













一文讀懂DeepSeek-V3 技術報告
2023年7月17日,DeepSeek正式成立,由幻方量化提供資金支持。梁文鋒憑借其在金融和AI領域的深厚背景,帶領團隊開始探索生成式AI技術。同年11月2日,DeepSeek推出首款開源模型DeepSeek Coder,支持多種編程語言的代碼生成、調試和數據分析任務,為AI領域的應用奠定了基礎,直到 2024 年 12 月,DeepSeek-V3的發布引發了行業震動和社會廣泛關注,在他們的最新技術報告《DeepSeek-V3技術報告》中,團隊詳細介紹了其最新成果——DeepSeek-V3模型。這個模型不僅在規模上達到了新的高度,而且在性能、訓練效率以及多語言支持等方面實現了顯著提升,今天我們將詳細解讀DeepSeek-V3技術報告,分析他們的技術特征。
DeepSeek-AI研究團隊由一群來自不同領域的頂尖專家組成,這些專家在數學、編程、邏輯推理、自然語言處理和深度學習等多個領域有著豐富的經驗。他們共同致力于推動先進大規模語言模型的發展。團隊的多樣性和跨學科合作精神在DeepSeek-V3的開發中起到了關鍵作用。主要貢獻者包括Aixin Liu、Bei Feng、Bing Xue、Chong Ruan、Damai Dai、Dejian Yang、Dongjie Ji、Fangyun Lin、Guowei Li、Han Bao、Hui Li、Jingchang Chen、Kai Dong等。這些研究人員在模型架構優化、訓練效率提升以及多項基準測試上,做出了卓越的貢獻。
DeepSeek-V3作為一款先進的大規模語言模型,其總體架構設計和目標主要集中在以下幾個方面:
多頭潛在注意力(MLA)與DeepSeekMoE架構:DeepSeek-V3采用了多頭潛在注意力(MLA)和DeepSeekMoE架構,這兩種架構在之前的版本中已經得到了驗證,能夠在保證模型性能的同時實現高效訓練和推理。MLA通過低秩聯合壓縮注意力鍵和值,顯著降低了推理過程中的KV緩存,同時保持了與標準多頭注意力(MHA)相當的性能。
無輔助損失的負載平衡策略:為了實現負載平衡并最大限度減少輔助損失帶來的性能下降,DeepSeek-V3創新性地引入了無輔助損失的負載平衡策略。這一策略通過動態調整每個專家的偏差項,確保在訓練過程中保持專家負載平衡,進而提升模型性能。
多token預測(MTP)目標:DeepSeek-V3在訓練過程中采用多token預測(MTP)目標,不僅增加了訓練信號的密度,提高了數據效率,還使模型能夠更好地預測未來token。通過這種方式,模型在實際應用中能夠實現更高效的解碼速度。
計算基礎設施和優化策略:DeepSeek-V3的訓練依托于一個配備2048個NVIDIA H800 GPU的集群。為了提升訓練效率,團隊設計了DualPipe算法,減少了流水線氣泡,并通過計算與通信重疊,解決了跨節點專家并行帶來的通信開銷問題。此外,團隊還開發了高效的跨節點全對全通信內核,進一步優化了內存占用。
FP8訓練框架:DeepSeek-V3引入了利用FP8數據格式的混合精度訓練框架,通過細粒度量化策略和高精度累積過程,有效提升了低精度訓練的準確性,顯著減少了內存消耗和通信開銷。
 圖1:DeepSeek-V3及其對應產品的基準性能。
圖1:DeepSeek-V3及其對應產品的基準性能。
DeepSeek-V3不僅在模型架構、訓練效率和推理性能方面實現了突破,還在多語言支持和長上下文處理等方面展現了卓越的能力。通過這種多方位的創新和優化,DeepSeek-V3為開源和閉源模型樹立了新的標桿,并為未來人工智能研究的進一步發展奠定了堅實基礎。
DeepSeek-V3的架構與特點
DeepSeek-V3的成功離不開其創新的架構設計與優化策略。在這一部分,我們將深入探討其基本架構及其核心特點。
1.多頭潛在注意力(MLA)
DeepSeek-V3采用了多頭潛在注意力(MLA)架構,這是一種優化傳統多頭注意力機制的方法。與標準多頭注意力(MHA)相比,MLA通過低秩聯合壓縮注意力鍵和值,顯著降低了推理過程中的KV緩存需求,同時保持了與MHA相當的性能。MLA通過對注意力輸入進行低秩壓縮,再恢復到高維度,這種方式不僅減少了計算量,也提升了模型的推理效率。
在具體實現中,MLA通過將每個token的注意力輸入進行壓縮,再通過特定的線性變換和旋轉位置編碼(RoPE)進行處理。這種方法的優勢在于,它可以在不顯著影響模型性能的情況下,大幅度減少KV緩存,從而在推理階段實現更高的效率。
DeepSeekMoE架構

圖2:DeepSeek-V3的基本架構示意圖。在DeepSeek-V2之后,他們采用MLA和DeepSeekMoE進行高效推理和經濟訓練。
DeepSeekMoE架構是DeepSeek-V3的核心,它在前饋網絡(FFN)中使用了專家混合模型(MoE)。與傳統MoE架構(如GShard)不同,DeepSeekMoE使用了更細粒度的專家,并將部分專家設為共享專家。這種方法不僅提升了計算效率,還減少了專家負載不平衡的問題。
在具體實現中,DeepSeek-V3引入了動態路由機制,使每個token在不同節點間進行路由,從而實現跨節點的專家并行。通過這種方式,DeepSeek-V3能夠在保持高性能的同時,實現高效的計算和訓練。
無輔助損失的負載平衡策略
為了進一步提升模型的性能和訓練效率,DeepSeek-V3采用了一種無輔助損失的負載平衡策略。傳統的MoE模型在實現負載平衡時通常依賴于輔助損失,但這種方法往往會影響模型的性能。DeepSeek-V3通過引入偏差項,使得在路由過程中可以動態調整每個專家的負載,從而實現負載平衡而不依賴于輔助損失。
具體而言,每個專家都有一個偏差項,這個偏差項會根據專家的負載情況進行動態調整。如果某個專家負載過重,則減小其偏差項,反之則增加。通過這種方式,DeepSeek-V3在訓練過程中能夠保持專家負載的平衡,從而提升模型的整體性能。
多token預測(MTP)目標
DeepSeek-V3在訓練過程中還采用了多token預測(MTP)目標。傳統的語言模型通常只預測下一個token,而DeepSeek-V3則在每個位置上預測多個未來token。這種方法不僅增加了訓練信號的密度,提高了數據效率,還使模型能夠更好地規劃其表示,以便更準確地預測未來的token。
實現示例。他們為每個深度的每個令牌的預測保留了完整的因果鏈。") 圖3:他們的多令牌預測(MTP)實現示例。他們為每個深度的每個令牌的預測保留了完整的因果鏈。
圖3:他們的多令牌預測(MTP)實現示例。他們為每個深度的每個令牌的預測保留了完整的因果鏈。
在具體實現中,MTP通過多層次的模塊來預測多個附加的token,每個模塊共享嵌入層和輸出頭,保持預測的因果鏈。這種方法在推理過程中可以提高生成速度,并顯著提升模型的整體性能。
DeepSeek-V3的架構設計在多方面實現了創新和優化。通過MLA、DeepSeekMoE架構、無輔助損失的負載平衡策略以及多token預測目標,DeepSeek-V3不僅在性能上取得了顯著提升,還在訓練效率和推理速度上展現了卓越的能力。這些特點使得DeepSeek-V3在眾多基準測試中表現優異,成為當前最強的開源語言模型之一。
2.計算基礎設施
DeepSeek-V3的成功不僅依賴于其先進的架構設計,還得益于強大的計算基礎設施支持。通過優化計算集群配置和訓練框架,DeepSeek-AI團隊大幅提升了模型的訓練效率和性能。

圖4:一對單獨的正向和反向塊的重疊策略(transformer塊的邊界未對齊)。橙色表示前進,綠色表示前進“輸入向后”,藍色表示“權重向后”,紫色表示PP通信,紅色表示障礙。所有對所有和PP通信都可以完全隱藏。
在計算集群配置方面,DeepSeek-V3的訓練依托于一個配備2048個NVIDIA H800 GPU的集群。每個H800節點包含8個通過NVLink和NVSwitch連接的GPU,跨節點的通信則使用InfiniBand(IB)互連。這種配置不僅確保了高帶寬的通信能力,還通過硬件設計的優化大幅減少了訓練過程中通信延遲帶來的瓶頸。
在訓練框架與優化策略方面,DeepSeek-V3采用了HAI-LLM框架,這是一種高效且輕量的訓練框架。該框架支持16路流水線并行、跨8個節點的64路專家并行以及ZeRO-1數據并行,確保了在大規模訓練任務中的高效運行。通過DualPipe算法的設計,團隊實現了計算與通信階段的重疊,有效解決了跨節點專家并行帶來的通信開銷問題。

圖5:8個PP等級和20個微批次的雙管調度示例,分為兩個方向。反向的微批次與正向的微批次是對稱的,因此為了簡化說明,他們省略了它們的批次ID。由共享黑色邊框包圍的兩個單元具有相互重疊的計算和通信。
DualPipe算法是DeepSeek-V3訓練框架中的一大亮點。這一算法通過減少流水線氣泡并實現前向和后向計算-通信階段的重疊,不僅加速了模型訓練,還顯著提高了訓練效率。具體來說,DualPipe將每個塊劃分為四個組件:注意力、全對全分派、MLP和全對全組合。通過手動調整GPU SM用于通信與計算的比例,確保通信與計算完全重疊,從而實現了近乎零的通信開銷。
高效的跨節點全對全通信內核進一步提升了訓練效率。DeepSeek-AI團隊開發了高效的跨節點全對全通信內核,充分利用IB和NVLink帶寬,并節省用于通信的流式多處理器(SM)。通過限制每個token最多發送到4個節點,減少了IB流量,實現了IB與NVLink通信的完全重疊。
內存占用優化也是DeepSeek-V3訓練框架中的重要一環。通過重新計算RMSNorm和MLA上投影,消除持續存儲輸出激活的需求,大幅減少內存占用。此外,通過將模型參數的指數移動平均(EMA)存儲在CPU內存中并異步更新,進一步減少了內存開銷。
在FP8訓練框架方面,DeepSeek-V3引入了利用FP8數據格式的混合精度訓練框架。低精度訓練雖然前景廣闊,但通常受到激活、權重和梯度中的異常值的限制。DeepSeek-AI團隊通過引入細粒度量化策略和高精度累積過程,有效提升了低精度訓練的準確性,顯著減少了內存消耗和通信開銷。
 圖6:FP8數據格式的整體混合精度框架。為澄清起見,僅示出了線性運算符。
圖6:FP8數據格式的整體混合精度框架。為澄清起見,僅示出了線性運算符。
混合精度訓練框架通過在FP8精度下執行大多數核心計算內核,并在需要較高精度的操作中保留原始精度,平衡了訓練效率和數值穩定性。在這個框架中,大多數通用矩陣乘法(GEMM)操作以FP8精度實現,顯著提高了計算速度。此外,通過采用細粒度量化策略,將激活和權重按塊狀分組和縮放,有效解決了激活異常值帶來的量化準確性問題。
在精度改進策略方面,DeepSeek-V3通過在Tensor Cores和CUDA Cores之間的高精度累積過程,顯著提高了低精度訓練的準確性。通過將部分結果復制到CUDA Cores上的FP32寄存器,并在這些寄存器中執行全精度FP32累積,有效提升了精度而不會引入顯著的開銷。
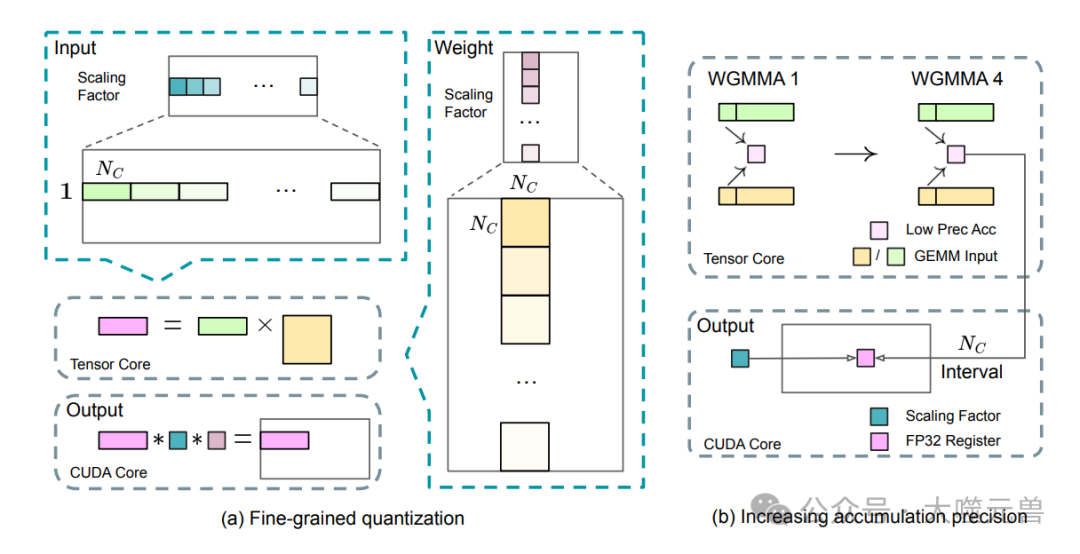
圖7:(a)他們提出了一種細粒度量化方法,以減輕特征異常值引起的量化誤差;為了簡化說明,僅示出了Fprop。(b) 結合我們的量化策略,他們通過以???? ==128個元素MMA的間隔升級到CUDA核心來提高FP8 GEMM的精度,以實現高精度累積。
低精度存儲與通信則進一步減少了內存消耗和通信開銷。通過在反向傳遞中緩存FP8格式的激活,并將優化器狀態壓縮為低精度格式,DeepSeek-V3在保持訓練性能的同時,顯著減少了內存占用和通信帶寬需求。
綜上所述,DeepSeek-V3在計算基礎設施和訓練框架方面的創新和優化,使其在模型性能、訓練效率和推理速度上都取得了顯著的突破。這些技術上的進步不僅為DeepSeek-V3的成功提供了堅實基礎,也為未來大規模語言模型的發展指明了方向。
預訓練
在構建DeepSeek-V3的過程中,預訓練是一個至關重要的環節。通過精心設計的數據構建方法、優化的分詞器策略以及合理的超參數設置,DeepSeek-AI團隊確保了模型在多語言和多任務環境中的卓越表現。
在數據構建方面,DeepSeek-V3采用了多種優化策略。相較于前一版本DeepSeek-V2,團隊在預訓練語料庫中增加了數學和編程樣本的比例,并擴展了多語言覆蓋范圍,不再局限于英語和中文。此外,團隊還通過改進數據處理流程,最大限度地減少了數據冗余,確保語料庫的多樣性。受到Ding等人(2024年)的啟發,他們實施了文檔打包方法,以確保數據完整性,同時避免了訓練期間跨樣本注意力掩碼的應用。最終,DeepSeek-V3的訓練語料庫包含了14.8萬億高質量和多樣的tokens,為模型提供了豐富的訓練數據。
在分詞器及預處理策略方面,DeepSeek-V3采用了字節級BPE分詞器,具有128K的擴展詞匯表。為了優化多語言壓縮效率,團隊對分詞器的預處理和訓練數據進行了修改。新的分詞器引入了結合標點符號和換行符的tokens,盡管這可能在無終止換行的多行提示處理中引入token邊界偏差,但通過在訓練過程中隨機拆分這些組合token,團隊有效地減輕了這種偏差,提高了模型在多種特殊情況下的表現。
在超參數設置方面,團隊精心挑選了模型和訓練的超參數,以確保模型的最佳性能。模型超參數包括61層Transformer層,每層有7168個隱藏維度,以及128個注意力頭和128個每頭維度。所有可學習參數隨機初始化,標準差為0.006。對于多頭潛在注意力(MLA),設置了512的KV壓縮維度和1536的查詢壓縮維度,所有FFN層除前三層外均替換為專家混合模型(MoE)層,每個MoE層包括1個共享專家和256個路由專家。

圖8:“草垛中的針”(NIAH)測試的評估結果。DeepSeek-V3在高達128K的所有上下文窗口長度上都表現良好。
訓練超參數方面,團隊使用AdamW優化器,設置了β1=0.9,β2=0.95和weight_decay=0.1。最大序列長度設置為4K,并在14.8萬億tokens上進行預訓練。學習率調度采用了從0逐漸增加到2.2×10-4 的線性增長,然后在10萬億訓練tokens內保持恒定,再逐漸衰減至2.2×10-5,并在最后5000億tokens內保持在7.3×10^-6。梯度裁剪范數設為1.0,批量大小從3072逐漸增加到15360,使用流水線并行將模型的不同層部署在不同的GPU上,實現高效訓練。
在長上下文擴展方面,DeepSeek-V3采用了與DeepSeek-V2類似的方法,使其具備處理長上下文的能力。預訓練階段后,通過YaRN進行上下文擴展,進行兩階段的訓練,每階段包含1000步,將上下文窗口從4K逐漸擴展到128K。通過這種兩階段擴展訓練,DeepSeek-V3能夠處理最長128K的輸入,同時保持強大的性能。
通過上述多種優化策略和超參數設置,DeepSeek-V3在模型性能和訓練效率方面實現了顯著提升,為其在多語言和多任務環境中的卓越表現奠定了堅實基礎。
評估與實驗結果
在評估與實驗結果部分,DeepSeek-AI團隊對DeepSeek-V3進行了全面且詳盡的測試,通過多種基準測試和不同設置,展示了模型在各個方面的卓越性能。
評估基準與設置
在選擇評估基準時,團隊考慮了多種因素,包括模型的多語言能力、代碼生成能力、數學推理能力以及在開放式生成任務中的表現。他們選取了廣泛認可的基準測試,如MMLU、DROP、GPQA和SimpleQA等,以全面評估模型的性能。
具體評估配置方面,團隊使用了內部開發的評估框架,確保所有模型在相同的條件下進行測試。例如,在MMLU-Redux的零樣本設置中,使用Zero-Eval提示格式;在代碼和數學基準測試中,HumanEval-Mul數據集包括了8種主流編程語言,并采用CoT和非CoT方法評估模型性能。在數學評估中,AIME和CNMO 2024使用0.7的溫度進行評估,結果平均于16次運行,而MATH-500則采用貪婪解碼。所有模型在每個基準測試中最多輸出8192個token,以保證公平比較。
評估結果
在標準評估結果中,DeepSeek-V3展示了其作為最強開源模型的實力,并在與閉源模型的競爭中表現出色。
在英文基準測試中,DeepSeek-V3在MMLU、MMLU-Pro、MMLU-Redux、GPQA-Diamond和DROP等測試中表現優異,顯示了其在多領域知識和任務中的競爭力。例如,在MMLU-Pro這一更具挑戰性的教育知識基準測試中,DeepSeek-V3緊隨Claude-Sonnet 3.5,其結果顯著優于其他模型。此外,DeepSeek-V3在處理長上下文任務中表現出色,如在DROP的3-shot設置中取得了91.6的F1分數,并在FRAMES這一需要在10萬token上下文中進行問答的基準測試中,緊隨GPT-4o,顯著優于其他模型。
在代碼與數學基準測試中,DeepSeek-V3展示了卓越的編碼生成和數學推理能力。在工程任務中,盡管略遜于Claude-Sonnet-3.5-1022,但顯著優于其他開源模型。在算法任務中,DeepSeek-V3在HumanEval-Mul和LiveCodeBench等測試中表現優異,超越所有基線模型。這種成功得益于其先進的知識蒸餾技術,在數學基準測試如AIME、MATH-500和CNMO 2024中,DeepSeek-V3同樣表現出色,顯著優于其他模型。
在中文基準測試中,DeepSeek-V3在Chinese SimpleQA、C-Eval和CLUEWSC等測試中也表現出色。例如,在Chinese SimpleQA這一中文事實知識基準測試中,DeepSeek-V3比Qwen2.5-72B高出16.4分,盡管Qwen2.5-72B在更大規模的語料庫上進行了訓練。這一結果表明DeepSeek-V3在多語言環境中的優越性能。
在開放式評估中,DeepSeek-V3在Arena-Hard和AlpacaEval 2.0基準測試中也展示了卓越的性能。在Arena-Hard基準測試中,DeepSeek-V3對基線GPT-4-0314的勝率超過86%,表現與頂級模型Claude-Sonnet-3.5-1022相當,突顯了其在處理復雜提示(包括編碼和調試任務)方面的強大能力。此外,DeepSeek-V3在AlpacaEval 2.0上的表現也非常出色,超越了閉源和開源模型,展示了其在寫作任務和處理簡單問答場景方面的卓越能力。
 圖片
圖片
圖9 :樁試驗裝置中三個域的無輔助損失和基于輔助損失的模型的專家載荷。無輔助損失模型比基于輔助損失的模型顯示出更大的專家專業化模式。相對專家負荷表示實際專家負荷與理論平衡專家負荷之間的比率。
作為生成性獎勵模型,DeepSeek-V3在RewardBench中的表現同樣突出。與GPT-4o和Claude-3.5-Sonnet等先進模型相比,DeepSeek-V3的判斷能力不相上下,并且可以通過投票技術進一步提升。這一特性使得DeepSeek-V3能夠為開放式問題提供自我反饋,提高對齊過程的有效性和魯棒性。
后訓練
在DeepSeek-V3的開發過程中,后訓練階段起到了至關重要的作用,通過監督微調和強化學習,進一步提升了模型的性能和實用性。
監督微調
數據集構建與策略方面,DeepSeek-AI團隊精心整理了一個包含150萬實例的指令調優數據集,涵蓋多個領域。每個領域的數據創建方法各異,以滿足特定的需求。對于推理相關的數據集,如數學、代碼競賽問題和邏輯難題,團隊利用內部的DeepSeek-R1模型生成數據。盡管R1生成的數據具有較高的準確性,但也存在過度思考、格式差和長度過長的問題。為了解決這些問題,團隊開發了一個針對特定領域的專家模型,如代碼、數學或一般推理,使用監督微調(SFT)和強化學習(RL)訓練流水線。這個專家模型作為數據生成器,為最終模型提供了高質量的訓練數據。
在微調設置方面,團隊對DeepSeek-V3-Base進行了兩輪微調,使用了從5×10-6 逐漸減少到1×10-6的余弦衰減學習率調度。訓練期間,每個單獨序列從多個樣本打包而成,但通過樣本掩碼策略確保這些例子相互隔離和不可見。這樣不僅提高了訓練效率,還保證了數據集的多樣性和有效性。
強化學習
在獎勵模型方面,團隊采用了基于規則的獎勵模型和基于模型的獎勵模型。對于可以使用特定規則驗證的問題,如某些數學問題,團隊采用基于規則的獎勵系統來確定反饋。這種方法具有高可靠性,不易被操縱。對于具有自由形式真實答案的問題,團隊則依賴獎勵模型確定響應是否符合預期答案。通過構建包含獎勵過程的偏好數據,提高了獎勵模型的可靠性,減少了特定任務中獎勵劫持的風險。
在群組相對策略優化(GRPO)方面,團隊放棄了通常與策略模型同大小的評論模型,而是從群組評分中估計基線。具體而言,對于每個問題,GRPO從舊策略模型中抽樣一組輸出,然后優化策略模型,最大化目標函數。通過這種方法,團隊在RL過程中引入了來自編碼、數學、寫作、角色扮演和問答等不同領域的提示,不僅使模型更符合人類偏好,還顯著提升了在基準測試中的表現。
總結而言,通過監督微調和強化學習的有效結合,DeepSeek-V3在后訓練階段取得了顯著的性能提升。監督微調階段高質量數據集的構建與策略,確保了模型在多個領域的準確性和適用性。而在強化學習階段,通過先進的獎勵模型和群組相對策略優化,進一步提升了模型的對齊性和魯棒性。這些努力使得DeepSeek-V3不僅在多領域表現優異,還具備了強大的實際應用潛力。
討論與未來方向
知識蒸餾的貢獻
在DeepSeek-V3的開發過程中,知識蒸餾策略起到了關鍵作用。通過從DeepSeek-R1模型中蒸餾出高質量的推理能力數據,團隊顯著提升了DeepSeek-V3在各個基準測試中的表現。表9顯示了蒸餾數據在LiveCodeBench和MATH-500基準測試中的有效性,不僅提高了模型的性能,還增加了平均響應長度。雖然蒸餾策略在提升性能方面表現出色,但也帶來了計算效率的挑戰。為了解決這個問題,團隊仔細選擇了蒸餾過程中的最佳設置,以在模型準確性和效率之間取得平衡。
這種蒸餾策略的成功表明,從推理模型中蒸餾知識是后訓練優化的一個有前途的方向。盡管目前的工作主要集中在數學和編碼領域,蒸餾技術在其他認知任務中也顯示出潛力,特別是那些需要復雜推理的任務。未來,團隊計劃進一步探索這一方法在不同任務領域的應用,以期在更廣泛的領域提升模型性能。
自我獎勵
在強化學習過程中,獎勵機制對優化過程至關重要。在可以通過外部工具進行驗證的領域(如某些編碼或數學場景),強化學習表現出極高的效率。然而,在更廣泛的場景中,通過硬編碼構建反饋機制往往不切實際。為解決這一問題,DeepSeek-V3采用了憲法AI方法,利用DeepSeek-V3自身的投票評估結果作為反饋源。這種方法顯著提升了DeepSeek-V3在主觀評估中的性能。
通過引入額外的憲法輸入,DeepSeek-V3能夠朝著預期方向進行優化。團隊認為,這種結合補充信息與LLMs作為反饋源的模式非常重要。LLM作為一個多功能處理器,能夠將來自不同場景的非結構化信息轉化為獎勵,最終促進LLMs的自我改進。除了自我獎勵外,團隊還致力于發現其他通用且可擴展的獎勵方法,以在一般場景中持續提升模型能力。
多token預測技術
DeepSeek-V3在訓練過程中采用了多token預測(MTP)技術,這一創新顯著提升了模型的生成速度和性能。傳統的語言模型通常只預測下一個token,而DeepSeek-V3則在每個位置上預測多個未來token。通過這種方法,模型不僅增加了訓練信號的密度,提高了數據效率,還能夠更好地規劃其表示,以便更準確地預測未來的token。
結合推測性解碼框架,MTP技術大幅加快了模型的解碼速度。評估顯示,DeepSeek-V3在不同生成主題中的第二個token預測接受率在85%到90%之間,展示了這一技術的一致可靠性。高接受率使得DeepSeek-V3能夠實現1.8倍的TPS(每秒token數),顯著提升了解碼速度。這一創新不僅提高了模型的實際應用效率,也為未來語言模型的發展提供了寶貴的經驗。
模型性能總結
DeepSeek-V3作為一款先進的專家混合(MoE)語言模型,在性能方面達到了新的高度。通過采用多頭潛在注意力(MLA)和DeepSeekMoE架構,結合無輔助損失的負載平衡策略和多token預測(MTP)目標,DeepSeek-V3在推理和訓練效率上實現了顯著提升。在多種基準測試中,DeepSeek-V3表現出色,超越了許多開源和閉源模型,尤其在代碼生成、數學推理和長上下文處理方面展現了卓越的能力。例如,在MMLU、DROP、GPQA-Diamond和HumanEval-Mul等測試中,DeepSeek-V3的成績令人矚目,其表現不僅在開源模型中名列前茅,還與頂級閉源模型不相上下。
現有局限性
盡管DeepSeek-V3在多個方面表現出色,但其仍然存在一些局限性。首先,為了確保高效的推理性能,推薦的部署單元相對較大,這對于規模較小的團隊可能會造成一定的負擔。其次,盡管經過多項優化,DeepSeek-V3的端到端生成速度已達到DeepSeek-V2的兩倍以上,但在推理速度上仍有進一步提升的空間。此外,當前的模型在處理某些特定任務時仍可能存在瓶頸,例如在復雜推理或極端長上下文處理方面。
未來的研究方向
面向未來,DeepSeek-AI團隊計劃在多個方向上持續投入研究,以進一步提升模型性能和應用廣泛性。首先,團隊將繼續研究和改進模型架構,旨在進一步提高訓練和推理效率,并努力支持無限上下文長度。此外,團隊將探索突破Transformer架構限制的方法,拓展其建模能力邊界。
在數據方面,團隊將不斷迭代訓練數據的數量和質量,并探索引入額外的訓練信號源,以推動數據在更廣泛維度上的擴展。與此同時,團隊還將持續探索和迭代模型的深度思考能力,旨在通過擴展推理長度和深度,提升模型的智能和解決問題的能力。
最后,團隊計劃探索更全面和多維度的模型評估方法,以避免研究過程中對固定基準測試的優化傾向,確保對模型能力的基礎性評估更加準確和全面。這些研究方向不僅為DeepSeek-V3的持續優化提供了路徑,也為整個領域的未來發展指明了方向。
總的來說,DeepSeek-V3在多個方面實現了突破,展示了強大的潛力和應用前景。通過持續的研究和優化,相信這一模型將為未來人工智能的發展作出更大的貢獻。(END)
參考資料:https://arxiv.org/abs/2412.19437




























