













即插即用、無需訓(xùn)練:劍橋大學(xué)、騰訊AI Lab等提出免訓(xùn)練跨模態(tài)文本生成框架
1. 導(dǎo)讀
本文提出了一個(gè)全新的 MAGIC (iMAge-guided text GeneratIon with CLIP)框架。該框架可以使用圖片模態(tài)的信息指導(dǎo)預(yù)訓(xùn)練語言模型完成一系列跨模態(tài)生成任務(wù),例如 image captioning 和 visually grounded story generation。與其他方法不同的是,MAGIC 框架無需多模態(tài)訓(xùn)練數(shù)據(jù),只需利用現(xiàn)成的語言模型(例如 GPT-2)和圖文匹配模型(例如 CLIP)就能夠以 zero-shot 的方式高質(zhì)量地完成多模態(tài)生成任務(wù)。此外,不同于使用梯度更新生成模型 cache 的傳統(tǒng)方法,MAGIC 框架無需梯度更新,因而具備更高效的推理效率。

- 論文:https://arxiv.org/abs/2205.02655
- 代碼:https://github.com/yxuansu/MAGIC
2. 研究背景以及目的
借助日益強(qiáng)大的預(yù)訓(xùn)練語言模型,我們已經(jīng)可以根據(jù)文本前綴生成一段流利文本。當(dāng)前,絕大多數(shù)工作的主要研究方向集中于利用文本模態(tài)的前綴來生成后續(xù)文本的方法。然而,如何有效利用其他模態(tài)的信息(例如圖片)來指導(dǎo)預(yù)訓(xùn)練語言模型生成高質(zhì)量的文本,仍然是一個(gè)待解決的難題。目前,針對(duì)此類問題最常見的解決思路是在收集好的高質(zhì)量多模態(tài)平行數(shù)據(jù)的基礎(chǔ)上,訓(xùn)練多模態(tài)的模型來完成特定的跨模態(tài)任務(wù)。例如,我們可以在圖文匹配的標(biāo)注數(shù)據(jù)集上,通過監(jiān)督學(xué)習(xí)的方法訓(xùn)練 image captioning 模型,從而根據(jù)輸入圖片生成對(duì)應(yīng)的文本描述。
但是,該方法存在標(biāo)注數(shù)據(jù)獲取困難的弊端,并不適合所有應(yīng)用場(chǎng)景。為了解決這一難題,許多研究者提出了一系列弱監(jiān)督的方法。而這類方法也有其弊端,它們會(huì)受到不同多模態(tài)任務(wù)的特定限制。例如,在 image captioning 任務(wù)中,弱監(jiān)督的方法需要使用特定的目標(biāo)檢測(cè)器,來收集圖片內(nèi)可識(shí)別目標(biāo)的標(biāo)簽信息。然而,當(dāng)圖片中包含目標(biāo)檢測(cè)器無法識(shí)別的物體 (out-of-domain object) 時(shí),弱監(jiān)督方法的有效性就會(huì)大打折扣。
為了擺脫對(duì)目標(biāo)檢測(cè)器的依賴從而真正實(shí)現(xiàn) zero-shot 跨模態(tài)文本生成,ZeroCap[1]提出在推理階段通過梯度更新的方式修正生成語言模型內(nèi)部的隱狀態(tài),從而使生成的文本描述和圖片內(nèi)容盡可能接近。但是,這一方法也有其弊端,通過多次迭代梯度更新來調(diào)整模型的內(nèi)部隱狀態(tài),在當(dāng)前預(yù)訓(xùn)練語言模型參數(shù)量越來越大的趨勢(shì)下,其運(yùn)行效率會(huì)變得越來越低,嚴(yán)重限制了該方法在實(shí)際場(chǎng)景中的應(yīng)用。
本文提出了一個(gè)全新的 MAGIC 框架。MAGIC 通過直接插入可控的圖文匹配模型分?jǐn)?shù)的方式,使得語言模型在解碼過程中選擇更接近圖片信息的生成結(jié)果。這樣,語言模型可以在不經(jīng)過任何跨模態(tài)訓(xùn)練的情況下,高質(zhì)量地解決跨模態(tài)生成任務(wù),得到明顯優(yōu)于弱監(jiān)督模型的文本生成質(zhì)量。同時(shí),與 ZeroCap 相比,MAGIC 還擁有接近 27 倍的推理速度提升。
3. 研究方法
3.1 無監(jiān)督語言建模
為了適應(yīng)特定跨模態(tài)任務(wù)的文本領(lǐng)域,該研究預(yù)先使用了跨模態(tài)訓(xùn)練數(shù)據(jù)集中的文本數(shù)據(jù),采取無監(jiān)督的方式更新語言模型的參數(shù)(僅需在 1 塊 NVIDIA 1080Ti 上運(yùn)行不到兩個(gè)小時(shí)),從而使得語言模型更加熟悉該領(lǐng)域的文本分布。具體而言,本文使用 MLE 損失函數(shù)訓(xùn)練語言模型的參數(shù):
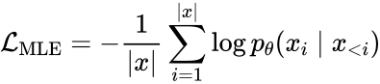
此外,SimCTG[2]的最新工作證明了通過引入對(duì)比損失來校準(zhǔn)模型的語義空間,能夠獲得質(zhì)量更高的語言模型。因此,本文也同時(shí)優(yōu)化如下的對(duì)比損失:
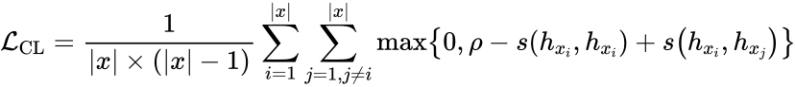
其中 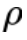 是用來校準(zhǔn)生成模型表示空間的 margin 參數(shù),
是用來校準(zhǔn)生成模型表示空間的 margin 參數(shù),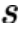 用來計(jì)算 token 表示之間的余弦相似度。最終,本文將兩個(gè)損失函數(shù)合并,以此來優(yōu)化文本模態(tài)的 GPT-2 語言模型:
用來計(jì)算 token 表示之間的余弦相似度。最終,本文將兩個(gè)損失函數(shù)合并,以此來優(yōu)化文本模態(tài)的 GPT-2 語言模型:
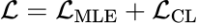
3.2 MAGIC Search
本文提出了 MAGIC Search 解碼算法。MAGIC 使用視覺信息指導(dǎo)預(yù)訓(xùn)練語言模型的生成過程。具體而言,給定文本前綴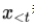 和圖片
和圖片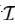 ,第 t 步的 token 選擇公式如下:
,第 t 步的 token 選擇公式如下:
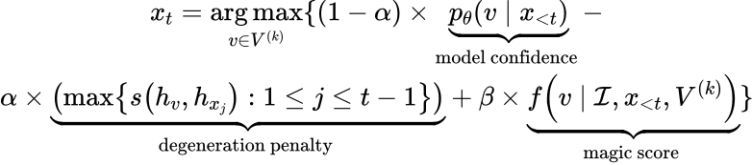
其中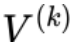 表示按照語言模型概率分布選擇的 top-k 個(gè)候選 token。同時(shí),該研究借鑒了 SimCTG 中 contrastive search 的思路,在 token 選擇指標(biāo)中引入了 model confidence 和 degeneration penalty 項(xiàng)來使得模型選擇更合適的 token。上述公式中最重要的一項(xiàng)是將視覺控制信息引入到模型解碼過程中的 magic score:
表示按照語言模型概率分布選擇的 top-k 個(gè)候選 token。同時(shí),該研究借鑒了 SimCTG 中 contrastive search 的思路,在 token 選擇指標(biāo)中引入了 model confidence 和 degeneration penalty 項(xiàng)來使得模型選擇更合適的 token。上述公式中最重要的一項(xiàng)是將視覺控制信息引入到模型解碼過程中的 magic score:
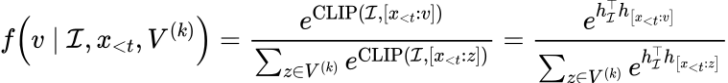
其中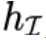 是 CLIP 的 image encoder 產(chǎn)生的圖片表示,
是 CLIP 的 image encoder 產(chǎn)生的圖片表示,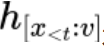 是 CLIP 的 text encoder 產(chǎn)生的文本表示。
是 CLIP 的 text encoder 產(chǎn)生的文本表示。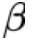 參數(shù)用來調(diào)節(jié)視覺信息的控制力度。當(dāng)其值為 0 時(shí),語言模型的生成過程不再被視覺信息所影響,從而 magic search 退化為傳統(tǒng)的 contrastive search。
參數(shù)用來調(diào)節(jié)視覺信息的控制力度。當(dāng)其值為 0 時(shí),語言模型的生成過程不再被視覺信息所影響,從而 magic search 退化為傳統(tǒng)的 contrastive search。
4. 實(shí)驗(yàn)結(jié)論
4.1 Zero-shot Image Captioning
4.1.1 實(shí)驗(yàn)設(shè)置
本文在 MS-COCO 和 Flickr30k 數(shù)據(jù)集上進(jìn)行了大量的實(shí)驗(yàn),并選用以下的無監(jiān)督 baseline 進(jìn)行對(duì)比:
1.top-k sampling:不基于圖片信息,用 top-k 解碼方法使用語言模型來生成 caption
2.nucleus sampling:不基于圖片信息,用 nucleus 解碼方法使用語言模型生成 caption
3.contrastive search:不基于圖片信息,用 contrastive search 解碼方法使用語言模型來生成 caption
4.CLIPRe:使用 CLIP 模型從 MS-COCO 或 Flickr30k 的訓(xùn)練數(shù)據(jù)中檢索文本數(shù)據(jù)
5.ZeroCap:在解碼過程中,使用 CLIP 信息來指導(dǎo)語言模型梯度更新的方法
值得注意的是 top-k sampling, nucleus sampling 和 contrastive search 解碼方法因?yàn)椴换趫D片信息,所以可看作是文本生成模型在跨模態(tài)任務(wù)上的性能下界。此外,本文還選取了一批監(jiān)督和弱監(jiān)督的方法來進(jìn)行對(duì)比。
對(duì)于評(píng)價(jià)方法,本文采用 image captioning 中經(jīng)典的評(píng)價(jià)指標(biāo):BLEU-1, BLEU-4, METEOR, ROUGE-L, CIDEr 和 SPICE,同時(shí)也測(cè)試了不同模型的相對(duì)解碼速率。4.1.2 MS-COCO 和 Flickr30k 實(shí)驗(yàn)結(jié)果
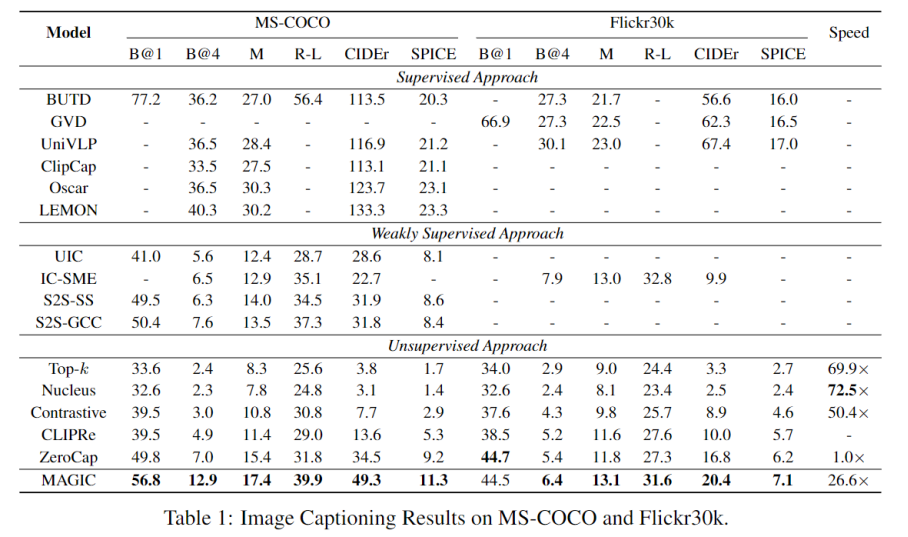
如上圖所示,本文發(fā)現(xiàn)當(dāng)忽視 captions 的信息,只使用語言模型進(jìn)行生成時(shí)效果并不好(Top-k, Nucleus, Contrastive),這說明沒有對(duì)應(yīng)的圖片信息,只依靠語言模型很難完成這個(gè)跨模態(tài)的任務(wù)。CLIPRe 方法效果雖然顯著好于 Top-k 等純文本解碼方法,但仍然弱于當(dāng)前 SOTA 無監(jiān)督方法,ZeroCap,這是由 training set 和 test set 之間的數(shù)據(jù)差異所造成。這也證明了檢索模型在該任務(wù)上效果弱于生成模型。
本文 MAGIC 的生成結(jié)果顯著優(yōu)于 ZeroCap,展示了 MAGIC 框架的有效性。并且因?yàn)?MAGIC 完全不依賴于梯度更新,其解碼速度比 ZeroCap 快接近 27 倍。
4.1.3. 跨領(lǐng)域?qū)嶒?yàn)結(jié)果
此外,本文還進(jìn)行了跨領(lǐng)域?qū)嶒?yàn)以進(jìn)一步測(cè)試 MAGIC 的泛化能力。具體而言,本文使用在源領(lǐng)域(例如 MS-COCO)上得到的無監(jiān)督語言模型,在目標(biāo)領(lǐng)域(例如 Flickr30k)的測(cè)試集上進(jìn)行實(shí)驗(yàn)。本文在該實(shí)驗(yàn)中對(duì)比無監(jiān)督解碼方法和 CLIPRe。其中 CLIPRe 的檢索數(shù)據(jù)集僅來自于源領(lǐng)域的訓(xùn)練集,實(shí)驗(yàn)結(jié)果如下:
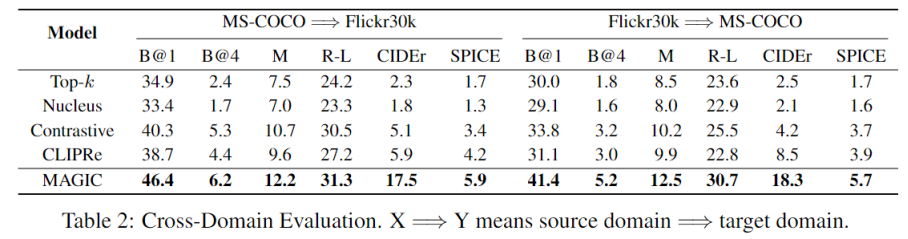
從表格中結(jié)果可以發(fā)現(xiàn),MAGIC 遠(yuǎn)好于純文本解碼方法和 CLIPRe 強(qiáng) baseline。
4.1.4. Case Study
該研究通過一些例子來定性的對(duì)比 baseline 和本文方法:

這幾個(gè)例子顯示出 MAGIC 不僅能夠生成非常流利的文本,同時(shí)其生成文本中的信息和圖片模態(tài)的關(guān)聯(lián)性也更強(qiáng)。例如圖 (a) 中,MAGIC 可以準(zhǔn)確的生成 “building”,但是 ZeroCap 卻生成了“school bus” 這個(gè)無關(guān)的結(jié)果。此外,圖 (d) 中,雖然 ZeroCap 生成了 “boatboard” 這一相關(guān)詞匯,但其語句流利度低,并且存在語法錯(cuò)誤。相比之下,MAGIC 生成的文本在通順流暢的同時(shí),也與圖片顯示的內(nèi)容一致。
4.2 基于視覺的故事生成
除了 image captioning 任務(wù)之外,該研究還將 MAGIC 框架拓展到了其他基于視覺的文本生成任務(wù),例如基于視覺的故事生成(visually grounded story generation)。在該任務(wù)中,給一個(gè)圖片和故事標(biāo)題,模型的任務(wù)是生成一個(gè)流利有趣并且與圖片內(nèi)容及故事標(biāo)題一致的故事。
4.2.1 實(shí)驗(yàn)設(shè)置
本文在 ROCStories 數(shù)據(jù)集上進(jìn)行了實(shí)驗(yàn),并選取以下的文本解碼方式作為該研究的 baseline:(1) Greedy search;(2)Beam search;(3)Top-K sampling;(4)Nucleus sampling;(5)Typical sampling;和(6)Contrastive search。
為了達(dá)到給 ROCStories 數(shù)據(jù)集中每一個(gè)測(cè)試樣例提供一個(gè)圖片信息的目的,本文使用 CLIP 模型從公開的 ConceptCaption 數(shù)據(jù)集中檢索和故事標(biāo)題最相關(guān)的圖片。
為了有效評(píng)價(jià)模型的效果,本文采用了以下幾種評(píng)價(jià)指標(biāo):
1. 自動(dòng)評(píng)價(jià)指標(biāo):本文采用之前文本生成研究中的一系列評(píng)價(jià)指標(biāo)a.n-gram 重復(fù)率 (rep-n)b. 生成文本多樣性 (div.)c. 語義一致性(coh.):生成的故事和標(biāo)題是否語義一致d. 圖文匹配相關(guān)性 (CLIPScore)e.MAUVE 分?jǐn)?shù)
2. 人工評(píng)價(jià)指標(biāo):為了更精準(zhǔn)的反映生成故事的質(zhì)量,五個(gè)專業(yè)的標(biāo)注員從以下幾個(gè)角度對(duì)生成故事的質(zhì)量進(jìn)行打分(1-5 分,1 分最差,5 分最好)a. 相關(guān)性:生成的故事是否和標(biāo)題有關(guān)b. 流利度:生成的故事是否流利易懂c. 信息量:生成的故事是否多樣且有趣d. 故事圖片相關(guān)性:生成的故事是否和通過標(biāo)題檢索得到的圖片語義一致
4.2.2 實(shí)驗(yàn)結(jié)果
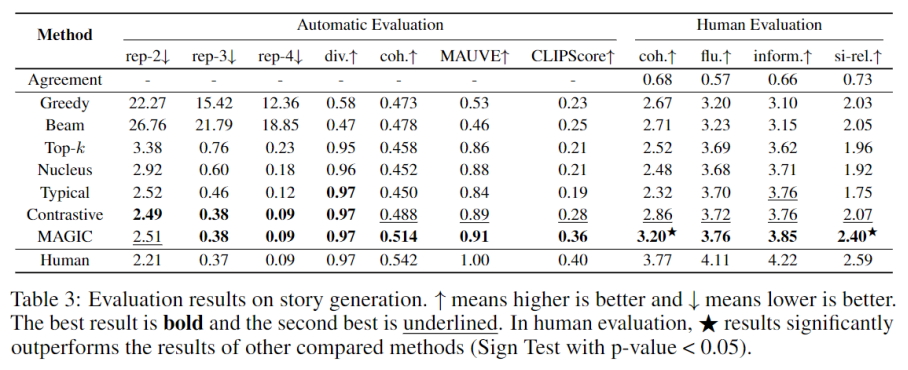
如上圖所示,MAGIC 在大多數(shù)的指標(biāo)上都達(dá)到了最佳的效果,明顯優(yōu)于其他方法。其中 rep-n, diversity 和 MAUVE 的最佳結(jié)果說明 MAGIC 生成的故事和人類文本更加接近。并且 MAGIC 在 coherence 和圖文匹配一致性分?jǐn)?shù)上顯著優(yōu)于其他的方法,說明 MAGIC 在綜合利用了圖片和文本標(biāo)題的信息之后可以生成和標(biāo)題信息更加相關(guān)的故事內(nèi)容。人工評(píng)價(jià)的效果也顯示 MAGIC 生成的故事在各個(gè)角度上均達(dá)到了最好的效果。
4.2.3 Case Study

如上圖所示,MAGIC 可以有效的生成和圖片有關(guān)的信息。在第一個(gè)例子中,MAGIC 生成的故事包含了詳細(xì)的冰淇凌的種類和味道,除了 orange 的結(jié)果稍有差異,其他的文本都完美符合圖片中的描述。在第二個(gè)例子中,contrastive search 生成的結(jié)果和故事標(biāo)題間相關(guān)度較差。與之相反,MAGIC 生成的內(nèi)容和圖片中的信息及主題高度相關(guān),例如:(1)和朋友們?cè)谏碁唬?)打沙灘排球;(3)比賽持續(xù)了兩個(gè)小時(shí);(4)朋友贏下了比賽。


























