Redis 中的 List,底層采用了什么數據結構?
這篇文章,我們將從 Redis List 的基本原理出發,深入分析其內部實現機制、源碼層面的細節,并結合實際示例,全面解析 Redis List 的工作原理。

一、Redis List 概述
Redis 的 List 是一個簡單的字符串列表,按照插入順序排序。它支持在列表的兩端插入或刪除元素,具有以下特點:
- 有序:元素按照插入順序排列,可以通過索引訪問。
- 雙端操作:支持從左端(頭部)和右端(尾部)進行插入和刪除操作。
- 高效:在兩端插入和刪除的時間復雜度為 O(1)。
常用的 List 命令包括 LPUSH、RPUSH、LPOP、RPOP、LINDEX、LRANGE 等。
二、Redis List 的內部實現
Redis 的 List 數據結構內部實現主要依賴于兩個數據結構:壓縮列表(ziplist)和雙端鏈表(quicklist)。根據 List 的大小和元素的長度,Redis 會自動選擇合適的數據結構,以優化存儲空間和操作效率。
1. 壓縮列表
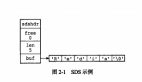
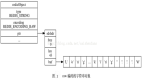
壓縮列表 是一種為節省內存而設計的緊湊數據結構。它將多個元素緊密存儲在一個連續的內存塊中,適用于小型的 List。
- 結構:壓縮列表由三個部分組成:ziplist header、entry list 和 ziplist end。
- 性能:適用于含有少量元素且每個元素較短的 List,節省內存但在頻繁插入和刪除時性能較低。

2. 雙端鏈表
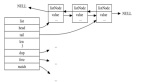
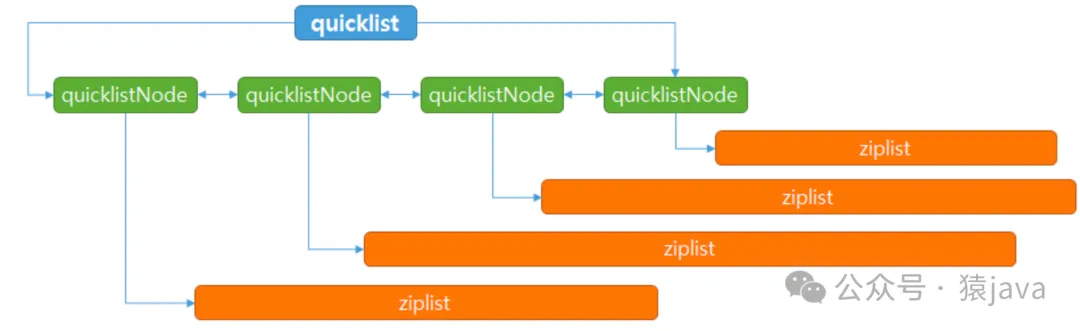
從 Redis 3.2 版本開始,List 的內部實現改為使用 quicklist,它結合了壓縮列表和雙向鏈表的優點。
結構:quicklist 是由多個壓縮列表(ziplist)組成的雙向鏈表,每個壓縮列表稱為一個節點(node)。
優勢:
- 高效插入與刪除:在兩端插入和刪除元素時,只需要操作鏈表的頭部或尾部節點,時間復雜度為 O(1)。
- 節省空間:每個節點內部仍然使用壓縮列表存儲元素,節省內存。
靈活性:適用于包含大量元素的 List。
三、源碼分析
下面將通過源碼分析 Redis List 的實現機制,重點關注 quicklist 相關的代碼部分。
1. 數據結構定義
Redis 在 src/quicklist.h 文件中定義了 quicklist 相關的數據結構。
// quicklist.h
typedefstruct quicklistEntry {
unsignedchar *value; /* value of the entry */
unsignedint sz; /* length of the value */
longlong longval; /* long representation, if applicable */
unsignedint encoding:4;
unsignedint attempted_float_conversion:1;
} quicklistEntry;
typedefstruct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsignedchar *zl; /* ziplist containing some entries */
unsignedint sz; /* byte size of ziplist */
unsignedint count:16;
unsignedint encoding:4;
unsignedint container:4;
unsignedint recompress:1;
} quicklistNode;
typedefstruct quicklist {
quicklistNode *head;
quicklistNode *tail;
const quicklistCompress *compress;
unsignedint count; /* total count of all entries in all the nodes */
unsignedlong len; /* count of all elements */
unsignedlong maxlevel;
unsignedint fill:16;
unsignedint compress_depth:4;
unsignedint mem_compressed:1;
} quicklist;主要的數據結構包括:
- quicklistEntry:表示 quicklist 中的一個條目(entry)。
- quicklistNode:表示 quicklist 中的一個節點,包含一個 ziplist。
- quicklist:整個 quicklist 結構,包含頭尾節點、統計信息等。
2. 常用命令的實現
以下將以 LPUSH、RPUSH、LPOP、RPOP、LINDEX、LRANGE 等命令為例,分析它們在源碼中的實現。
3. LPUSH 和 RPUSH
LPUSH 和 RPUSH 用于在 List 的左端和右端插入元素。它們在 quicklist 中的實現主要涉及調用 quicklistPush 函數。
// listOp.c
void quicklistPush(quicklist *quicklist, void *value, size_t sz, int where) {
// 省略參數檢查和類型轉換
if (where == QUICKLIST_HEAD) {
// 插入到鏈表頭部
// 如果頭節點已滿,創建新節點
} else {
// 插入到鏈表尾部
// 如果尾節點已滿,創建新節點
}
// 使用 ziplist 插入元素
// 更新統計信息
}核心邏輯:
- 判斷插入的位置(頭部或尾部)。
- 檢查對應位置的節點是否有足夠空間插入新元素。
- 如果節點已滿,創建一個新的節點并插入。
- 在對應節點的 ziplist 中插入新元素。
- 更新 quicklist 的統計信息。
4. LPOP 和 RPOP
LPOP 和 RPOP 用于從 List 的左端和右端彈出元素。它們主要調用 quicklistPopCustom 函數。
// listPop.c
int quicklistPopCustom(quicklist *quicklist, int where, long long *v, unsigned char **sval, unsigned int *slen) {
if (where == QUICKLIST_HEAD) {
// 從頭部節點的 ziplist 彈出元素
// 如果節點為空,刪除節點并移動到下一個節點
} else {
// 從尾部節點的 ziplist 彈出元素
// 如果節點為空,刪除節點并移動到前一個節點
}
// 更新統計信息和 quicklist 結構
}核心邏輯:
- 根據彈出的位置,選擇頭部或尾部節點。
- 從對應節點的 ziplist 中彈出元素。
- 如果節點為空,刪除節點并更新鏈表指針。
- 更新 quicklist 的統計信息。
5. LINDEX
LINDEX 用于獲取 List 中指定索引的元素。它調用 quicklistIndex 函數。
// listIndex.c
quicklistEntry *quicklistIndex(quicklist *quicklist, long index) {
// 處理負索引
// 遍歷 quicklist 中的節點,累加節點中元素的數量
// 找到包含目標索引的節點
// 在節點的 ziplist 中查找具體的元素
}核心邏輯:
- 處理負索引(從尾部開始計數)。
- 遍歷 quicklist 的節點,累加每個節點的元素數量。
- 確定目標索引所在的節點。
- 在該節點的 ziplist 中查找目標元素。
6. LRANGE
LRANGE 用于獲取 List 中指定范圍的元素。它調用 quicklistGetRange 函數。
// listRange.c
quicklistIter *quicklistGetIterator(quicklist *quicklist, int direction) {
// 創建一個迭代器,從頭部或尾部開始遍歷 quicklist
}
int quicklistNext(quicklistIter *i, quicklistEntry *entry) {
// 通過迭代器遍歷 quicklist 中的元素
}核心邏輯:
- 創建一個迭代器,指定遍歷方向(從頭到尾或從尾到頭)。
- 遍歷 quicklist 的節點和節點內的 ziplist,收集指定范圍的元素。
- 返回結果集合。
四、性能優化與選擇
Redis 在 List 的內部實現中,通過 quicklist 結構在節省內存和提高操作效率之間取得了平衡。以下是一些性能優化的考慮:
- 節點大小(fill factor):quicklist 中每個節點的 ziplist 有一個填充因子(默認是 4),決定了多少元素被存儲在一個節點中。適當的填充因子可以減少節點數量,提高遍歷效率。
- 壓縮算法:quicklist 支持多種壓縮算法,通過配置可以進一步優化內存使用。
- 迭代器機制:通過迭代器遍歷 quicklist,提高了操作的靈活性和效率。
在選擇使用 List 時,應根據實際需求和數據規模合理設計,避免在極大的 List 上進行頻繁的中間位置插入和刪除操作,因為這可能導致性能下降。
五、為什么List底層有兩種實現
List 數據結構的底層采用了 壓縮列表(ziplist) 和 雙端鏈表(quicklist) ,其實是 內存效率 與 操作性能 之間取得最佳平衡。主要原因如下:
1. 壓縮列表
內存節省:壓縮列表是一種為節省內存而設計的緊湊數據結構。它將多個元素緊密存儲在一個連續的內存塊中,避免了傳統鏈表中每個節點需要額外指針(如前驅和后繼指針)帶來的內存開銷。對于包含少量元素且每個元素較短的小型列表,壓縮列表能夠顯著減少內存使用量。
緩存友好性:由于壓縮列表將所有元素存儲在一個連續的內存區域中,這種布局有助于提升緩存命中率。CPU 在訪問數據時,能夠更高效地預取和緩存數據,從而提高訪問速度。
簡單數據結構:壓縮列表的實現相對簡單,適用于不需要頻繁插入和刪除操作的場景。對于靜態或變化不大的小型列表,壓縮列表提供了足夠的性能和內存效率。
2. 雙端鏈表
高效的兩端操作:雙端鏈表允許在列表的頭部和尾部進行高效的插入和刪除操作,時間復雜度為 O(1)。這對于需要頻繁在兩端進行操作的應用場景(如隊列和棧)尤為重要。
動態擴展能力:與壓縮列表相比,雙端鏈表更適合處理動態變化較大的列表。它能夠靈活地在任意位置插入和刪除元素,而不會像壓縮列表那樣需要整體移動內存塊。
分段存儲與性能優化:Quicklist 通過將列表分段存儲,每個段使用壓縮列表(ziplist)作為節點,實現了分塊管理。這種設計兼具了壓縮列表的內存效率和雙端鏈表的操作性能。具體來說,每個 quicklist 節點內部是一個壓縮列表,多個節點通過雙端鏈表連接起來。這樣,在需要進行插入或刪除操作時,僅需操作相關的節點,而不影響整個列表結構。
Redis 會根據列表的長度和元素的大小,自動決定使用壓縮列表還是雙端鏈表。這種智能選擇機制確保了在不同場景下都能獲得最佳的性能和內存使用率。例如:
- 小型列表:當列表較小且元素較短時,Redis 會選擇壓縮列表,最大化內存節省和緩存效率。
- 大型列表:當列表變得較大或元素較長時,Redis 會轉而使用 quicklist,以提升操作性能和擴展能力。
六、總結
本文,我們從源碼角度分析了 Redis 的 List 數據結構,它是一個高效、靈活的數據結構,適用于多種應用場景,如消息隊列、任務管理等。通過內部的 quicklist 結構,Redis 在節省內存和優化操作效率方面做出了平衡。通過學習本文,我們也可以發現 Redis 對性能的追求。