歷史時刻:DeepSeek GitHub星數超越OpenAI,僅用時兩個月
我們正在見證歷史:DeepSeek 項目在全球最大代碼托管平臺 GitHub 上的 Star 量超過了 OpenAI。
截至本周五下午兩點,DeepSeek 旗下熱度最高的項目 DeepSeek-V3 大模型 Star 量已達 7.77 萬,超越了同平臺中 OpenAI 最熱門項目。

DeepSeek 項目的星數還在以肉眼可見的速度增長。
去年 12 月 26 日,DeepSeek AI 開源了其最新混合專家(MoE)大語言模型 DeepSeek-V3,它立即成為通用語言模型的性能標桿,受到了全球 AI 社區熱議。
DeepSeek-V3 模型引入了動態注意力機制(Dynamic Attention Mechanism),通過實時調整注意力權重優化文本生成質量。其 MoE 架構共包含 6710 億參數,但每 Token 僅激活 370 億參數,大幅降低了計算成本,訓練成本僅為同類閉源模型的 1/20。
據技術報告介紹,DeepSeek-V3 的預訓練過程只花費 266.4 萬 H800 GPU Hours,再加上上下文擴展與后訓練的訓練共為 278.8 H800 GPU Hours(訓練成本 557.6 萬美元)。相較之下,Llama 3 的訓練預算約為 3930 萬 H100 GPU Hours。

圖源:https://arxiv.org/pdf/2412.19437
隨后在 1 月 23 日,DeepSeek 以 V3 為基礎使用強化學習(Reinforcement Learning)驅動重構訓練范式,提出了 DeepSeek-R1,徹底改變了開源 AI 世界。
DeepSeek R1 性能完全對標 OpenAI o1,與 DeepSeek V3 相比性能有大幅提升,其論文指出純強化學習可以賦予 LLM 強推理能力,而無需大量監督微調,震動了 AI 業界。
從技術角度來看,DeepSeek 展示了國內科研團隊的創新能力,并在 Scaling Laws 之后揭開了大模型發展的新范式,大幅降低了 AI 對算力的依賴,并用自我進化的方式平衡了數據優勢。
R1 還支持將推理能力遷移至更小模型,為邊緣計算和即時應用開辟了大量的可能性。
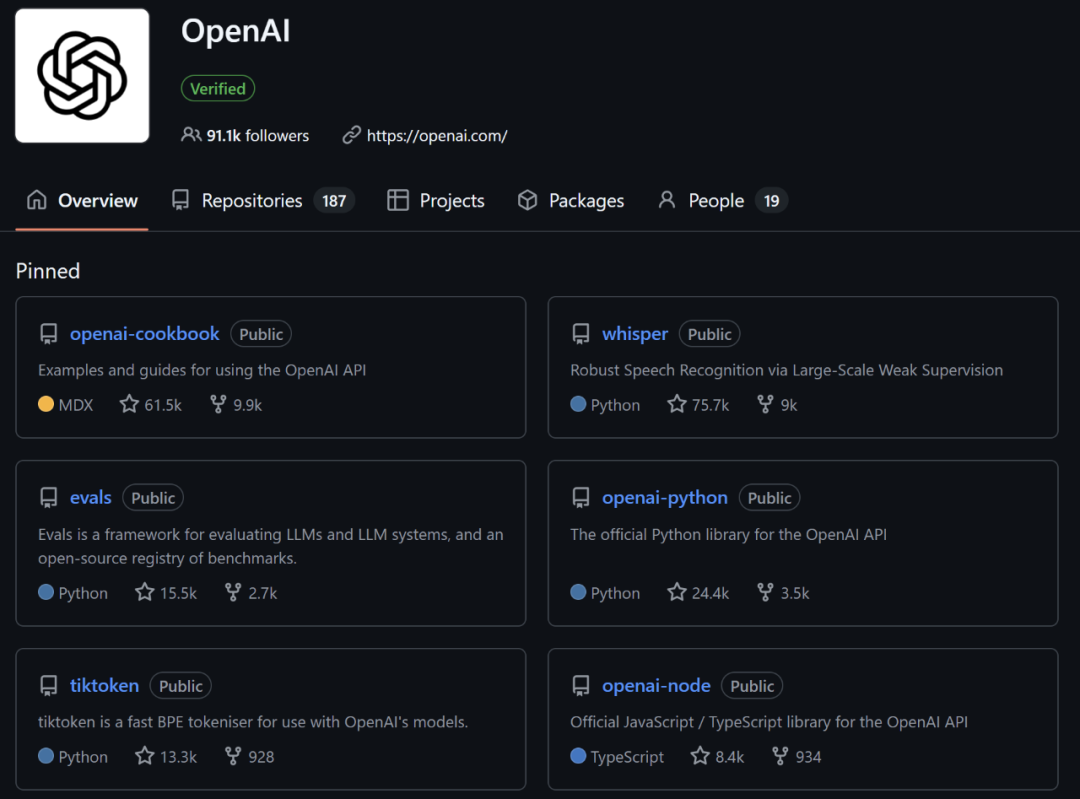
由于 OpenAI 自 GPT-3 起并未開源其基礎 AI 大模型,目前 OpenAI 的熱門開源項目包括 openai-cookbook,即使用 OpenAI API 完成常見任務的示例代碼和指南;以及 Whisper,這是一個 2022 年 9 月開源的通用語音識別模型。
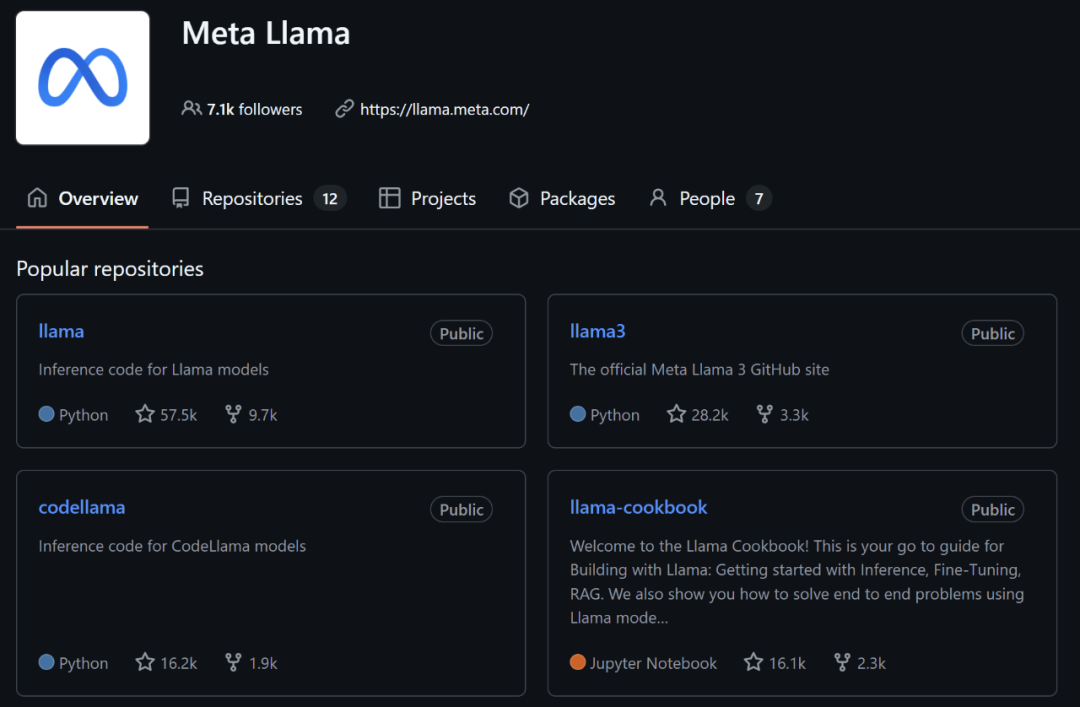
除此之外,同屬開源大模型的 Llama 系列最高星數達到了 5.75 萬,阿里云的 Qwen2.5 有 1.49 萬 Star,零一萬物的 Yi 有 7800 Star。
DeepSeek V3 和 R1 的推出仿佛為全球大模型社區打了一針強心劑,在 AI 研究領域,圍繞 R1 核心強化學習方法 GRPO 的進一步研究已經出現。
DeepSeek 開源的策略也為應用創造了大量機會。目前雖然 DeepSeek App 官方報告正在受到高頻次網絡攻擊,但僅在國內就有阿里云、華為云、騰訊云、百度智能云、360 數字安全、云軸科技等多個平臺宣布上線了 DeepSeek 大模型,方便各路開發者調用。
在海外,英偉達、亞馬遜和微軟云服務也宣布接入了 DeepSeek R1。
DeepSeek 系列模型被公認為是目前最先進的大語言模型之一,隨著技術開源的推動,我們或許將見證生成式 AI 更快的發展。