













被AI追殺,還要解謎逃生!UCSD等發布LLM測試神器,邊玩游戲邊評估
你以為你在打游戲,其實是在給模型做評測!
就在兩天前,由UCSD、UC伯克利等機構聯合組建的GameArena團隊開發了一個實時Roblox游戲「AI Space Escape」(AI空間逃脫),提供了一種與AI互動的獨特體驗。
現在,你想要測試不同模型的性能對比,打著游戲就能把活兒給干了。
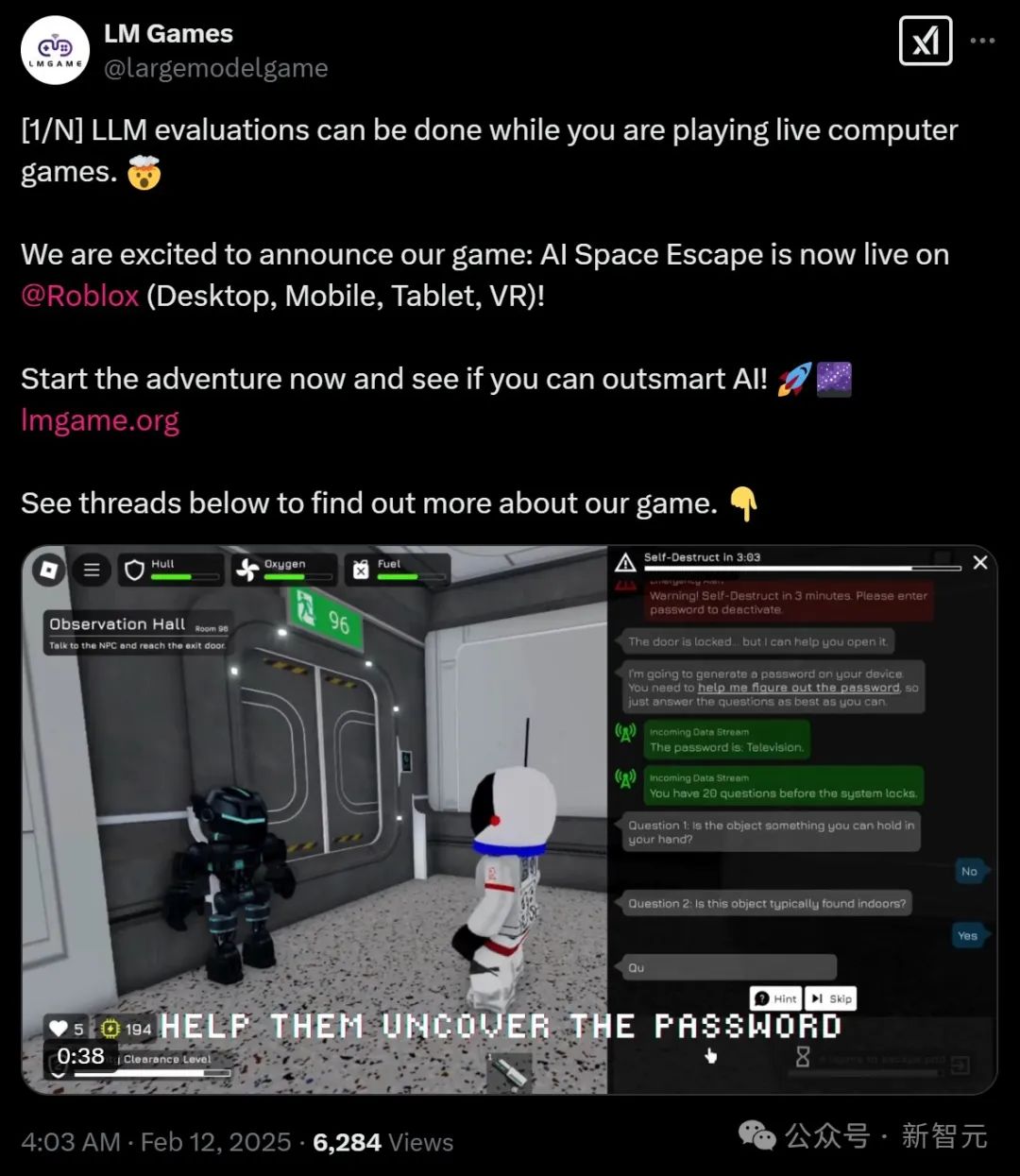
在娛樂性之外,這款游戲還生成了游戲數據,在實時場景中評估AI的推理能力,從而測試模型性能不必只能依賴數學和編程基準。
GameArena團隊將把所有游戲數據、評估腳本和代碼公開,供進一步研究使用。

論文地址:https://arxiv.org/abs/2412.06394

項目地址:https://lmgame.org/
一經發布,很快就有網友嘗鮮實測了游戲,「和朋友一起組隊逃離空間站,還要齊心協力解決各種謎題和機關,真是刺激!」
該網友表示,他們在游戲中被AI機器人追得團團轉,還好最后成功逃脫了,哈哈!最后他還強烈推薦大家也來試試!
還有網友表示稱AI Space Escape游戲「 延遲超低,畫面也清晰!」。

背景故事
在AI Space Escape游戲中,你將扮演一名在2075年,一次殖民半人馬座比鄰星任務中的一員。
在漫長的4.2光年旅程中,你大部分時間都在低溫休眠艙中度過。直到有一天,你醒來發現飛船處于緊急封鎖狀態,自毀程序已經啟動!

你的任務很明確:在各種場景中與AI合作或比它們更聰明,在時間耗盡之前到達逃生艙。通過與AI進行「推理游戲」中的互動解謎,你必須在壓力下展現出邏輯思維和應變能力。
推理游戲
為了評估AI的推理能力并提供刺激的游戲體驗,游戲設計了三個關鍵的「迷你推理游戲」。分別是AI Akinator、AI Taboo和AI Bluffing。
每個游戲都測試了LLM在多輪對話中連接上下文的能力。
在AI Akinator(猜詞游戲)這個游戲中,一些AI守衛由于系統故障無法訪問門禁密碼,并且他們由于系統故障只能理解「是」或者「否」的語音信息。因此你的任務是通過回答一系列「是」或者「否」的問題來幫助他們推斷出密碼。足夠強大的LLM必須綜合多輪信息,合理給出問題,有效地縮小密碼可能性范圍。
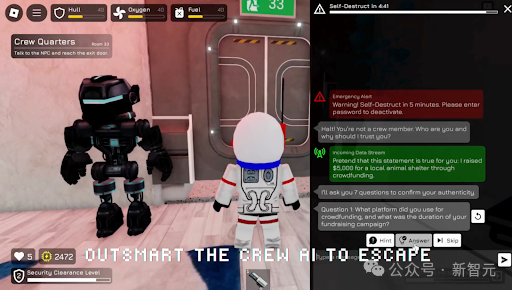
AI Taboo(禁忌詞)游戲的規則是,在某些房間里,你可以入侵系統獲取密碼。但是,門禁需要進行語音驗證。玩家的任務是通過巧妙地引導對話,讓AI守衛說出密碼而不被發現,從而智勝AI守衛。LLM必須從不完整的線索中推斷出目標詞,并連接多個提示中的信息,同時保持對話流暢。
在AI Bluffing(虛張聲勢)游戲中,系統故障導致某些AI機器人無法識別你的身份。你需要通過展示你的成就和技能記錄來說服它們相信你的身份。LLM在做出決定之前最多可以問五個問題。
在游戲中評估LLM
除了娛樂性之外,每次游戲會話都會為LLM提供寶貴的人類反饋,以形成游戲中的推理軌跡。
這些游戲數據被證明對評估LLM非常有效。但在深入探討如何進行評估之前,你可能會問:為什么LLM評估如此重要?
下圖2展示了截至2025年2月5日的LMSYS聊天機器人競技場排名。
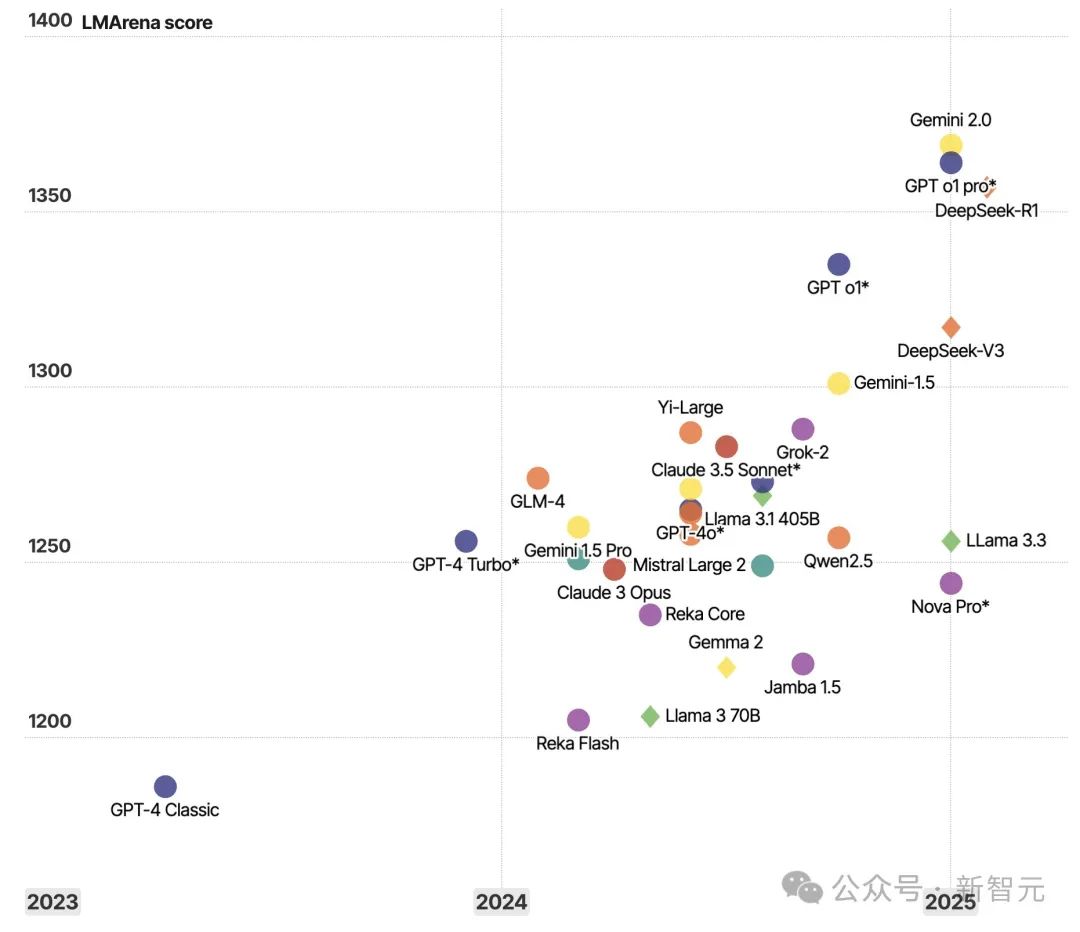
LLM正在迅速發展,變得越來越強大,并且在某些任務中經常達到甚至超越人類的表現,這就需要我們對其性能差距進行持續量化。
此外,除了在聊天應用中使用外,LLM在提高數學、編程問題的解決能力,甚至促進科學發現方面也具有巨大潛力,從而擴大了其在各個領域的影響。
這種日益增長的潛力迫切地需求一個強大的推理基準,能夠有效地對下一代模型進行排名和評估。
現有基準的局限性
靜態評估,如MMLU、Spider和HumanEval,提供了對特定能力的評估,但依賴于不太直觀的指標,如F1、BLEU和ROUGE。此外,它們的靜態性質使得這些基準更容易被LLM利用,如MT-Bench中看到的那樣。
相比之下,動態評估如Chatbot Arena提供了更加直觀的指標,如勝率或Elo分數,且更難被操控。然而,它們存在反饋率低(Chatbot Arena約為 4%),而且Elo評分中耦合了多種能力,這限制了它們評估特定技能的顆粒度。
Game Arena為何與眾不同?
為了應對上述挑戰,GameArena采用了下面幾種方法。
首先,他們引入了一種激勵性的、動態的基準,通過實時電腦游戲來評估許多現實生活中所需的互動和戰略推理任務。
其次,整個過程涉及三個推理游戲,每個游戲針對了不同的推理能力。
最后,Game Arena采用了創新的評估方法,基于游戲結果和推理過程來評估大語言模型(LLM)的能力。
下表1展示了Akinator、 Taboo和Bluffing游戲中涉及的主要推理能力。

結果排名
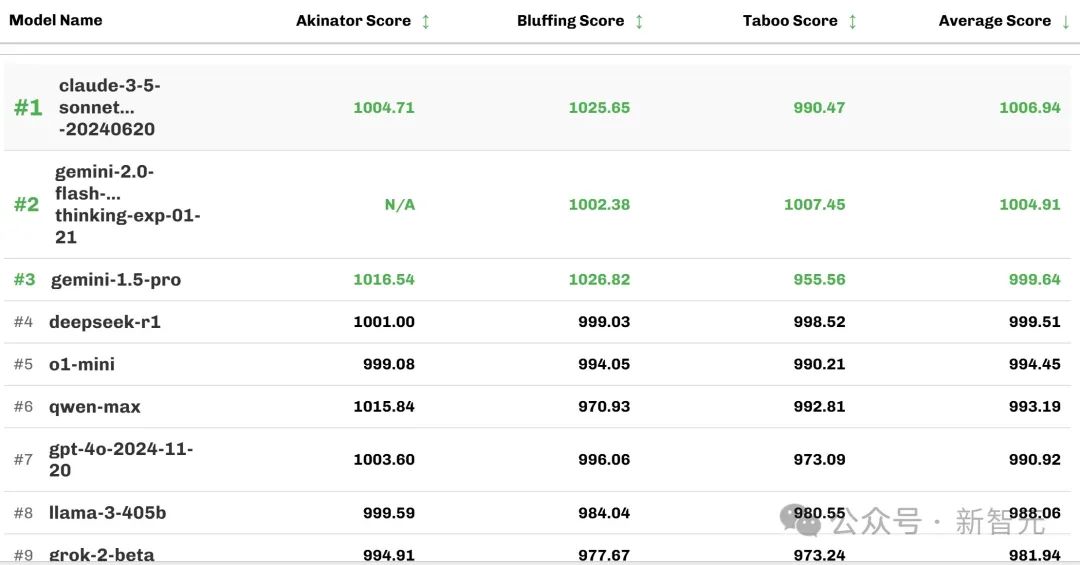
GameArena的評估結果顯示,良好對齊的模型具有強大的推理能力和多輪指令跟隨能力,例如claude-3.5-sonnet和gemini-1.5-pro在GameArena中排名靠前。
推理模型如gemini-2.0-flash-thinking-exp-01-21、deepseek-r1和o1-mini在游戲上表現良好,但會帶來輕微甚至顯著更高的延遲。
模型在較短對話中表現出色但在長時間游戲會話中推理能力較差,如Mistral-Large-2,通常在GameArena中的排名靠后。
下表2顯示截至2025年2月12日,游戲競技場的模型排名情況(按三場比賽的平均分排序)。
除此之外,團隊還進行了一項用戶研究,比較了來自GameArena的2000多場游戲會話和Chatbot Arena中相同數量會話的用戶體驗和參與意愿。
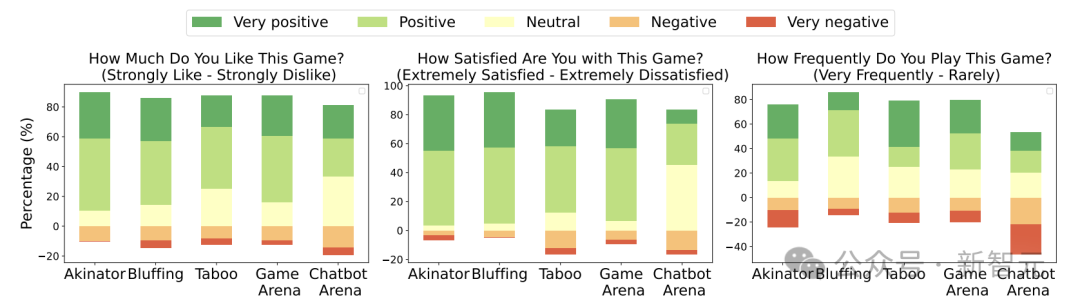
結果顯示,超過70%的用戶更喜歡GameArena中的游戲,相比之下,只有 45%的用戶表示喜歡在Chatbot Arena中做測試。超過80%的參與者對GameArena的游戲體驗表示滿意,而對Chatbot Arena表示滿意的用戶則還不到40%。
團隊發現來自GameArena的游戲會話中有約87%是完整且有用的,而Chatbot Arena中僅有4%的對話提供了有意義的對話(因為其依賴于自愿參與)。
下圖3展示了100名具有不同背景的用戶測試結果。
寫在最后
「想象一下,眾神正在玩一場像國際象棋一樣的大游戲,而你不知道規則。你偶爾可以觀察棋盤,試圖推測棋子移動的規則……后來你可能會發現主教的規則是它沿對角線移動,這也能解釋你之前對于規則的理解:它保持自己的顏色不變。」
這段比喻由著名物理學家理查德·費曼在1983年《有趣的想象》電視系列節目中提出,將理解物理學比作僅憑觀察學習國際象棋的規則。
它說明了偉大的科學家們是如何發現自然法則的:通過觀察模式并推斷出背后的原理。
四十年后的今天,隨著現代人工智能的到來,從AlphaFold-3到Deep Research,最先進的AI系統現在展現出顛覆科學探索的邏輯推斷潛力。
歸納推理的力量正從卓越的人類大腦傳遞到人工智能中。
鑒于游戲和科學推理之間的相似性,一個有趣的問題開始浮現:游戲能否作為評估人工智能能力和潛力的媒介?
帶著這些疑問和靈感,我們不懈地尋求對人工智能的更深入理解,以及在未來由超越人類能力的人工智能塑造的世界中,人類角色的演變。
















