













剛剛,OpenAI首個L3級智能體深夜覺醒!AI自己玩電腦引爆全網,AGI一觸即發
剛剛,OpenAI首個智能體終于亮相了!
奧特曼帶領團隊毫無預警地開啟半小時「Operator」在線直播,首次揭秘能像人類一樣使用電腦的AI。
 Sam Altman,Yash Kumar,Casey Chu,Reiichiro Nakano
Sam Altman,Yash Kumar,Casey Chu,Reiichiro Nakano
演示中,AI智能體不僅可以精準理解指令,還能自主完成各類任務。
而它的獨特之處在于,可以直接與網頁交互——打字、點擊、滾動,幾乎一氣呵成。
比如,自動填寫繁瑣的在線表單、上網購物、創建表情包、處理重復性瀏覽器任務等等。
 圖片
圖片
「Operator」背后操盤手便是Computer-Using Agent (CUA),打破了特定編程接口的局限,像人類一場直接與GUI進行交互。
從此,通往AGI道路上的又一大瓶頸被掃除。智能體可以在數字世界中四處行動了!
OpenAI官博將此稱為,AI與數字世界的「通用界面」。
 圖片
圖片
「Operator」究竟有多厲害?
在多個測試環境中,CUA成功率令人瞠目:在OSWORLD上完成計算機使用任務成功率高達38.1%,比此前SOTA提升近16%;在WebArena上完成瀏覽器使用任務成功率達到58.1%,性能飆升22%。
不過與人類(72.4%和78.2%)相較之下,AI的能力還是有所差距。
在WebVoyager上,CUA更是達到了驚人的87%。
 圖片
圖片
好消息是,「Operator」終于上線。而壞消息是,目前只有Pro美國用戶才能體驗。
為了彌補這一遺憾,奧特曼提前劇透了,o3-mini直接在ChatGPT中「開源」,Plus用戶會有更多用量。
") 雖然但是,我們其實也可以用國產「Operator」替代一波(手動狗頭)
雖然但是,我們其實也可以用國產「Operator」替代一波(手動狗頭)
隨著Operator的正式發布,總裁Greg也再一次強調,「2025年,就是智能體之年」。
 圖片
圖片
話不多說,直接上演示。
AI接管PC訂餐,但直播小翻車
我們可以在Operator中選擇OpenTable,讓它訂一張今晚7點在Beretta的兩人位子。
可以看到,輸入查詢后,Operator會實例化指令,創建在云端運行的瀏覽器操作。
 圖片
圖片
隨后,Operator轉到了搜索Beretta的URL。非常令人驚喜的是,OpenTable默認的地址是弗吉尼亞,但它自動更正為舊金山。
再比如,我們做飯需要雞蛋、菠菜、雞大腿和辣椒。在紙上寫下這些食材后,就可以直接傳給Operator,同時告訴他我們偏好的商店是Gus。
 圖片
圖片
在這種情況下,Operator很快就根據GPT-4o的視覺功能理解了圖中的意思,還明白Gus商店是哪里。
接下來,就像OpenTable一樣,它實例化了一個瀏覽器,然后開始了購買環節。
 圖片
圖片
如果在以前,如果我們想用智能體執行類似操作,就必須確定特定網站有API,并且這個API有一切所需的功能,然而,大部分網站都是沒有API的。
而CUA通過教模型使用我們日常使用的基本界面,它就解鎖了一系列以前無法訪問的軟件!
可以看到,在執行操作的過程中,Operator進行了一些內在獨白,總結出了思維鏈。
然后它選擇了雞蛋,點擊了添加按鈕。而且每執行一個操作還會給電腦截個圖,這樣它就知道自己的操作對電腦有什么影響。
接下來,它點擊搜索框,輸入菠菜。這種采取行動、抓取屏幕截圖、創建子計劃的循環會一直持續,直到任務完成。
 圖片
圖片
當然,人類也可以隨時接過Operator的控制權,這就保證了用戶隨時可以控制Operator,并向它發出指令。
有趣的是,人類接管之后,Operator并不能看到我們在接管模式下做的事——這就保證了私密性。
接下來,OpenAI的研究者給它下達了一項新任務:用StubHub買四張本周末舊金山勇士隊比賽、票價500以下的門票。
非常真實的是,Operator小翻車了一下。
那就讓它試試,買明早圣瑪麗澳網公開賽的門票。Operator立馬打開引擎,展開搜索。
 圖片
圖片
隨后,研究者們讓Operator定10個中等披薩,指令發出后,它會主動向人類確認任務。
 圖片
圖片
而在實際購買時,也會需要人類登錄自己的賬號,才能完成下一步操作。
問題來了:如果Operator買錯東西、訂錯酒店了怎么辦呢?不用擔心,這種情況下,人類需要隨時確認,它才能繼續行動。
如果它遇到詐騙網站,對此還會有一個提示注入監視器,功能跟防病毒軟件一樣,可以觀察和監視它的操作,遇到可疑之處立馬停止。
L3級AGI達成,開啟下一場人機交互革命
支撐Operator的核心技術Computer-Using Agent(CUA),被訓練用于與圖形用戶界面GUI(在屏幕上看到的按鈕、菜單和文本框)進行交互,就像人類一樣。這就讓它具有了很高的靈活性,無需依賴操作系統或特定網頁API,從而能夠完成各種數字化任務。
更進一步的,通過將高級GUI感知與結構化問題解決能力結合在一起,CUA還可以將任務分解為多步驟計劃,并在遇到挑戰時自適應糾錯。
CUA能夠如此之強,是因為建立在OpenAI多年關鍵研究——多模態、推理和安全性領域基礎之上。通過融合GPT-4o的視覺能力、深度推理技術和創新的強化學習方法,研發團隊攻克了AI操作計算機的諸多技術難關。
其最大的突破在于,實現了通用界面。
傳統AI往往被局限于專門的API,而CUA可以像人類一樣操作任何軟件工具。這意味著,AI能適應幾乎所有的計算機環境,解決AI長期以來難以觸及的「長尾」數字使用場景。
還記得此前,彭博爆料的OpenAI內部AGI路線圖嗎?Operator的出世,意味著L3級智能體時代正式開啟!
 圖片
圖片
下一個目標,OpenAI還將擴展智能體的動作空間。接下來幾周/幾個月,我們還將會看到更多的智能體。
 圖片
圖片
此外,他們還計劃開放API接口,讓開發者能夠基于CUA構建自定義的計算機智能體。
OpenAI下場智能體Operator,或許將成為下一場人機交互革命的起點。
計算機使用智能體:AI與數字世界交互的通用界面
那么,CUA具體是如何工作的?
 圖片
圖片
技術報告:https://cdn.openai.com/operator_system_card.pdf
如下是它的工作原理圖,CUA會通過處理「原始像素數據」來理解屏幕上顯示的內容,并使用虛擬鼠標和鍵盤完成操作。
它可以執行多步驟任務、應對錯誤并適應意外變化。
 圖片
圖片
基于這些優勢,使得CUA能夠在各種數字環境中發揮作用,比如填寫表單和瀏覽網站,而無需依賴特定的API。
根據用戶的指令,CUA通過一個結合感知、推理和行動的迭代循環來運行:
- 感知:從計算機截取的屏幕快照被添加到模型的上下文中,為其提供當前計算機狀態的視覺參考。
- 推理:CUA使用思維鏈(CoT)推斷下一步操作,同時考慮當前和過去的屏幕快照及其執行的操作。這種內在獨白通過讓模型評估觀察內容、跟蹤中間步驟并進行動態調整來提高任務完成的效果。
- 行動:CUA執行操作——點擊、滾動或輸入——直到判斷任務完成或需要用戶輸入。盡管它可以自動完成大多數步驟,但對于敏感操作(如輸入登錄信息或處理驗證碼表單),CUA會尋求用戶確認。
刷新SOTA,但與人類差一大截
CUA在計算機使用和瀏覽器使用的基準測試中,通過使用統一的屏幕、鼠標和鍵盤界面,刷新了SOTA。

瀏覽器使用
WebArena和WebVoyager專為評估網頁瀏覽AI智能體,在瀏覽器中完成現實任務的性能而設計。
- WebArena利用自托管的開源離線網站,模擬現實任務場景,例如電子商務、在線商店內容管理系統(CMS)以及社交論壇平臺等。
- WebVoyager則測試模型在亞馬遜、GitHub和Google地圖等在線實時網站上的任務完成表現。
在這些基準測試中,CUA通過同一個通用界面設定了新標準。該界面將瀏覽器屏幕視為「像素」,并通過鼠標和鍵盤執行操作。
如前所述,在基于網頁的任務中,CUA在WebArena上的任務成功率為58.1%,而在WebVoyager上達到了驚人的87%。
盡管CUA在任務相對簡單的WebVoyager上表現出較高的成功率,但在更復雜的基準測試(如WebArena)中,CUA仍需進一步優化,以縮小與人類表現之間的差距。
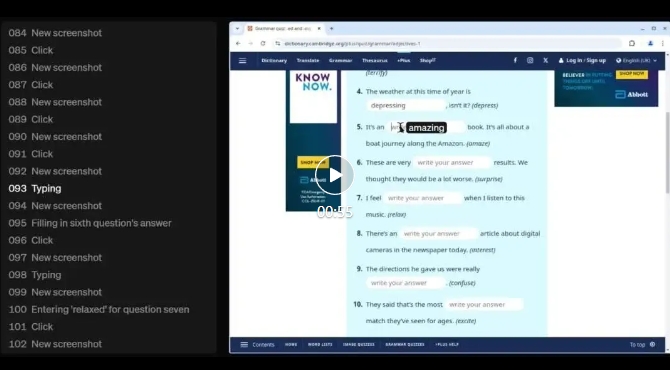
比如,讓CUA去「劍橋詞典的Plus專區,不用登錄,隨便做一個語法小測試,然后告訴我你考了多少分」。
只見AI一步一步找到測驗,并開始刷題,最終得到滿分12分。
在屏幕左側,可以清晰看到它每一步操作過程,其中「不斷截圖」(New screenshot)是支撐它完成任務的重要步驟。
生活中購物常會遇到退款問題,CUA也能算清楚。
給定一個完整的指令——我應該能從2023年2月取消的訂單中得到多少退款,包括運費?
CUA就會進入購物平臺one-stop-shop,打開「我的訂單」,并通過日期、訂單號查找所有可用的信息,然后計算得出退款總金額:406.53。

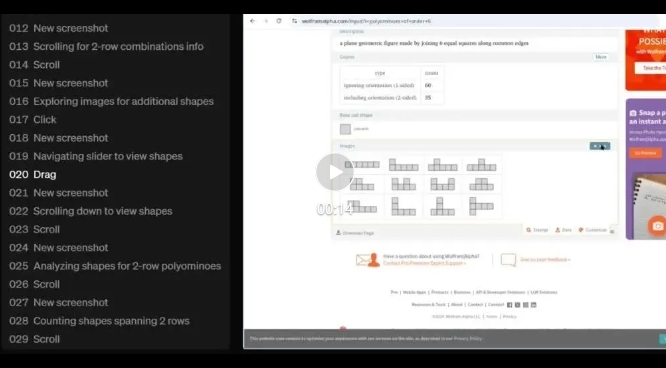
再比如,破解一個復雜推理題——6階多格骨牌(Polyominoes)組合方式,以及在所有形狀中,只有2行形狀有多少種。
CUA同樣是通過屏幕截圖,計算找到最終解:「在35種不同的6階多格骨牌組合中,有12種形狀只有兩行。」
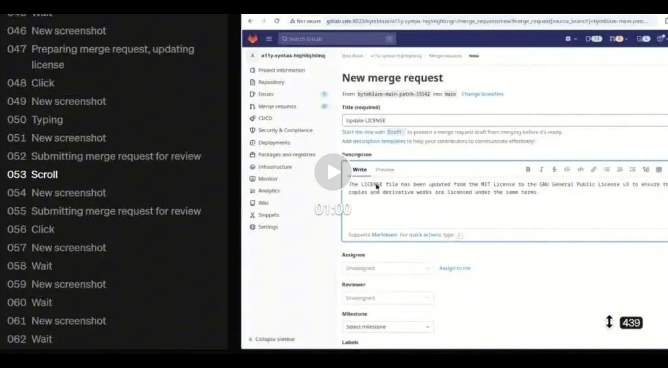
對于程序員們來說非常使用的場景——更新項目的許可,CUA也能做到。
計算機使用
OSWorld是一個評估模型控制完整操作系統(如Ubuntu、Windows和macOS)能力的基準測試。
在該基準測試中,CUA成功率達到了38.1%。
此外,研究人員還觀察到測試時的性能擴展(test-time scaling),即當允許更多操作步驟時,CUA性能會進一步提升。
下圖比較了CUA和之前SOTA模型在不同最大允許步驟下的表現。
人類在該基準測試中的表現為72.4%,因此CUA仍有顯著的改進空間。
 圖片
圖片
以下可視化示例展示了CUA如何完成多種標準化OSWorld任務。
假設你想要下載Python在線課程,目前已經成功下載Week 0課程講義,剩下幾周PDF文件的下載,完全可以交給AI去做。
這類重復性任務,AI最擅長不過了,而且你還會有大把時間去做別的事。

相比之下,在圖片壓縮的任務中,CUA似乎非常「糾結」。
在調節圖片質量時,不僅重復了數次「設為60%」,期間還一度出現了160%、360%這種奇怪的設定。
不過,在一番波折之后,CUA最終還是完成了任務。

CUA并非100%可靠
目前,OpenAI通過Operator研究預覽版提供了CUA——一種可以上網為你執行任務的智能體。
前面已經提到了,Operator目前也只面向美國的Pro用戶開放,入口是operator.chatgpt.com。
 圖片
圖片
與任何早期技術一樣,CUA還只是一個初出茅廬的AI,并不能在所有場景中穩定運行。
不過,它已經在多種情況下證明了其實用性,OpenAI希望將這種可靠性拓展到更多任務場景。
在下表中,他們展示了CUA在Operator中根據提示詞完成少量試驗的表現,以說明其已知的優勢和劣勢。
其中,OpenAI明顯指出:對于不同的網站和用戶界面,CUA可靠性會有所不同。
 圖片
圖片
CUA在執行簡單重復的UI工作比較擅長。
即便是同一個任務,CUA的可靠性可能會根據描述任務的方式而改變。在這種情況下,可以通過以下方式進行改進:
- 提供具體的時間細節(比如,用「上午9點到12點」而不是籠統地說「從上午9點開始的全天」)
- 提供關于應該使用哪些UI界面元素來查找結果的提示(比如,提示「查看篩選器部分」)
簡言之,越具體,AI更容易理解你的意圖。
 圖片
圖片
當CUA需要與它在訓練過程中很少接觸過的UI界面進行交互時,它很難準確判斷如何恰當地使用這些UI。
這通常會導致大量的試錯過程和低效的操作。
此外,CUA在文本編輯方面并不精確。它經常在處理過程中犯很多錯誤,或者提供帶有錯誤的輸出。
 圖片
圖片
所以,能自己用電腦的AI,對人類足夠安全嗎?
OpenAI是這么說的:在開發CUA時,他們將安全性作為了首要任務,以應對「智能體訪問數字世界所帶來的挑戰」。比如,它會拒絕「購買武器」之類的有害任務。
而在以后,通過收集的真實世界反饋,他們還會不斷改進安全措施。
















