Redis 中的 Set,底層采用了什么數據結構?
在 Redis中,Set(集合)以其獨特的特性和高效的操作模式,在實際應用中得到了廣泛的使用。本文將深入分析 Redis Set 的原理、源碼實現,并通過示例展示其在實際應用中的使用方式。

一、什么是 Redis Set?
在 Redis 中,Set 是一種無序且不允許重復元素的數據結構,它支持豐富的集合操作,如交集、并集和差集等。這使得 Redis Set 非常適合用于社交網絡中的好友列表、標簽管理、實時推薦系統等場景。
Redis Set 的特點:
- 無序性:Set 中的元素是無序的,這意味著無法通過索引訪問特定元素。
- 唯一性:Set 中的每個元素都是唯一的,重復元素會被自動去重。
- 高效的元素操作:Redis 提供了豐富且高效的命令用于對 Set 進行操作,如添加、刪除、獲取元素等。
- 豐富的集合操作:支持集合的交集、并集、差集等高級操作。
二、底層實現原理
Redis 對 Set 的實現高度優化,以滿足不同場景下的性能需求,具體來說,Redis 使用了兩種內部數據結構來表示 Set:
- 整數集合(Intset)
- 哈希表(Hashtable)
1. Intset(整數集合)
當一個 Set 中的所有元素都是整數,并且數量較少時,Redis 會選擇使用 Intset 來存儲。這種表示方式節省內存,并且在元素較少的情況下提供了較快的訪問速度。
結構特點:
- 連續存儲:Intset 使用連續的內存塊存儲整數,類似于一個整數數組。
- 有序性:為了優化查找操作,Intset 會保持內部元素的有序性,使得二分查找成為可能。
- 內存緊湊:由于只是存儲連續的整數,內存占用較低。
Intset 的優勢:
- 節省內存:對于小規模的整數 Set,Intset 比哈希表節省大量內存。
- 快速查找:有序的結構使得二分查找的時間復雜度為 O(log N)。
Intset 的限制:
- 僅支持整數:如果 Set 中包含非整數元素,無法使用 Intset。
- 動態擴展限制:當元素數量超過閾值,或者出現非整數元素時,需要轉換為哈希表。
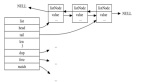
2. Hashtable(哈希表)
當 Set 中包含非整數元素,或元素數量超過某個閾值時,Redis 會將 Set 的內部實現轉換為哈希表。這種表示方式雖然在內存占用上稍大,但是支持更豐富的操作和更大的元素規模。
結構特點:
- 散列表存儲:使用開放定址哈希表來存儲元素,支持快速的插入、刪除和查找。
- 支持多種元素類型:不僅支持整數,還支持字符串等其他數據類型。
- 無序性:與 Intset 一樣,哈希表中的元素也是無序的。
Hashtable 的優勢:
- 高效的操作:哈希表提供了接近 O(1) 的時間復雜度,適用于大規模數據操作。
- 靈活性強:支持多種數據類型,適用于不同的應用場景。
Hashtable 的限制:
- 內存占用較大:相比 Intset,哈希表的內存消耗更高。
- 無序性:盡管支持高效的操作,但無法保證元素的順序。
3. 內部轉換機制
Redis 為了優化性能和內存利用,會根據 Set 的實際內容和規模動態地在 Intset 和 Hashtable 之間進行轉換。具體來說:
- 從 Intset 到 Hashtable:當 Set 中的元素個數超過 set-max-intset-entries(默認 512),或者出現非整數元素時,會將內部表示從 Intset 轉換為 Hashtable。
- 從 Hashtable 到 Intset:當使用于 Hashtable 的元素數量降至 set-min-intset-entries(默認 128)以下,并且所有元素都是整數時,會將內部表示從 Hashtable 轉換為 Intset。
這種動態轉換機制保證了 Redis 在不同階段都能以最佳的方式管理 Set,兼顧性能和內存利用。
三、源碼分析
為了深入理解 Redis Set 的實現原理,我們需要分析 Redis 的源代碼。以下分析基于 Redis 6.0 版本,但大部分實現邏輯在后續版本中保持穩定。
1. 數據結構定義
在 Redis 的源代碼中,Set 的實現主要涉及以下幾個關鍵數據結構:
- robj:Redis 的通用對象結構,用于表示不同的數據類型,包括 Set。
- intset:表示 Intset 的結構。
- dict:Redis 的哈希表實現,表示 Hashtable。
以下是相關結構的簡化定義。
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; // 最近使用時間
int refcount;
void *ptr;
} robj;
typedefstruct intset {
uint32_t encoding;
uint32_t length;
int32_t contents[];
} intset;
typedefstruct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
} dictEntry;
typedefstruct dicthdr {
int size;
dictEntry *table;
dictEntry **buckets;
// 其他成員...
} dict;2. 創建和銷毀 Set對象
當調用 SADD、SREM 等命令時,Redis 首先會檢查目標鍵是否存在。如果不存在,會調用 createSetObject 來創建一個新的 Set 對象。
- 創建 Set 對象的代碼片段:
robj *createSetObject(void) {
intset *is = intsetNew();
robj *o = createObject(OBJ_SET, is);
o->encoding = OBJ_ENCODING_INTSET;
return o;
}
intset *intsetNew(void) {
intset *is = malloc(sizeof(intset));
is->encoding = INTSET_ENC_INT32;
is->length = 0;
return is;
}- 銷毀 Set 對象的代碼片段:
void freeSetObject(robj *set) {
if (set->encoding == OBJ_ENCODING_INTSET) {
intsetDel(set->ptr);
} else {
dictRelease(set->ptr);
}
decrRefCount(set);
}3. Set 操作命令的實現
以 SADD 命令為例,其實現涉及以下幾個步驟:
(1) 查找或創建 Set 對象:如果目標鍵不存在,創建一個新的 Set 對象。
(2) 判斷編碼類型:根據當前 Set 的編碼類型(Intset 或 Hashtable),調用相應的添加元素函數。
(3) 添加元素:
- 如果是 Intset,嘗試將元素轉換為整數并添加;如果轉換失敗或超出容量,轉換為 Hashtable。
- 如果是 Hashtable,直接進行添加。
(4) 返回結果:返回成功添加的元素數量。
SADD 命令的關鍵實現代碼:
int setTypeAdd(robj *subject, robj *value) {
if (subject->encoding == OBJ_ENCODING_INTSET) {
longlong ll;
if (getLongLongFromObject(value, &ll)) {
if (intsetFind(subject->ptr, ll)) return0;
subject->ptr = intsetAdd(subject->ptr, ll, INTSET_NONE);
return1;
}
// 轉換為 hashtable
setTypeConvert(subject, OBJ_ENCODING_HT);
}
if (subject->encoding == OBJ_ENCODING_HT) {
dict *dict = subject->ptr;
return dictAdd(dict, value, NULL) == DICT_OK;
}
return0;
}4. Set的集合操作
Redis 支持多種集合操作,如交集(SINTER)、并集(SUNION)和差集(SDIFF)。這些操作通常涉及多個 Set 對象的迭代和元素比較。
以 SINTER 為例,其實現步驟如下:
- 獲取所有參與的 Set 對象。
- 選擇最小的 Set 作為基準以優化性能。
- 遍歷基準 Set 的元素,對每個元素在其他 Set 中進行查找。
- 將存在于所有 Set 中的元素添加到結果 Set。
- 返回結果。
SINTER 命令的關鍵實現代碼:
robj *sinterCommand(client *c) {
robj **sets = c->argv + 1;
int setnum = c->argc - 1;
robj *s = setTypeIntersection(sets, setnum);
addReplySet(c, s);
decrRefCount(s);
return C_OK;
}
robj *setTypeIntersection(robj **sets, int setnum) {
// 選擇最小的 Set 作為基準
robj *minset = selectMinSet(sets, setnum);
robj *result = createSetObject();
// 遍歷基準 Set 的元素
if (minset->encoding == OBJ_ENCODING_INTSET) {
intset *is = minset->ptr;
for (int i = 0; i < is->length; i++) {
longlong ll;
intsetGet(is, i, &ll);
robj *ele = createStringObjectFromLongLong(ll);
int exists = 1;
for (int j = 0; j < setnum; j++) {
if (j == index of minset) continue;
if (!setTypeIsMember(sets[j], ele)) {
exists = 0;
break;
}
}
if (exists) setTypeAdd(result, ele);
decrRefCount(ele);
}
} else {
// 哈希表遍歷邏輯
}
return result;
}5. 內部轉換邏輯
如前所述,當 Set 的大小或元素類型發生變化時,Redis 會在 Intset 和 Hashtable 之間轉換。這一過程涉及內存重新分配和數據拷貝。
從 Intset 到 Hashtable 的轉換:
void setTypeConvert(robj *set, int encoding) {
if (set->encoding == encoding) return;
if (encoding == OBJ_ENCODING_HT) {
dict *dict = dictCreate(&setDictType, NULL);
void *iter = setTypeInitIterator(set);
robj *ele;
while((ele = setTypeNext(set, iter)) != NULL) {
dictAdd(dict, ele, NULL);
}
setTypeReleaseIterator(iter);
set->encoding = OBJ_ENCODING_HT;
set->ptr = dict;
}
// 其他轉換邏輯...
}從 Hashtable 到 Intset 的轉換:
void setTypeConvertToIntset(robj *set) {
if (!setTypeCanEncodeIntset(set)) return;
intset *is = intsetNew();
dict *dict = set->ptr;
dictIterator *di = dictGetIterator(dict);
dictEntry *de;
while ((de = dictNext(di)) != NULL) {
longlong ll;
if (getLongLongFromObj(de->key, &ll)) {
is = intsetAdd(is, ll, INTSET_NONE);
} else {
dictReleaseIterator(di);
intsetDel(is);
return;
}
}
dictReleaseIterator(di);
dictRelease(set->ptr);
set->ptr = is;
set->encoding = OBJ_ENCODING_INTSET;
}6. 內存管理和優化
Redis 對 Set 的內存管理進行了深度優化,以確保在不同的使用場景下都能高效地利用內存。具體措施包括:
- 共享對象:對于經常使用的小整數,Redis 通過對象共享機制(Shared Objects)減少內存占用。
- 內存分配器優化:Redis 使用 jemalloc 作為默認的內存分配器,通過優化內存分配策略提升性能。
- 惰性刪除:在哈希表中刪除元素時,Redis 采用惰性刪除策略,避免高頻次的重新哈希操作。
四、Redis Set 的使用示例
為了更好地理解 Redis Set的實用性,下面我們將通過幾個具體的示例展示它在實際應用中的使用方式。
1. 用戶興趣標簽管理
假設有一個應用需要管理用戶的興趣標簽,Set 是理想的選擇,因為它能有效地保證標簽的唯一性,并支持高效的添加、刪除和查詢操作。
示例場景:
- 一個用戶可以擁有多個興趣標簽,如“音樂”、“編程”、“旅游”等。
- 用戶可以添加或刪除興趣標簽。
- 需要查詢用戶的所有興趣標簽。
Redis 命令示例:
# 添加興趣標簽
SADD user:1000:tags "音樂" "編程" "旅游"
# 刪除一個標簽
SREM user:1000:tags "旅游"
# 獲取所有標簽
SMEMBERS user:1000:tags
# 判斷用戶是否有某個標簽
SISMEMBER user:1000:tags "編程"示例解釋:
- SADD 命令用于添加一個或多個元素到 Set 中。重復的元素會被自動忽略。
- SREM 命令用于從 Set 中刪除一個或多個元素。
- SMEMBERS 命令返回 Set 中的所有成員。
- SISMEMBER 命令用于檢查一個元素是否存在于 Set 中。
2. 共同好友推薦
在社交網絡中,推薦共同好友是一個常見功能。Set 的交集操作為實現這一功能提供了高效的手段。
示例場景:
- 用戶 A 和用戶 B 的好友列表都是 Redis 的 Set。
- 需要找出 A 和 B 的共同好友數量。
Redis 命令示例:
# 用戶 A 的好友列表
SADD user:A:friends "User1" "User2" "User3" "User4"
# 用戶 B 的好友列表
SADD user:B:friends "User3" "User4" "User5" "User6"
# 獲取共同好友
SINTER user:A:friends user:B:friends示例解釋:SINTER 命令返回所有給定集合的交集成員。在本例中,即為用戶 A 和用戶 B 的共同好友。
3. 實時在線用戶統計
在實時應用中,經常需要統計當前在線的用戶列表。Set 的添加、刪除和計數功能使其成為理想的選擇。
示例場景:
- 當用戶上線時,將用戶 ID 添加到在線用戶 Set 中。
- 當用戶下線時,從 Set 中移除用戶 ID。
- 統計當前在線用戶數量。
Redis 命令示例:
# 用戶上線
SADD online_users "User1"
# 用戶下線
SREM online_users "User1"
# 獲取在線用戶數量
SCARD online_users
# 獲取所有在線用戶
SMEMBERS online_users示例解釋:SCARD 命令返回 Set 中的元素數量,用于統計在線用戶數量。
4. 關鍵詞去重
在數據處理過程中,常常需要對關鍵詞進行去重。Set 的唯一性保證了關鍵詞的唯一性,適合用于此類場景。
示例場景:從大規模文本中提取關鍵詞,并存儲到 Redis 的 Set 中,自動去除重復關鍵詞。
Redis 命令示例:
# 假設從文本中提取到以下關鍵詞
SADD keywords "redis" "數據庫" "緩存" "redis" "NoSQL"
# 獲取去重后的關鍵詞
SMEMBERS keywords示例解釋:重復的"redis"關鍵詞在 Set 中只會存儲一次,確保關鍵詞的唯一性。
五、擴展與高級功能
Redis Set 作為基礎的數據結構,還支持一些擴展和高級功能,進一步增強了其應用的靈活性和 powerfulness。
1. 集合的交集、并集和差集
Redis 提供了 SINTER, SUNION, SDIFF 等命令,用于執行集合的交集、并集和差集操作。這些操作在群組管理、標簽分析等場景中非常有用。
示例:
# 交集
SINTER group:admins group:active
# 并集
SUNION group:admins group:employees
# 差集
SDIFF group:admins group:external2. 隨機元素獲取
有時需要從 Set 中隨機獲取一個或多個元素,Redis 提供了 SRANDMEMBER 命令來滿足這一需求。
示例:
# 隨機獲取一個元素
SRANDMEMBER myset
# 隨機獲取兩個元素
SRANDMEMBER myset 23. 元素迭代
通過 SSCAN 命令,可以對 Set 進行迭代,適用于處理大規模 Set 的場景,有助于避免長時間阻塞 Redis 服務。
示例:
# 迭代 Set 中的元素
SSCAN myset 0 MATCH pattern* COUNT 1004. 結合其他數據結構
Redis 允許將 Set 與其他數據結構組合使用,構建更加復雜和高效的數據模型。例如,使用 Hash 和 Set 結合,管理用戶的詳細信息和興趣標簽。
示例:
# 存儲用戶詳細信息
HSET user:1000:name "Alice" user:1000:age 30
# 存儲用戶興趣標簽
SADD user:1000:tags "音樂" "編程" "旅游"
# 查詢用戶信息和興趣標簽
HGETALL user:1000:name
SMEMBERS user:1000:tags六、總結
本文,我們詳細分析了 Redis 的 Set數據結構,通過深入分析其底層實現原理,包括 Intset 和 Hashtable 的動態轉換機制,以及其相關的源碼,可以幫助我們更好地利用 Redis Set,實現高性能、高可靠的應用系統。