DeepSeek 私有部署最強指南:滿血推理,異構多機分布式,國產顯卡無縫支持!
還在為DeepSeek模型部署的各種難題抓狂?各種教程的下載分片、合并模型、編譯環境……這些繁瑣的操作是不是讓你頭大?DeepSeek R1 火了,私有部署需求暴增,教程滿天飛,但實際操作起來卻麻煩得要命!更別提多機分布式推理、高并發生產環境、國產芯片適配這些復雜場景,現有方案要么配置復雜,要么性能不達標,簡直讓人崩潰!
別慌,今天介紹的GPUStack 這個開源項目(https://github.com/gpustack/gpustack/)一出手,直接解決 DeepSeek R1 私有部署的所有痛點:
? 一鍵安裝部署,Linux、macOS、Windows全平臺支持
? 模型資源需求自動計算,按需自動分布式推理,告別手動配置
? 支持 NVIDIA、AMD、Mac、海光、摩爾線程、華為昇騰等多種硬件
接下來,我們通過幾種典型的部署場景,展示 GPUStack 在面對不同環境的兼容性。
以桌面場景和生產場景為例,GPUStack 對各種部署場景都提供了強大的支持:
桌面場景
? 單機運行小參數量模型
在 Windows 和 macOS 桌面設備上,單機運行 DeepSeek R1 1.5B ~ 14B 等小參數模型。如果 VRAM 不足,GPUStack 也支持將部分模型權重加載到內存,實現 GPU & CPU 混合推理,確保在有限硬件資源下的運行。
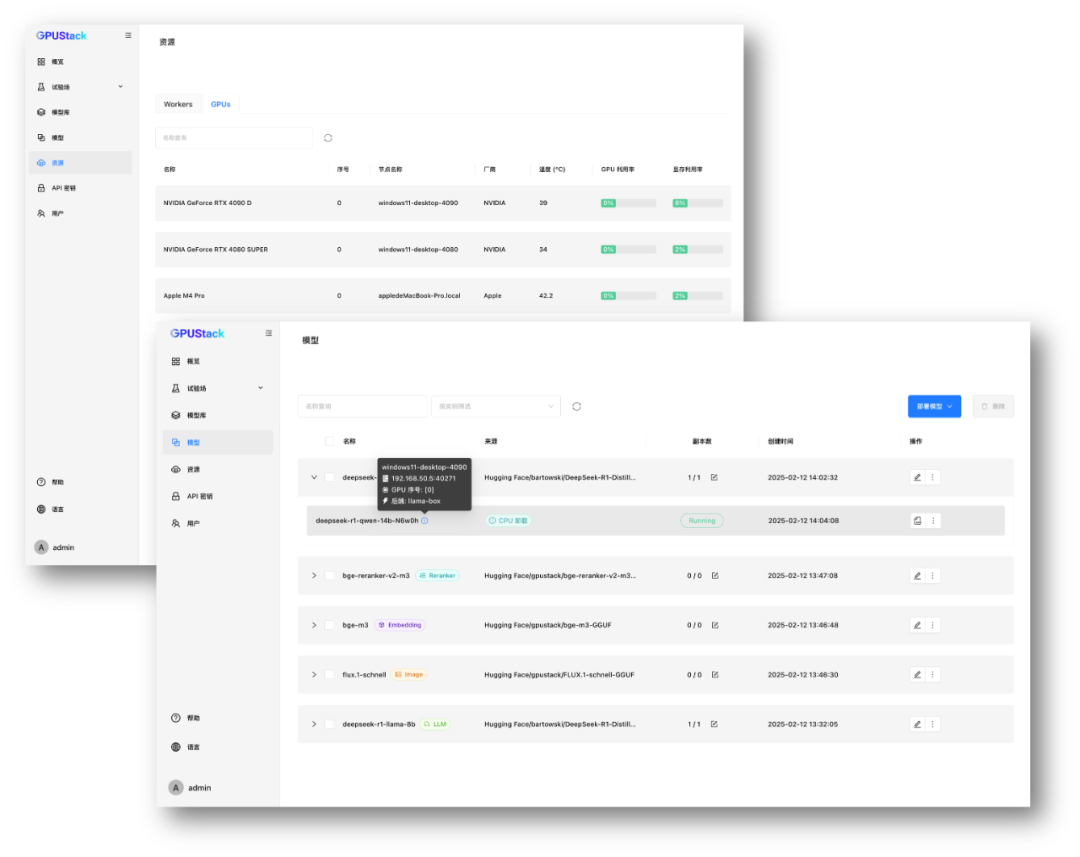
? 分布式推理運行大參數量模型
當單機無法滿足模型運行需求時,GPUStack 支持跨主機分布式推理。例如:
多機分布式推理
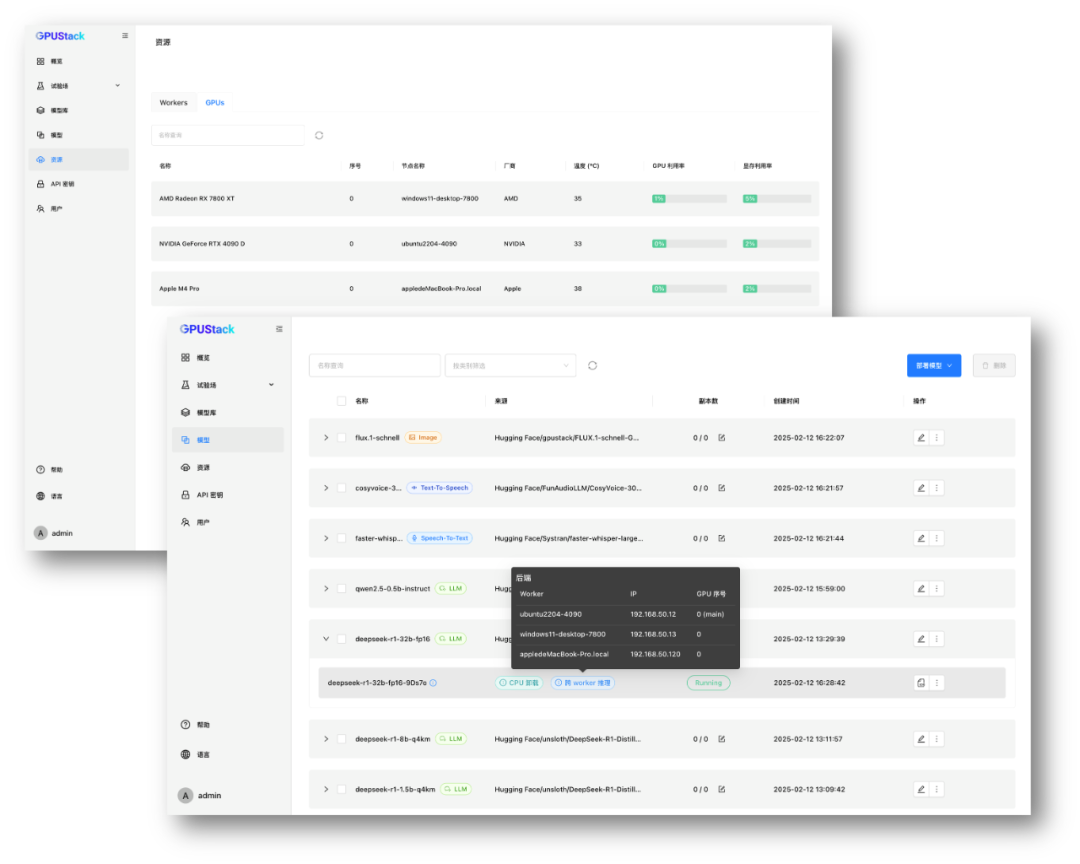
? 使用一臺 Mac Studio 可以運行 Unsloth 最低動態量化(1.58-bit)的 DeekSeek R1 671B 模型,更高的量化和動態量化版本可以通過分布式推理功能,使用兩臺 Mac Studio 分布式運行。還可以靈活多卡切分比例和滿足更多的場景需求,例如更多的分布式節點和更大的上下文設置。
異構分布式推理
使用:
? 一臺 Ubuntu 服務器,搭載 NVIDIA RTX 4090(24GB VRAM)
? 一臺 Windows 主機,搭載 AMD Radeon RX 7800(16GB VRAM)
? 一臺 MacBook Pro,搭載 M4 Pro,擁有 36GB 統一內存
聚合這些異構設備的 GPU 資源,運行單機無法運行的 DeepSeek-R1 32B 或 70B 量化蒸餾模型,充分利用多臺設備的算力來提供推理。
生產場景
? 多機部署超大模型
在 2 臺 8 卡 NVIDIA A100 服務器上,利用 GPUStack 多機分布式推理,運行 DeepSeek R1 671B 量化版本,突破單機顯存限制,高效執行超大規模模型推理。
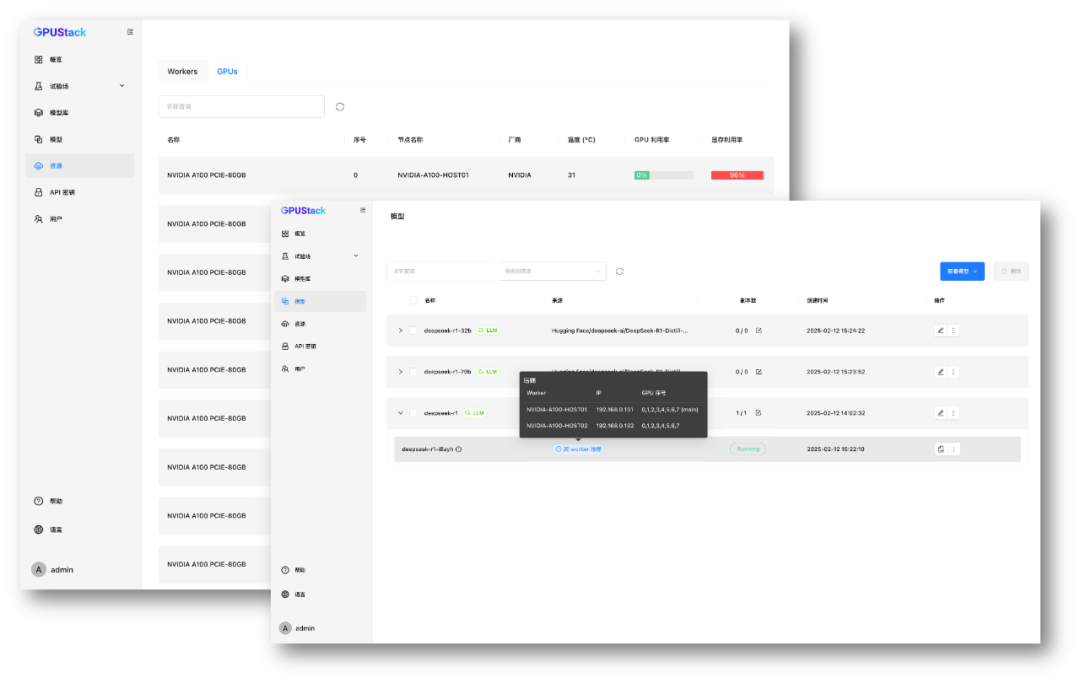 a100-distributed-interence
a100-distributed-interence
? 高并發高吞吐的生產部署
在需要高并發、高吞吐、低延遲的生產環境中,使用 vLLM 高效部署推理 DeepSeek R1 全量版或蒸餾版,充分利用推理加速技術支撐大規模并發請求,提升推理效率。
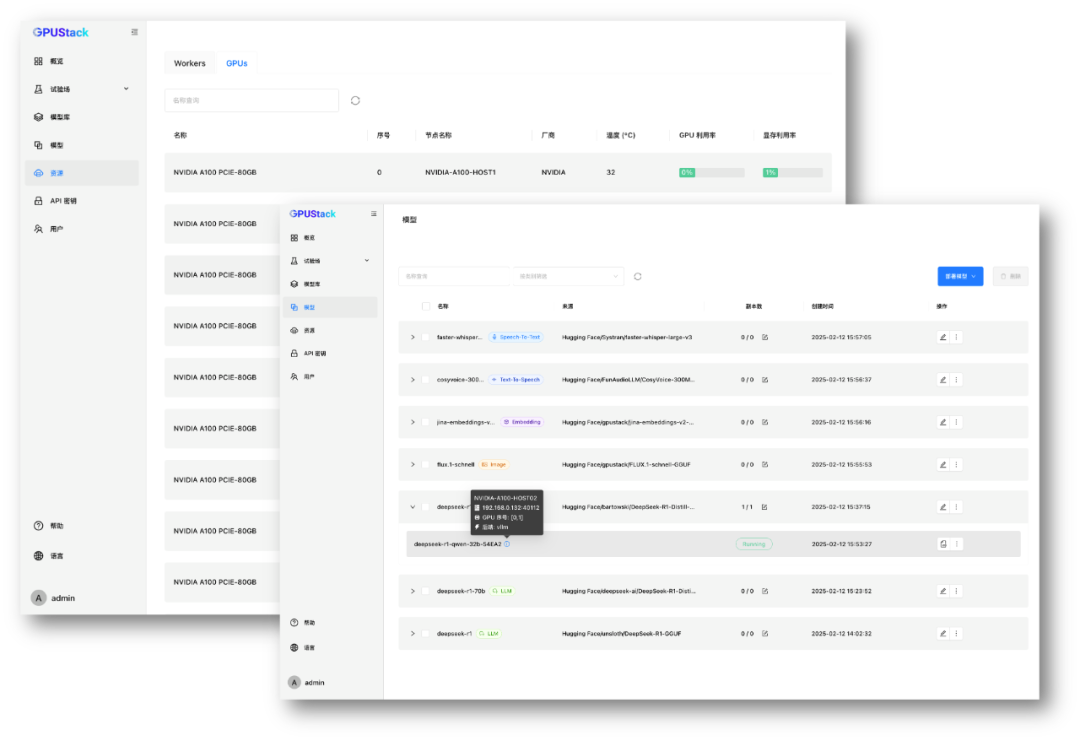 a100-vllm
a100-vllm
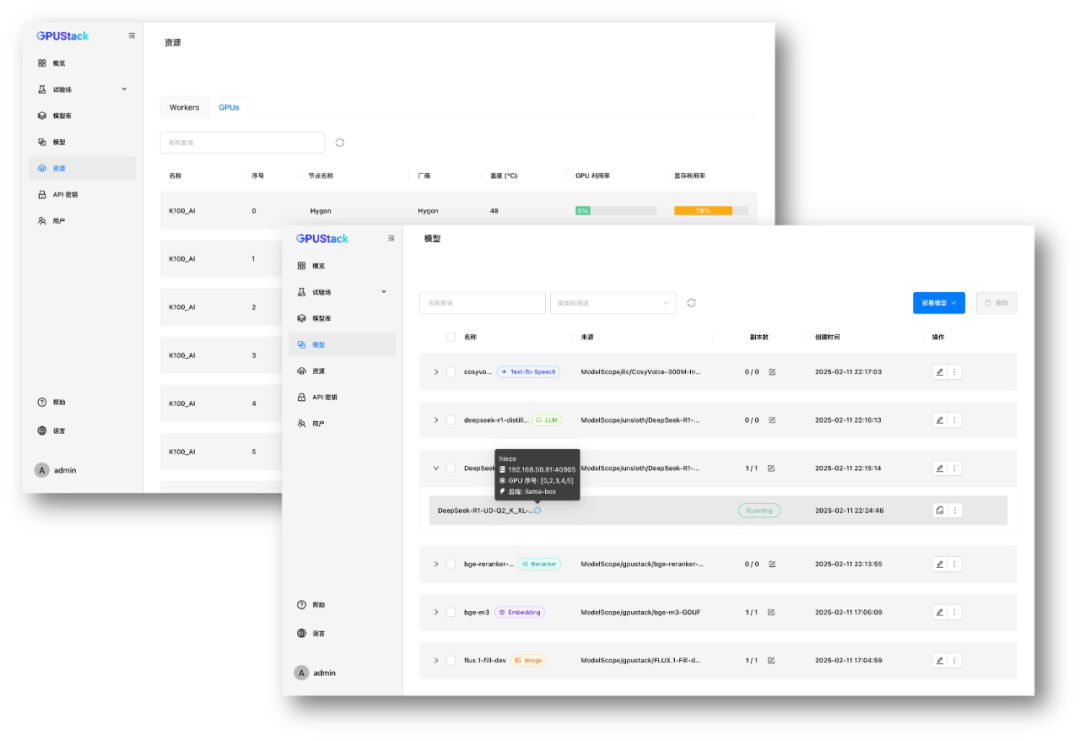
? 國產硬件適配
在昇騰、海光等國產 GPU 上,GPUStack 也提供適配支持。例如,在 8 卡海光 K100_AI 上運行 DeepSeek R1 671B 量化或蒸餾版本,充分發揮國產硬件的計算能力,實現自主可控的私有化部署方案。
對于諸如上述的各種部署場景,GPUStack 都能根據環境自動選擇最佳部署方案,提供自動化的一鍵部署,用戶不需要繁瑣的部署配置。同時用戶也擁有自主控制部署的靈活性。
以下是 DeepSeek R1 各個蒸餾模型和滿血 671B 模型在不同量化精度下的顯存需求及相應推薦硬件,供在各種場景下部署提供參考:
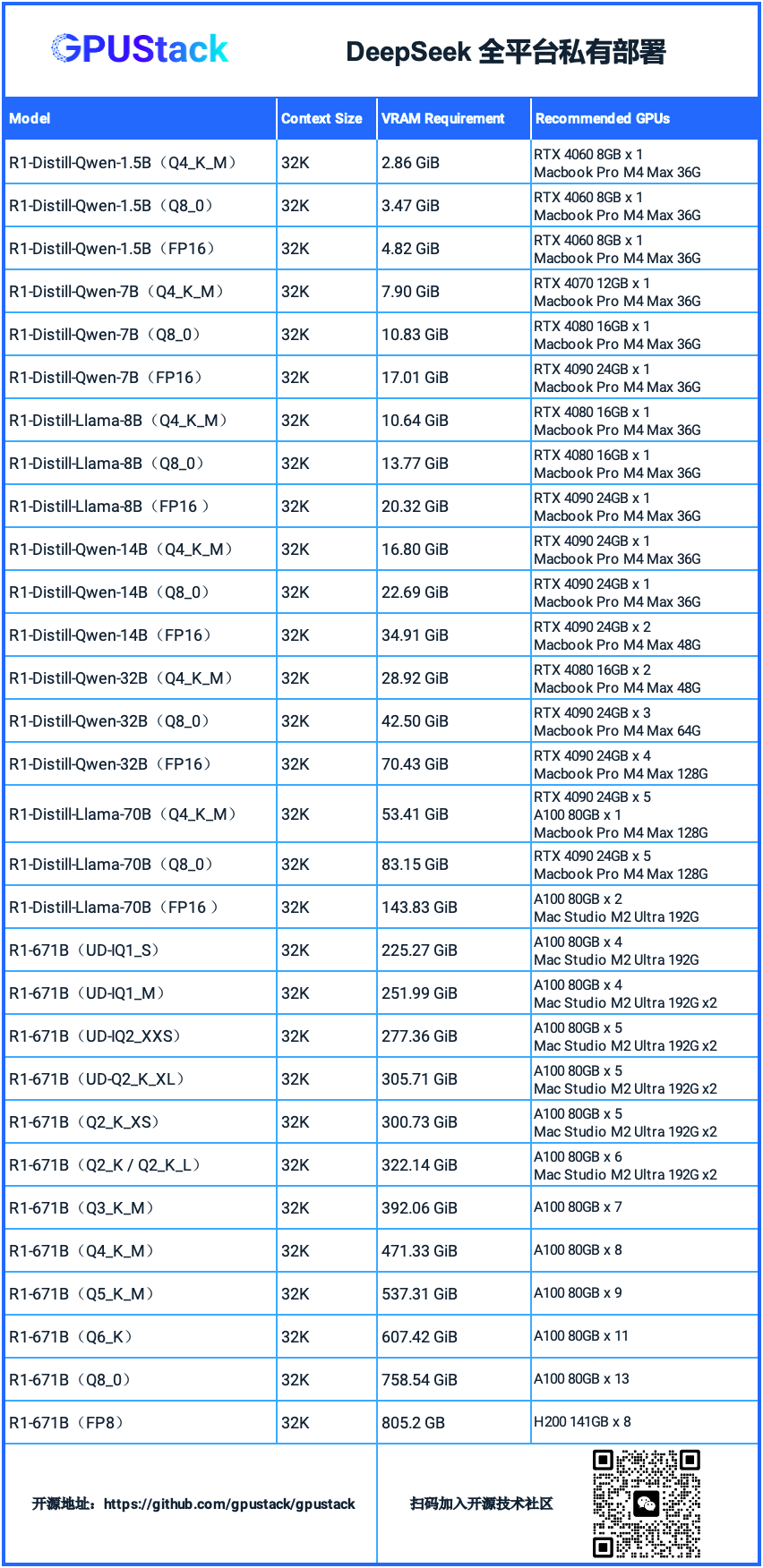
不同的模型、量化方式、上下文大小、推理參數設置或多卡并行配置對顯存需求各不相同。對于 GGUF 模型,可以使用模型資源測算工具 GGUF Parser(https://github.com/gpustack/gguf-parser-go)來手動計算的顯存需求。實際部署時,GPUStack 會自動計算并分配適合的顯存資源,無需用戶手動配置。
 gguf-parser
gguf-parser
GPUStack 不僅支持 大語言模型(LLM),還支持更多生成式 AI 模型類型,包括:
? 多模態模型(如 Qwen2-VL、InternVL 2.5)
? 圖像生成模型(如 Stable Diffusion、Flux)
? 語音模型(STT/TTS)(如 Whisper、CosyVoice)
? Embedding 模型(如 BGE、BCE、Jina)
? Reranker 模型(如 BGE Reranker、Jina Reranker)
無論是在桌面端還是數據中心,GPUStack 都能滿足各種環境和應用場景下的私有模型部署需求,提供高效、靈活的推理解決方案。
GPUStack 更是一個綜合性的解決方案,提供國產化支持、就地升級、模型升級、推理引擎多版本并存、負載均衡高可用、用戶管理、API 認證授權、GPU 和 LLM 觀測指標、Dashboard 儀表板、離線部署等各種運維管理能力,幫助開發和運維人員輕松應對異構適配、模型迭代、權限控制、運維觀測等管理需求,降低了大模型部署和管理的復雜度。
如果對 GPUStack 感興趣,可以參考以下步驟進行安裝部署。
安裝 GPUStack
安裝要求參考:https://docs.gpustack.ai/latest/installation/installation-requirements/
GPUStack 支持腳本一鍵安裝、容器安裝、pip 安裝等各種安裝方式,這里使用腳本方式安裝。
在 Linux 或 macOS 上:
通過以下命令在線安裝,安裝完成需要輸入 sudo 密碼啟動服務,這個步驟需要聯網下載各種依賴包,網絡不好可能需要花費十幾到幾十分鐘的時間:
curl -sfL https://get.gpustack.ai | INSTALL_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple sh -s -在 Windows 上:
以管理員身份運行 Powershell,通過以下命令在線安裝,這個步驟需要聯網下載各種依賴包,網絡不好可能需要花費十幾到幾十分鐘的時間:
$env:INSTALL_INDEX_URL = "https://pypi.tuna.tsinghua.edu.cn/simple"
Invoke-Expression (Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content當看到以下輸出時,說明已經成功部署并啟動了 GPUStack:
[INFO] Install complete.
GPUStack UI is available at http://localhost.
Default username is 'admin'.
To get the default password, run 'cat /var/lib/gpustack/initial_admin_password'.
CLI "gpustack" is available from the command line. (You may need to open a new terminal or re-login for the PATH changes to take effect.)接下來按照腳本輸出的指引,拿到登錄 GPUStack 的初始密碼,執行以下命令:
在 Linux 或 macOS 上:
cat /var/lib/gpustack/initial_admin_password在 Windows 上:
Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustack\initial_admin_password") -Raw在瀏覽器訪問 GPUStack UI,用戶名 admin,密碼為上面獲得的初始密碼。
重新設置密碼后,進入 GPUStack:
 overview
overview
納管 GPU 資源
GPUStack 支持納管 Linux、Windows 和 macOS 設備的異構 GPU 資源,步驟如下。
其他節點需要通過認證 Token 加入 GPUStack 集群,在 GPUStack Server 節點執行以下命令獲取 Token:
在 Linux 或 macOS 上:
cat /var/lib/gpustack/token在 Windows 上:
Get-Content -Path (Join-Path -Path $env:APPDATA -ChildPath "gpustack\token") -Raw拿到 Token 后,在其他節點上運行以下命令添加 Worker 到 GPUStack,納管這些節點的 GPU(將其中的 http://YOUR_IP_ADDRESS
在 Linux 或 macOS 上:
curl -sfL https://get.gpustack.ai | INSTALL_INDEX_URL=https://pypi.tuna.tsinghua.edu.cn/simple sh -s - --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN在 Windows 上:
$env:INSTALL_INDEX_URL = "https://pypi.tuna.tsinghua.edu.cn/simple"
Invoke-Expression "& { $((Invoke-WebRequest -Uri "https://get.gpustack.ai" -UseBasicParsing).Content) } -- --server-url http://YOUR_IP_ADDRESS --token YOUR_TOKEN"通過以上步驟,我們已經安裝好 GPUStack 并納管了多個 GPU 節點,接下來就可以使用這些 GPU 資源來部署所需的各種 DeekSeek R1 滿血、量化、蒸餾模型和其他模型了。
總結
以上是關于如何安裝 GPUStack 并在不同場景下部署 DeekSeek R1 模型的使用教程。你可以訪問項目的開源倉庫:https://github.com/gpustack/gpustack 了解更多信息。
GPUStack 是一個低門檻、易上手、開箱即用的私有大模型服務平臺。它可以輕松整合并利用各種異構 GPU 資源,方便快捷地為生成式 AI 應用和應用開發人員部署所需的各種 AI 模型。
無論是 Linux、Windows 還是 macOS,或是各種單機、多機異構部署場景,GPUStack 都能一鍵部署各種生成式 AI 模型,且不局限于大語言模型,還支持多模態模型、圖像模型、語音模型、Embedding 模型以及 Reranker 模型,滿足各種環境和應用場景的私有模型部署需求。
GPUStack 背后的研發團隊具有全球頂級開源項目經驗,項目的功能設計和文檔都很完整,團隊自項目初期便面向全球用戶,當前已有大量國內外開源用戶。團隊致力于將國產開源項目推廣到全球,值得關注。
在開始體驗 GPUStack 之前,記得在其 GitHub 倉庫給項目點個 Star 以資鼓勵,在新版本發布時也能收到更新通知:https://github.com/gpustack/gpustack。