













推理時也能做偏好優化,無需額外重訓練,來自上海AI Lab港中文等
隨著大語?模型(LLMs)在各類任務中展現出令人矚目的能力,如何確保它們?成的回復既符合預期又安全,始終是?項關鍵挑戰。
傳統的偏好對??法,如基于?類反饋的強化學習(RLHF)和直接偏好優化(DPO),依賴于訓練過程中的模型參數更新,但在?對不斷變化的數據和需求時,缺乏?夠的靈活性來適應這些變化。
為了突破這?瓶頸,上海人工智能實驗室、香港中文大學等聯合提出了推理時偏好優化(TPO)方法,通過在推理階段與獎勵模型交互,借助可解釋的文本反饋,迭代優化模型輸出,實現了即時的模型對?,??需重新訓練。
實驗結果表明,TPO能夠有效提升未對?模型的表現,甚?超越經過訓練的對?模型,為模型偏好對?提供了?種全新的思路。

△訓練時偏好優化VS推理時偏好優化
TPO特點
(1)推理時對?、?需訓練:TPO通過與獎勵模型的推理階段交互,實現即時對?偏好,無需更新模型參數。
(2)基于?本反饋:TPO使?可解釋的文本反饋(而非純數值梯度)來指導優化,讓模型“理解?并“執行”文本評價。
(3)優于傳統?法:在推理階段,未對?的模型(例如Llama-3.1-70B-SFT)經過數次TPO迭代,能夠持續逼近獎勵模型的偏好。在多個基準測試中,其表現甚至超越了已在訓練時對?的版本(例如Llama-3.1-70B-Instruct)。
(4)靈活適應性:TPO能夠靈活應對不斷變化的數據和需求,具有較強的適應性,并且能夠在資源有限的環境下?效運?。
研究方法

為實現這??標,已有多種方法用來實現評分函數,如RLHF和DPO通過訓練時偏好優化來對??類偏好。這些?法通過基于梯度的?法(如隨機梯度下降,SGD)優化模型參數(如神經?絡中的權重θ),使得?成符合?類偏好的輸出概率更?。每次更新的步驟如下:

TPO通過解釋和執行文本損失和文本梯度,為模型生成的回復提供可解釋的優化信號。
如圖所示,TPO包含四個關鍵組件,類似于標準的梯度優化?法:變量定義、損失計算、梯度計算和變量優化。
研究人員使用獎勵模型R作為人類偏好的代理,提供生成回復質量的反饋。在推理時對?過程中,系統通過迭代調整輸出,使其逐步更符合獎勵模型的偏好。

△測試時間偏好優化(TPO)框架(AlpacaEval2的真實示例)

該過程最多進行D次迭代,類似于訓練過程,稱為推理時訓練(test-time training)。最終,選擇緩存中評分最高的回復作為最終輸出。
實驗與結果
策略模型
- 未對齊模型:Llama-3.1-70B-SFT
- 已對齊模型:
-Llama-3.1-70B-Instruct
-Llama-3.1-70B-DPO(UltraFeedback訓練得來)
獎勵模型
- FsfairX-LLaMA3-RM-v0.1
- Llama-3.1-Tulu-3-8B-RM
benchmark與評價指標
- 指令跟隨:Alpaca Eval 2(原始勝率WR和長度控制勝率LC)和ArenaHard(勝率WR)
- 偏好對齊:HH-RLHF(采樣500條,FsfairX-LLaMA3-RM-v0.1的平均獎勵分數)
- 安全:BeaverTails-Evaluation(FsfairX-LLaMA3-RM-v0.1的平均獎勵分數)XSTest(WildGuard的準確率)
- 數學能力:MATH-500(使用0-shot配置和CoT提示,pass@1準確率)
推理時訓練效果
TPO在推理時對模型進行優化,通過少量的迭代步數逐漸擬合獎勵模型偏好,顯著提升未對齊模型的性能,使其達到與對齊模型相當的水平;在已對齊模型上,TPO進一步增強了對齊效果,而Revision版本(迭代優化選定回復而不參考被拒絕回復)的提升有限。

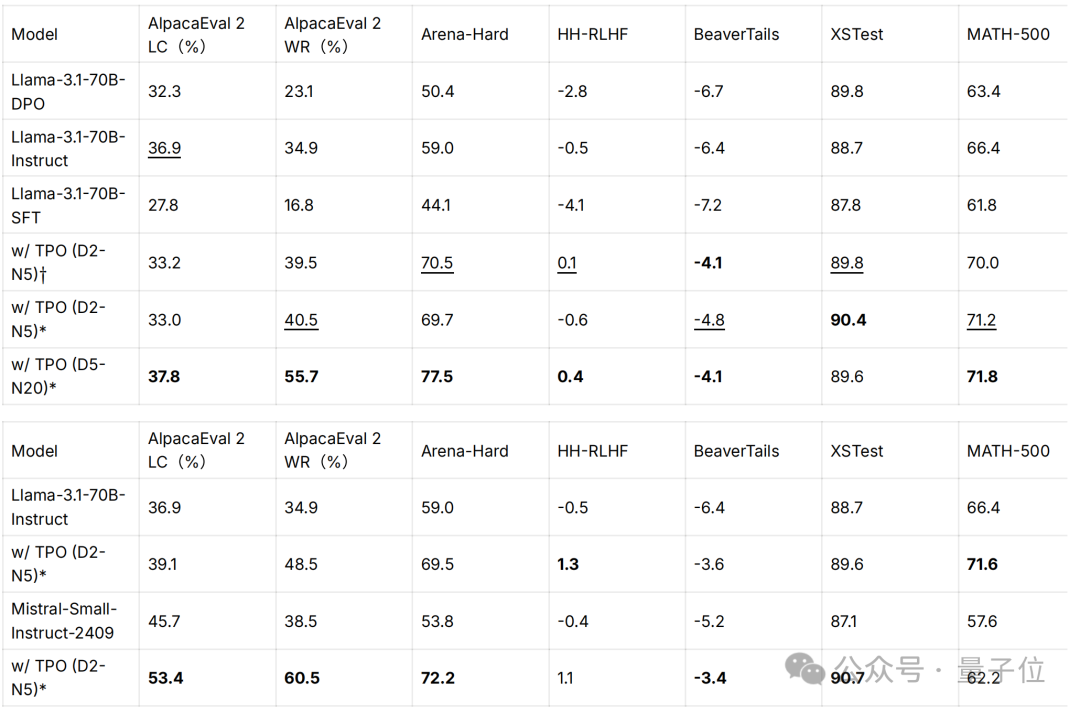
benchmark性能
TPO能夠顯著提升模型性能指標,未對齊模型通過TPO超越了訓練時對齊的模型,而對齊模型在經過TPO迭代后也獲得了進一步的優化。D和N分別表示最大迭代次數和樣本數量。
* 表示使用獎勵模型FsfairX-LLaMA3-RM-v0.1優化的模型,而?表示Llama-3.1-Tulu-3-8B-RM。
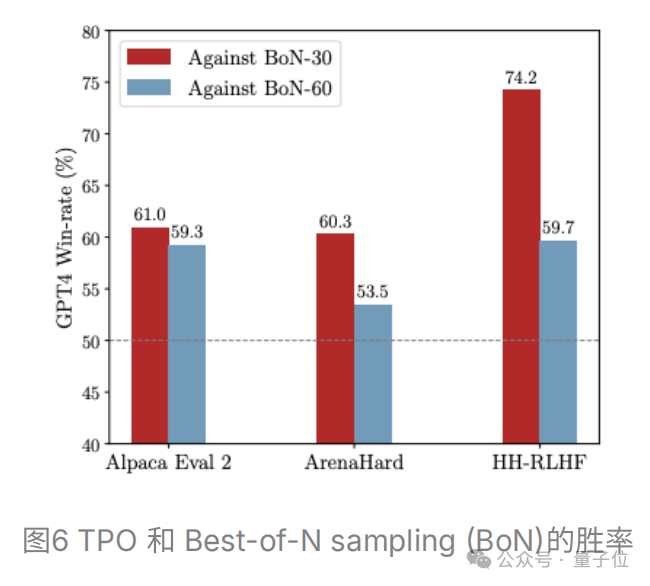
推理穩定性
TPO能夠有效地根據獎勵模型的反饋調整模型輸出,顯著改善推理穩定性,表現為采樣樣本的獎勵分數標準差的降低。

TPO的特性分析
TPO的寬度:增加TPO的搜索寬度(即每次TPO迭代中采樣的回復數量)能夠顯著提升性能,直到達到飽和。

TPO的深度:增加TPO的搜索深度比單純增加樣本數量更有效地發現更高質量的回復。
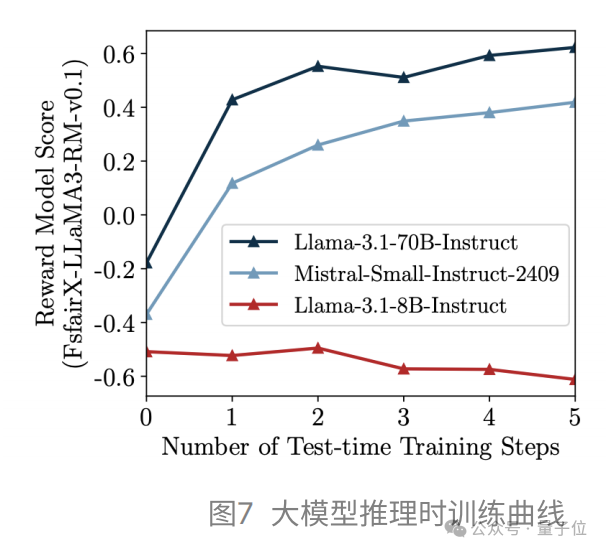
TPO的計算成本:TPO無需更改模型參數,與訓練時偏好優化相比,在計算成本上具有顯著優勢。TPO的計算成本(FLOPs)僅為一輪DPO訓練(64,000條數據)所需開銷的0.01%。而Instruct模型通常在百萬級語料上多輪迭代,訓練成本遠高于DPO,進一步凸顯了TPO在相對計算成本方面的優勢。
TPO的指令跟隨前提:TPO的成功依賴于策略模型具備基礎的指令跟隨能力,因為模型必須準確解釋和響應數值形式的獎勵模型偏好。
總結
提出推理時偏好優化(TPO)方法,通過在推理過程中與獎勵模型交互,將獎勵模型信號轉化為”文本損失”和”文本梯度”,以此迭代優化模型輸出。
無需重新訓練,即可讓大語言模型與人類偏好對齊。TPO為訓練時偏好優化提供了輕量、高效且可解釋的替代方案,充分利用了大語言模型在推理時的固有能力。
推理時優化的靈活性:TPO通過即時文本反饋實現推理時對?,增強了模型在多樣化場景中的適應能力,能快速響應變化的需求和任務的變化。此外,TPO充分利用大語言模型在推理、指令跟隨等方面的內在優勢,從?實現了更靈活的偏好對?。
未來研究?向:未來的研究可聚焦于優化文本交互?法,使其能夠適應更多專門任務,探索更魯棒的獎勵模型以提升偏好捕捉能?,并研究如何提升較弱模型在TPO中的表現,從而進一步拓展其應用場景和優化效果。
論?鏈接:https://arxiv.org/abs/2501.12895
Github鏈接:https://github.com/yafuly/TPO
Huggingface鏈接:https://huggingface.co/papers/2501.12895





























