硅谷對中國 AI 公司的焦慮越來越重,不只是因為 DeepSeek:2025 這些賽道更值得關注
大部分人可能想不到,2025 年的春節,大模型圈子竟然會這么熱鬧。
一切還要從十天前說起,DeepSeek 正式開源了 DeepSeek-R1,在數學、代碼和自然語言推理等任務上比肩 OpenAI o1 正式版。一眾 AI 研究者感到「震驚」,紛紛猜測這是如何做到的。英偉達市值幾千億美元級別的震蕩,更是讓全世界看得目瞪口呆。
關于 DeepSeek 技術創新的討論也非常多。很多人認為,DeepSeek 在硬件受限的條件下被逼走出了一條不同于 OpenAI 等狂堆算力的道路,用一系列技術創新來減少模型對算力的需求,同時獲得性能提升。
被「神秘的東方力量」DeepSeek 「硬控」之后,硅谷的態度耐人尋味:從一開始的盛贊,到后來的網絡攻擊和審查,足以折射出中國 AI 崛起帶給大洋彼岸的沖擊力。
這讓我們想起谷歌研究員早在 2023 年做出的悲觀預判:「我們沒有護城河,OpenAI 也沒有。」
如果往更深一層想,他們可能會發現,恐慌和焦慮的源頭早已種下,并不單單是一家 DeepSeek 造成的。
是時候重新審視中國大模型了,包括文心一言、豆包、可靈在內的所有玩家。

國產大模型,已經全面崛起
經歷了過去兩年的狂飆,中國大模型已經在多個垂直賽道中強勢崛起,跨過了護城河。
在 DeepSeek 之外,文心一言的 RAG 能力、可靈的文生視頻、豆包的語音生成等等,都已超越美國的對標模型。

最早可以從視頻生成領域的「超車」說起。OpenAI 在 2024 年春節期間發布了 Sora,去年也被稱為視頻生成技術的爆發之年。但在 6 月,可靈橫空出世,做到了文生視頻技術在產品落地層面的實質領先,第一次讓硅谷覺得「中國的 AI 技術有自己的優勢。」
我們意識到,中國可能不需要反復經歷「追趕 OpenAI」的游戲。后續的故事再次印證了這個觀點。
2024 年 5 月面世的 GPT-4o,給 ChatGPT 帶來實時語音通話能力,但真正全面開放這項功能后,用戶的實際體驗只能說普普通通。相比之下,2025 年初豆包實時語音大模型正式上線的時候,擬人度、有用性、情商、通話穩定性、對話流暢度等多個維度的表現都堪稱驚艷。且這項功能直接在豆包 App 全量開放、人人免費使用,補齊了國產大模型應用在「端到端語音系統」上的短板。
僅花費 550 萬美元訓練的 DeepSeek R1,又在這個春節假期前暴擊了 AI 圈。依靠沒有任何監督訓練的純強化學習路線,以及面向 H800 的大量優化創新,短短幾周內,就從 Deepseek-v3 基座進化到如今堪比 OpenAI o1 的思維鏈推理能力。
推理模型是當前最火熱的方向,只是這類模型也有自身的局限性:大模型推理是基于當前已知數據的,在遭遇錯誤的推理路徑時,模型可能會陷入死循環。這也是大模型提升檢索增強能力的意義所在。
相比于視頻生成、語音通話等能力,RAG(檢索增強生成)的概念對大眾可能更陌生一些,但這門結合了語言模型和信息檢索的技術,是當前大模型競爭的核心能力之一。
檢索增強是衡量大模型表現優劣的重要維度,而在這個領域,文心一言毫無疑問是國內 RAG 能力最領先的大模型應用。
作為國內搜索的頭部玩家,百度在這個領域有自己的節奏和路線。百度在文字 RAG 層面已經有多年技術積累,隨后又轉向了探索這門技術在多模態領域的應用。
前段時間,百度創新地將 RAG 技術拓展到了圖像領域,發布了自研的 iRAG(image-based RAG)技術,旨在降低文生圖的幻覺問題、提升 AI 生圖的準確性。這背后是百度搜索的億級圖片資源和強大的基礎模型能力。
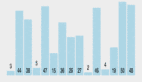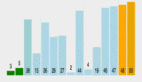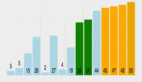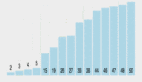
從文心一言的檢索增強 RAG ,看中國大模型彎道超車
百度基于搜索技術的積累在 RAG 上具備明顯優勢,推出了百度 AI 原生檢索,持續領先。從 RAG 能力實測來看,國內外主流大模型中,百度文心一言綜合表現最佳。
根據機器之心進行的一些實測,它甚至在很多任務上比 OpenAI 的 ChatGPT 表現更好。比如我們同時打開文心一言和 ChatGPT,能明顯感受出文心 RAG 的領先性。
測試中,即使是最新的春節檔電影細節、春晚節目等內容,文心都能準確回答;相比之下,OpenAI 雖能檢索到信源,卻無法生成準確回答:
比如《封神 2》中讓觀眾感染「看到殷郊就想笑」癥狀的三輪法相,文心一言能直接講出電影情節詳細的來龍去脈,而最新的 o3 mini 只能淺淺理解到法相是由 CG 技術做出來的表象。

今年春晚的語言類節目,由于時長限制,大家可能還有些意猶未盡。其實,近來有不少小品都是源自《一年一度喜劇大會》的精彩改編。文心一言不僅準確無誤地報出了改編節目的數量,甚至對《小明一家》將原版媽媽的角色改成了爺爺這一細節都了如指掌。o3 mini 這邊僅答對了一半,就顯得有些相形見絀了。

今年春晚熱度最高的節目還藏著一個冷知識 —— 宇樹機器人 H1 為大家扭秧歌,用的是兩種手絹。
仔細看,我們可以發現機器人在出場時,手里揮舞的是兩塊純色的紅手絹,而它們的手臂上纏著兩塊黑色的袖套,里面包裹著可以旋轉的技術手絹。在演出過程中,機器人手臂上的機關啟動,袖套和純色手絹被藏在了機器人身后,手上則像變魔術一樣,瞬間切換成了技術手絹。

這個彩蛋踩到了 o3 mini 的知識盲區,反觀「本地模型」文心一言,就了解得很清楚了。

對于最近發生的國際新聞,文心一言給出的事實更準確,信息更全面。再看 o3 mini 給出的這些不準確的數據,看來它和「幻覺」的斗爭可能還有很長的路要走。

這樣優秀的用戶體驗,是如何實現的?
相比于其他家大模型廠商,百度在 RAG 技術上具備中文深度理解、多模態檢索、垂直領域定制化以及實時數據整合能力等優勢,同樣是聯網檢索情況下,文心在中文互聯網、企業服務、政務等場景中更具實用性和競爭力。
具體來說,百度研發了「理解 - 檢索 - 生成」協同優化的檢索增強技術,顯著提升了大模型技術及應用的效果。理解階段,基于大模型理解用戶需求,對知識點進行拆解;檢索階段,面向大模型進行搜索排序優化,并將搜索返回的異構信息統一表示,送給大模型;生成階段,綜合不同來源的信息做出判斷,并基于大模型邏輯推理能力,解決信息沖突等問題,從而生成準確率高、時效性好的答案。
相信在 2025 年,RAG 技術還會再上一層樓,帶給用戶更好的體驗。
2025,國產大模型會迎來「高光時刻」嗎?
從近期大模型圈子的轟轟烈烈中,我們不難觀察到幾個趨勢:
1.曾經 OpenAI 諱莫如深的「技術黑盒」,正在被逐一破解。
在此之前,國內的很多大模型廠商均未能推出全面對標 OpenAI o1 的模型。DeepSeek 以一家大模型初創公司的身份,成為了第一個破解「OpenAI 技術黑盒」的玩家。
從復制 Sora 到復制 o1,包括快手和 DeepSeek 在內的中國大模型廠商都做到了。這些足以說明,OpenAI 昔日的諱莫如深,最終還是沒有起到護城河的作用。
面對國產大模型造成的轟動效應,知名 AI 研究者吳恩達近日表示:「中國在生成式人工智能方面正在趕超美國。2022 年 11 月推出 ChatGPT 時,美國在生成式 AI 方面遠遠領先于中國。印象的變化是很緩慢的,所以我一直聽到的是美國和中國的朋友都說他們認為中國落后了。但實際上,這種差距在過去兩年里迅速縮小了。借助 Qwen、Kimi、InternVL 和 DeepSeek 等來自中國的模型,中國顯然正在縮小差距,而在視頻生成等領域,中國似乎已經處于領先地位。 」
2.借助大量工程創新,國產大模型已經破除了對「英偉達 GPU」的迷信。
DeepSeek 是一項令人驚嘆的工程創新,團隊面臨諸多約束條件,卻依然利用更少的計算能力和資金拿出了 o1 級性能的成果。
對于美國的研究機構來說,他們不會花太多時間進行優化,因為英偉達一直在積極推出更強大的系統來滿足他們的需求,向英偉達付費就是最簡單的路線。
然而,DeepSeek 證明了另一條路線是可行的:在較弱的硬件和較低的內存帶寬上,大量優化可以產生顯著的效果 —— 在 GPU 上支付更多費用并不是打造更好模型的唯一方法。
3.當中國 AI 的競爭對手開始在意、壓制、攻擊,折射出的是對方關于被追趕、超越的恐慌。
在 DeepSeek R1 模型發布之后,有外媒報道 Meta 的生成式 AI 部門因此陷入到恐慌之中。
據傳,Meta 組建了 4 個團隊,試圖搞清楚 DeepSeek 是如何降低訓練和運行成本的,還有的團隊負責研究 DeepSeek 可能使用了哪些數據來訓練模型。也有團隊專門負責思考基于 DeepSeek 模型的屬性重組 Meta 模型的新技術,畢竟有爆料稱尚未發布的新一代開源模型 Llama 4 在基準測試中已經落后于 DeepSeek。
而 OpenAI 和微軟也開始調查 DeepSeek 這家競爭對手是否使用了 OpenAI 的 API 來訓練自己的模型。
很顯然,「中國 AI 元年」即將開啟,DeepSeek 春節期間的出圈是這個過程中的里程碑事件,但我們可以更多地著眼未來。
在剛剛開始的 2025 年,中國科技公司還將推出各種大模型,比如百度將推出文心 5.0。對此,你有哪些期待?