













一文讀懂多模態 embeddings
傳統上,AI研究被劃分為不同的領域:自然語言處理(NLP)、計算機視覺(CV)、機器人學、人機交互(HCI)等。然而,無數實際任務需要整合這些不同的研究領域,例如自動駕駛汽車(CV + 機器人學)、AI代理(NLP + CV + HCI)、個性化學習(NLP + HCI)等。
盡管這些領域旨在解決不同的問題并處理不同的數據類型,但它們都共享一個基本過程。即生成現實世界現象的有用數值表示。
歷史上,這是手工完成的。這意味著研究人員和從業者會利用他們(或其他人)的專業知識,將數據顯式轉換為更有用的形式。然而,今天,這些可以通過另一種方式獲得。在本文中,我將討論多模態embeddings,并通過兩個實際用例分享它們的功能。

Embeddings
embeddings是通過模型訓練隱式學習的數據的有用數值表示。例如,通過學習如何預測文本,BERT學習了文本的表示,這些表示對許多NLP任務很有幫助[1]。另一個例子是Vision Transformer(ViT),它在Image Net上進行圖像分類訓練,可以重新用于其他應用[2]。
這里的一個關鍵點是,這些學習到的embeddings空間將具有一些底層結構,使得相似的概念彼此接近。如下面的玩具示例所示。

文本和圖像embeddings的表示
前面提到的模型的一個關鍵限制是它們僅限于單一數據模態,例如文本或圖像。這阻止了跨模態應用,如圖像字幕生成、內容審核、圖像搜索等。但如果我們可以合并這兩種表示呢?
多模態 Embeddings
盡管文本和圖像在我們看來可能非常不同,但在神經網絡中,它們通過相同的數學對象(即向量)表示。因此,原則上,文本、圖像或任何其他數據模態都可以由單個模型處理。
這一事實是多模態embeddings的基礎,它將多個數據模態表示在同一向量空間中,使得相似的概念位于相近的位置(獨立于它們的原始表示)。
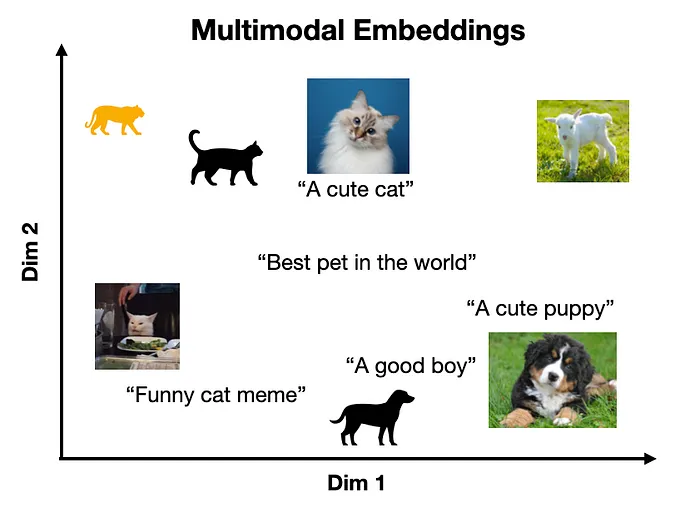
多模態embeddings空間的表示
例如,CLIP將文本和圖像編碼到共享的embeddings空間中[3]。CLIP的一個關鍵見解是,通過對齊文本和圖像表示,模型能夠在任意一組目標類上進行零樣本圖像分類,因為任何輸入文本都可以被視為類標簽(我們將在后面看到一個具體示例)。
然而,這個想法不僅限于文本和圖像。幾乎任何數據模態都可以以這種方式對齊,例如文本-音頻、音頻-圖像、文本-腦電圖、圖像-表格和文本-視頻。這解鎖了視頻字幕生成、高級OCR、音頻轉錄、視頻搜索和腦電圖到文本等用例[4]。
對比學習
對齊不同embeddings空間的標準方法是對比學習(CL)。CL的一個關鍵直覺是相似地表示相同信息的不同視圖[5]。
這包括學習表示,以最大化正對之間的相似性并最小化負對的相似性。在圖像-文本模型的情況下,正對可能是帶有適當標題的圖像,而負對可能是帶有不相關標題的圖像(如下所示)。

對比訓練中使用的正對和負對示例
CL的兩個關鍵方面促成了其有效性:
- 由于正對和負對可以從數據的固有結構(例如,網絡圖像的元數據)中策劃,CL訓練數據不需要手動標記,這解鎖了更大規模的訓練和更強大的表示[3]。
- 它通過特殊的損失函數同時最大化正對和最小化負對的相似性,如CLIP所示[3]。
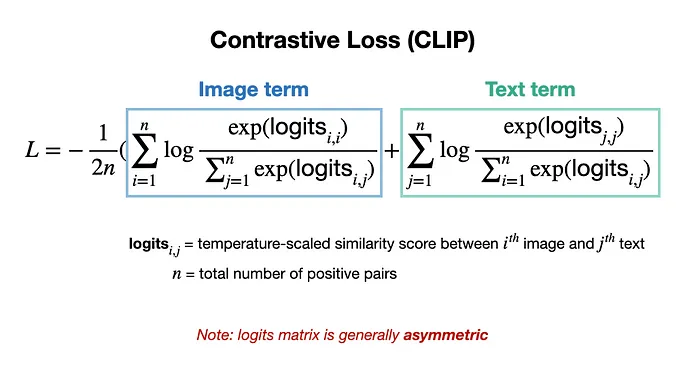
CLIP用于文本-圖像表示對齊的對比損失[3]
示例代碼:使用CLIP進行零樣本分類和圖像搜索
在了解了多模態embeddings的工作原理后,讓我們看看它們可以做的兩個具體示例。在這里,我將使用開源的CLIP模型執行兩個任務:零樣本圖像分類和圖像搜索。
這些示例的代碼在GitHub倉庫中免費提供:https://github.com/ShawhinT/YouTube-Blog/tree/main/multimodal-ai/2-mm-embeddings。
用例1:零樣本圖像分類
使用CLIP進行零樣本圖像分類的基本思想是將圖像與一組可能的類標簽一起傳遞給模型。然后,通過評估哪個文本輸入與輸入圖像最相似來進行分類。
我們首先導入Hugging Face Transformers庫,以便可以在本地下載CLIP模型。此外,PIL庫用于在Python中加載圖像。
from transformers import CLIPProcessor, CLIPModel
from PIL import Image接下來,我們可以導入一個版本的clip模型及其相關的數據處理器。注意:處理器處理輸入文本的標記化和圖像準備。
# import model
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch16")
# import processor (handles text tokenization and image preprocessing)
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch16")我們加載下面的貓的圖像,并創建兩個可能的類標簽列表:“一張貓的照片”或“一張狗的照片”。
# load image
image = Image.open("images/cat_cute.png")
# define text classes
text_classes = ["a photo of a cat", "a photo of a dog"]
輸入的貓照片
接下來,我們將預處理圖像/文本輸入并將它們傳遞給模型。
# pass image and text classes to processor
inputs = processor(text=text_classes, images=image, return_tensors="pt",
padding=True)
# pass inputs to CLIP
outputs = model(**inputs) # note: "**" unpacks dictionary items要進行類預測,我們必須提取圖像logits并評估哪個類對應于最大值。
# image-text similarity score
logits_per_image = outputs.logits_per_image
# convert scores to probs via softmax
probs = logits_per_image.softmax(dim=1)
# print prediction
predicted_class = text_classes[probs.argmax()]
print(predicted_class, "| Probability = ",
round(float(probs[0][probs.argmax()]),4))>> a photo of a cat | Probability = 0.9979模型以99.79%的概率準確識別出這是一張貓的照片。然而,這是一個非常簡單的例子。讓我們看看當我們將類標簽更改為:“丑貓”和“可愛貓”時會發生什么。
>> cute cat | Probability = 0.9703模型輕松識別出圖像確實是一只可愛的貓。讓我們做一些更具挑戰性的標簽,例如:“貓表情包”或“非貓表情包”。
>> not cat meme | Probability = 0.5464雖然模型對這個預測的信心較低,只有54.64%的概率,但它正確地暗示了圖像不是表情包。
用例2:圖像搜索
CLIP的另一個應用基本上是用例1的逆過程。與其識別哪個文本標簽與輸入圖像匹配,我們可以評估哪個圖像(在一組中)與文本輸入(即查詢)最匹配——換句話說,在圖像上執行搜索。我們首先將一組圖像存儲在列表中。在這里,我有三張貓、狗和山羊的圖像。
# create list of images to search over
image_name_list = ["images/cat_cute.png", "images/dog.png", "images/goat.png"]
image_list = []
for image_name in image_name_list:
image_list.append(Image.open(image_name))接下來,我們可以定義一個查詢,如“一只可愛的狗”,并將其與圖像一起傳遞給CLIP。
# define a query
query = "a cute dog"
# pass images and query to CLIP
inputs = processor(text=query, images=image_list, return_tensors="pt",
padding=True)然后,我們可以通過提取文本logits并評估對應于最大值的圖像來將最佳圖像與輸入文本匹配。
# compute logits and probabilities
outputs = model(**inputs)
logits_per_text = outputs.logits_per_text
probs = logits_per_text.softmax(dim=1)
# print best match
best_match = image_list[probs.argmax()]
prob_match = round(float(probs[0][probs.argmax()]),4)
print("Match probability: ",prob_match)
display(best_match)>> Match probability: 0.9817
查詢“一只可愛的狗”的最佳匹配
我們看到(再次)模型在這個簡單示例中表現出色。但讓我們嘗試一些更棘手的例子。
query = "something cute but metal ??">> Match probability: 0.7715
查詢“可愛但金屬的東西??”的最佳匹配
query = "a good boy">> Match probability: 0.8248
查詢“一個好男孩”的最佳匹配
query = "the best pet in the world">> Match probability: 0.5664
查詢“世界上最好的寵物”的最佳匹配
盡管最后一個預測頗具爭議,但所有其他匹配都非常準確。這可能是因為像這樣的圖像在互聯網上無處不在,因此在CLIP的預訓練中被多次看到。
接下來可以做什么?
多模態embeddings解鎖了涉及多個數據模態的無數AI用例。在這里,我們看到了兩個這樣的用例,即使用CLIP進行零樣本圖像分類和圖像搜索。像CLIP這樣的模型的另一個實際應用是多模態RAG,它包括自動檢索多模態上下文到LLM。在本系列的下一篇文章中,我們將了解其內部工作原理并回顧一個具體示例。
【參考文獻】
- [1] BERT:https://arxiv.org/abs/1810.04805
- [2] ViT:https://arxiv.org/abs/2010.11929
- [3] CLIP:https://arxiv.org/abs/2103.00020
- [4] Thought2Text: 使用大型語言模型(LLMs)從腦電圖信號生成文本:https://arxiv.org/abs/2410.07507
- [5] 對比學習視覺表示的簡單框架:https://arxiv.org/abs/2002.05709
























