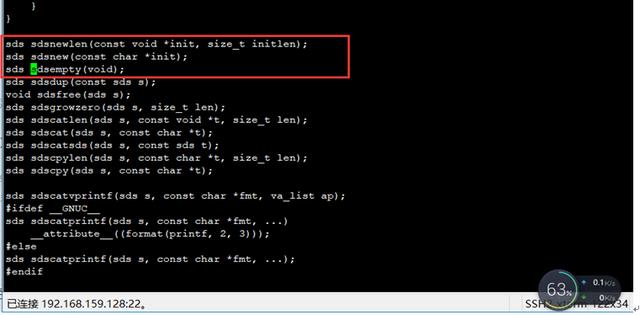
2、list
鏈表實現, 鏈表結點不直接持有數據, 而是通過void *指針來間接的指向數據. 其實現位于 src/adlist.h與src/adlist.c中,
內存布局
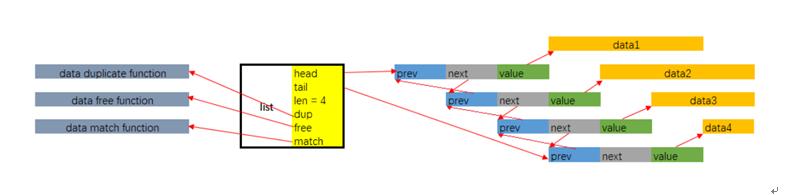
list在Redis除了作為一些Value Type的底層實現外, 還廣泛用于Redis的其它功能實現中, 作為一種數據結構工具使用.
在list的實現中, 除了基本的鏈表定義外, 還額外增加了:迭代器listIter的定義, 與相關接口的實現.
由于list中的鏈表結點本身并不直接持有數據, 而是通過value字段, 以void *指針的形式間接持有, 所以數據的生命周期并不完全與鏈表及其結點一致. 這給了list的使用者相當大的靈活性. 比如可以多個結點持有同一份數據的地址. 但與此同時, 在對鏈表進行銷毀, 結點復制以及查找匹配時, 就需要list的使用者將相關的函數指針賦值于list.dup, list.free, list.match字段.
3、dict
dict類似于C++標準庫中的std::unordered_map, 其實現位于 src/dict.h 與 src/dict.c中
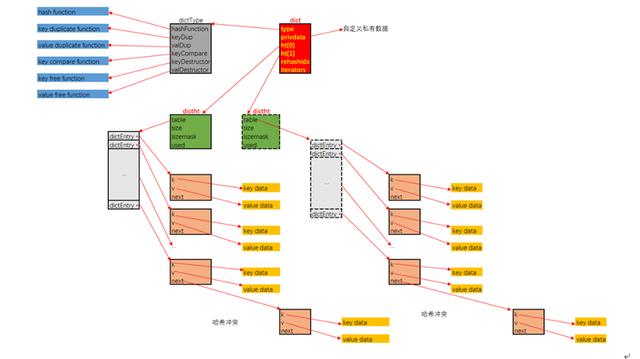
dict中存儲的鍵值對, 是通過dictEntry這個結構間接持有的, k通過指針間接持有鍵, v通過指針間接持有值. 注意, 若值是整數值的話, 是直接存儲在v字段中的, 而不是間接持有. 同時next指針用于指向, 在bucket索引值沖突時, 以鏈式方式解決沖突, 指向同索引的下一個dictEntry結構.
dict即為字典. 其中type字段中存儲的是本字典使用到的各種函數指針, 包括散列函數, 鍵與值的復制函數, 釋放函數, 以及鍵的比較函數. privdata是用于存儲用戶自定義數據. 這樣, 字典的使用者可以最大化的自定義字典的實現, 通過自定義各種函數實現, 以及可以附帶私有數據, 保證了字典有很大的調優空間.
字典為了支持平滑擴容, 定義了ht[2]這個數組字段. 其用意是這樣的:
一般情況下, 字典dict僅持有一個哈希表dictht的實例, 即整個字典由一個bucket實現.
隨著插入操作, bucket中出現沖突的概率會越來越大, 當字典中存儲的結點數目, 與bucket數組長度的比值達到一個閾值(1:1)時, 字典為了緩解性能下降, 就需要擴容
擴容的操作是平滑的, 即在擴容時, 字典會持有兩個dictht的實例, ht[0]指向舊哈希表, ht[1]指向擴容后的新哈希表.
內存布局
4、zskiplist
zskiplist是Redis實現的一種特殊的跳躍表. 跳躍表是一種基于線性表實現簡單的搜索結構, 其最大的特點就是: 實現簡單, 性能能逼近各種搜索樹結構.
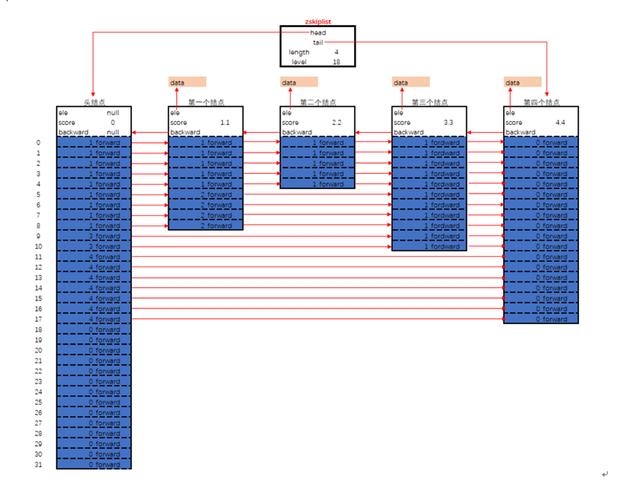
zskiplist的核心設計要點:
頭結點不持有任何數據, 且其level[]的長度為32
每個結點, 除了持有數據的ele字段, 還有一個字段score, 其標示著結點的得分, 結點之間憑借得分來判斷先后順序, 跳躍表中的結點按結點的得分升序排列.
每個結點持有一個backward指針, 這是原版跳躍表中所沒有的. 該指針指向結點的前一個緊鄰結點.
每個結點中最多持有32個zskiplistLevel結構. 實際數量在結點創建時, 按冪次定律隨機生成(不超過32). 每個zskiplistLevel中有兩個字段.
內存布局
5、intset
用于存儲在序的整數的數據結構, 也底層數據結構中最簡單的一個, 其定義與實現在src/intest.h與src/intset.c中
inset結構中的encoding的取值有三個, 分別是宏INTSET_ENC_INT16, INTSET_ENC_INT32, INTSET_ENC_INT64. length代表其中存儲的整數的個數, contents指向實際存儲數值的連續內存區域
內存布局

intset中各字段, 包括contents中存儲的數值, 都是以主機序(小端字節序)存儲的. 這意味著Redis若運行在PPC這樣的大端字節序的機器上時, 存取數據都會有額外的字節序轉換開銷
當encoding == INTSET_ENC_INT16時, contents中以int16_t的形式存儲著數值. 類似的, 當encoding == INTSET_ENC_INT32時, contents中以int32_t的形式存儲著數值.
但凡有一個數值元素的值超過了int32_t的取值范圍, 整個intset都要進行升級, 即所有的數值都需要以int64_t的形式存儲. 顯然升級的開銷是很大的.
intset中的數值是以升序排列存儲的, 插入與刪除的復雜度均為O(n). 查找使用二分法, 復雜度為O(log_2(n))
intset的代碼實現中, 不預留空間, 即每一次插入操作都會調用zrealloc接口重新分配內存. 每一次刪除也會調用zrealloc接口縮減占用的內存. 省是省了, 但內存操作的時間開銷上升了.
intset的編碼方式一經升級, 不會再降級.
總之, intset適合于如下數據的存儲:
所有數據都位于一個穩定的取值范圍中. 比如均位于int16_t或int32_t的取值范圍中
數據穩定, 插入刪除操作不頻繁. 能接受O(lgn)級別的查找開銷
6、ziplist
ziplist是Redis底層數據結構中, 最茍的一個結構. 它的設計宗旨就是: 省內存, 從牙縫里省內存. 設計思路和TLV一致, 但為了從牙縫里節省內存, 做了很多額外工作.
ziplist的內存布局與intset一樣: 就是一塊連續的內存空間. 但區域劃分比較復雜

和intset一樣, ziplist中的所有值都是以小端序存儲的
zlbytes字段的類型是uint32_t, 這個字段中存儲的是整個ziplist所占用的內存的字節數
zltail字段的類型是uint32_t, 它指的是ziplist中最后一個entry的偏移量. 用于快速定位最后一個entry, 以快速完成pop等操作
zllen字段的類型是uint16_t, 它指的是整個ziplit中entry的數量. 這個值只占16位, 所以蛋疼的地方就來了: 如果ziplist中entry的數目小于65535, 那么該字段中存儲的就是實際entry的值. 若等于或超過65535, 那么該字段的值固定為65535, 但實際數量需要一個個entry的去遍歷所有entry才能得到.
zlend是一個終止字節, 其值為全F, 即0xff. ziplist保證任何情況下, 一個entry的首字節都不會是255
在畫圖展示entry的內存布局之前, 先講一下entry中都存儲了哪些信息:
每個entry中存儲了它前一個entry所占用的字節數. 這樣支持ziplist反向遍歷.
每個entry用單獨的一塊區域, 存儲著當前結點的類型: 所謂的類型, 包括當前結點存儲的數據是什么(二進制, 還是數值), 如何編碼(如果是數值, 數值如何存儲, 如果是二進制數據, 二進制數據的長度)最后就是真實的數據了
7、quicklist
如果說ziplist是整個Redis中為了節省內存, 而寫的最茍的數據結構, 那么稱quicklist就是在最茍的基礎上, 再茍了一層. 這個結構是Redis在3.2版本后新加的, 在3.2版本之前, 我們可以講, dict是最復雜的底層數據結構, ziplist是最茍的底層數據結構. 在3.2版本之后, 這兩個記錄被雙雙刷新了.
這是一種, 以ziplist為結點的, 雙端鏈表結構. 宏觀上, quicklist是一個鏈表, 微觀上, 鏈表中的每個結點都是一個ziplist.
它的定義與實現分別在src/quicklist.h與src/quicklist.c中
這里定義了五個結構體:
quicklistNode, 宏觀上, quicklist是一個鏈表, 這個結構描述的就是鏈表中的結點. 它通過zl字段持有底層的ziplist. 簡單來講, 它描述了一個ziplist實例
quicklistLZF, ziplist是一段連續的內存, 用LZ4算法壓縮后, 就可以包裝成一個quicklistLZF結構. 是否壓縮quicklist中的每個ziplist實例是一個可配置項. 若這個配置項是開啟的, 那么quicklistNode.zl字段指向的就不是一個ziplist實例, 而是一個壓縮后的quicklistLZF實例
quicklist. 這就是一個雙鏈表的定義. head, tail分別指向頭尾指針. len代表鏈表中的結點. count指的是整個quicklist中的所有ziplist中的entry的數目. fill字段影響著每個鏈表結點中ziplist的最大占用空間, compress影響著是否要對每個ziplist以LZ4算法進行進一步壓縮以更節省內存空間.
quicklistIter是一個迭代器
quicklistEntry是對ziplist中的entry概念的封裝. quicklist作為一個封裝良好的數據結構, 不希望使用者感知到其內部的實現, 所以需要把ziplist.entry的概念重新包裝一下.
quicklist的內存布局圖如下所示:
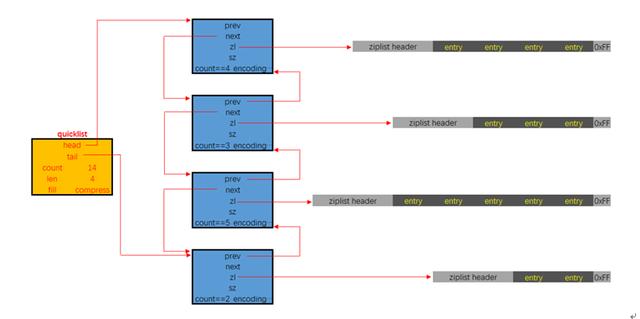
下面是有關quicklist的更多額外信息:
quicklist.fill的值影響著每個鏈表結點中, ziplist的長度.
當數值為負數時, 代表以字節數限制單個ziplist的最大長度. 具體為:
-1 不超過4kb
-2 不超過 8kb
-3 不超過 16kb
-4 不超過 32kb
-5 不超過 64kb
當數值為正數時, 代表以entry數目限制單個ziplist的長度. 值即為數目. 由于該字段僅占16位, 所以以entry數目限制ziplist的容量時, 最大值為2^15個
quicklist.compress的值影響著quicklistNode.zl字段指向的是原生的ziplist, 還是經過壓縮包裝后的quicklistLZF
0 表示不壓縮, zl字段直接指向ziplist
1 表示quicklist的鏈表頭尾結點不壓縮, 其余結點的zl字段指向的是經過壓縮后的quicklistLZF
2 表示quicklist的鏈表頭兩個, 與末兩個結點不壓縮, 其余結點的zl字段指向的是經過壓縮后的quicklistLZF
以此類推, 最大值為2^16
quicklistNode.encoding字段, 以指示本鏈表結點所持有的ziplist是否經過了壓縮. 1代表未壓縮, 持有的是原生的ziplist, 2代表壓縮過
quicklistNode.container字段指示的是每個鏈表結點所持有的數據類型是什么. 默認的實現是ziplist, 對應的該字段的值是2, 目前Redis沒有提供其它實現. 所以實際上, 該字段的值恒為2
quicklistNode.recompress字段指示的是當前結點所持有的ziplist是否經過了解壓. 如果該字段為1即代表之前被解壓過, 且需要在下一次操作時重新壓縮.
quicklist的具體實現代碼篇幅很長, 這里就不貼代碼片斷了, 從內存布局上也能看出來, 由于每個結點持有的ziplist是有上限長度的, 所以在與操作時要考慮的分支情況比較多. 想想都蛋疼.
quicklist有自己的優點, 也有缺點, 對于使用者來說, 其使用體驗類似于線性數據結構, list作為最傳統的雙鏈表, 結點通過指針持有數據, 指針字段會耗費大量內存. ziplist解決了耗費內存這個問題. 但引入了新的問題: 每次寫操作整個ziplist的內存都需要重分配. quicklist在兩者之間做了一個平衡. 并且使用者可以通過自定義quicklist.fill, 根據實際業務情況, 經驗主義調參.
8、zipmap
dict作為字典結構, 優點很多, 擴展性強悍, 支持平滑擴容等等, 但對于字典中的鍵值均為二進制數據, 且長度都很小時, dict的中的一坨指針會浪費不少內存, 因此Redis又實現了一個輕量級的字典, 即為zipmap.
zipmap適合使用的場合是:
鍵值對量不大, 單個鍵, 單個值長度小
鍵值均是二進制數據, 而不是復合結構或復雜結構. dict支持各種嵌套, 字典本身并不持有數據, 而僅持有數據的指針. 但zipmap是直接持有數據的.
zipmap的定義與實現在src/zipmap.h與src/zipmap.c兩個文件中, 其定義與實現均未定義任何struct結構體, 因為zipmap的內存布局就是一塊連續的內存空間. 其內存布局如下所示:
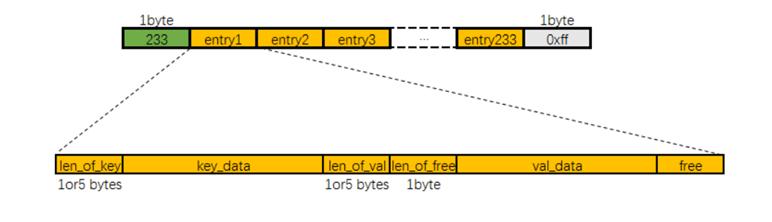
zipmap起始的第一個字節存儲的是zipmap中鍵值對的個數. 如果鍵值對的個數大于254的話, 那么這個字節的值就是固定值254, 真實的鍵值對個數需要遍歷才能獲得.
zipmap的最后一個字節是固定值0xFF
zipmap中的每一個鍵值對, 稱為一個entry, 其內存占用如上圖, 分別六部分:
len_of_key, 一字節或五字節. 存儲的是鍵的二進制長度. 如果長度小于254, 則用1字節存儲, 否則用五個字節存儲, 第一個字節的值固定為0xFE, 后四個字節以小端序uint32_t類型存儲著鍵的二進制長度.
key_data為鍵的數據
len_of_val, 一字節或五字節, 存儲的是值的二進制長度. 編碼方式同len_of_key
len_of_free, 固定值1字節, 存儲的是entry中未使用的空間的字節數. 未使用的空間即為圖中的free, 它一般是由于鍵值對中的值被替換發生的. 比如, 鍵值對hello <-> word被修改為hello <-> w后, 就空了四個字節的閑置空間
val_data, 為值的數據
free, 為閑置空間. 由于len_of_free的值最大只能是254, 所以如果值的變更導致閑置空間大于254的話, zipmap就會回收內存空間.