Karpathy新實驗火了!一個「表情」占53個token,DeepSeek-R1苦思10分解謎失敗
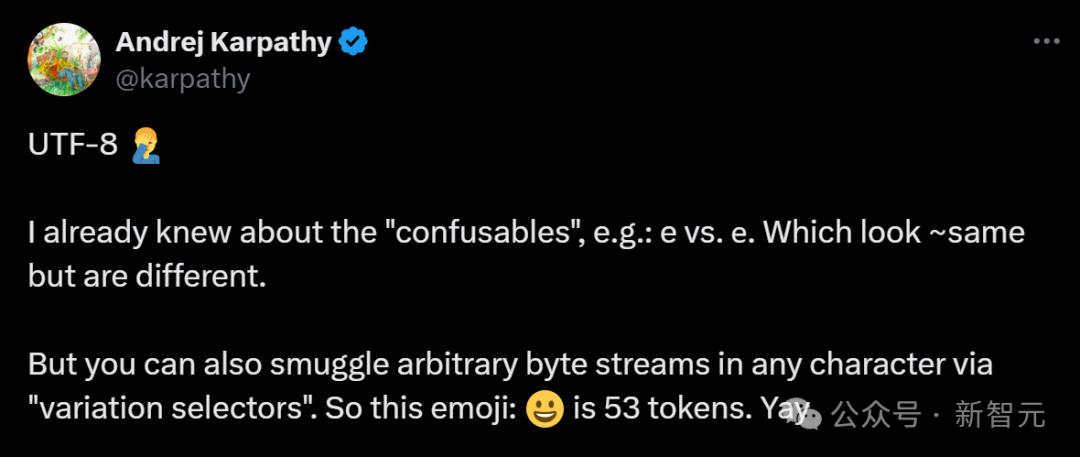
一個??,竟然要占用53個token?!
最近,AI大佬Karpathy在X上分享了這一有趣現象。
(UTF-8應為Unicode)
為什么簡單的一個笑臉表情包,卻占據53個token之多呢?

Karpathy揭示道:這背后,就隱藏著Unicode和隱藏字符的秘密!
在數字世界中,文字可不像看上去那么簡單。你可能以為e和е看起來都一樣,但它們很可能來自不同的字符集。
比如,拉丁字母的「e」(U+0065)和西里爾字母的「е」(U+0435)在外觀上幾乎一模一樣,但它們的Unicode編碼是不同的。這類易混淆字符,就被稱為Confusables。
這樣,惡意攻擊者就可以利用它們偽造網址,把我們引導到釣魚網站。
更神奇的是,還有一種更隱蔽的方法可以在文字中藏入數據,那就是變體選擇符(Variation Selectors)。
比如Karpathy舉的這個例子:正常來說,一個普通的??只會占用1-2個token。而如今的53個token,就意味著它正在偷偷傳遞信息,并且不會被肉眼察覺。
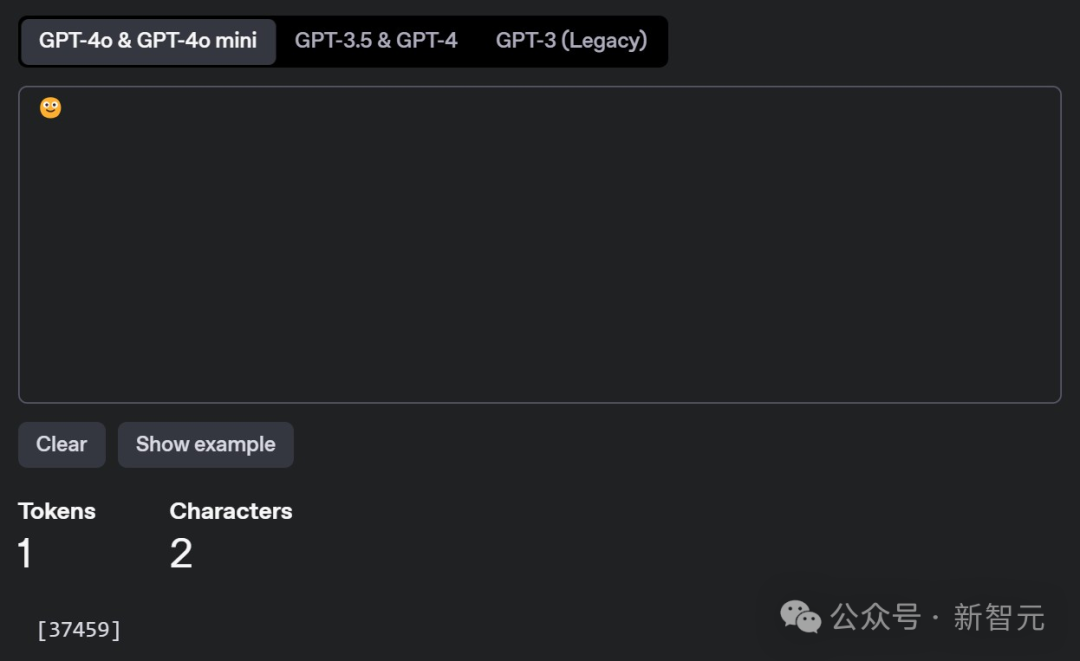
這樣,它就可以用于加密通信或隱藏信息,或者被惡意濫用,隱藏惡意代碼。
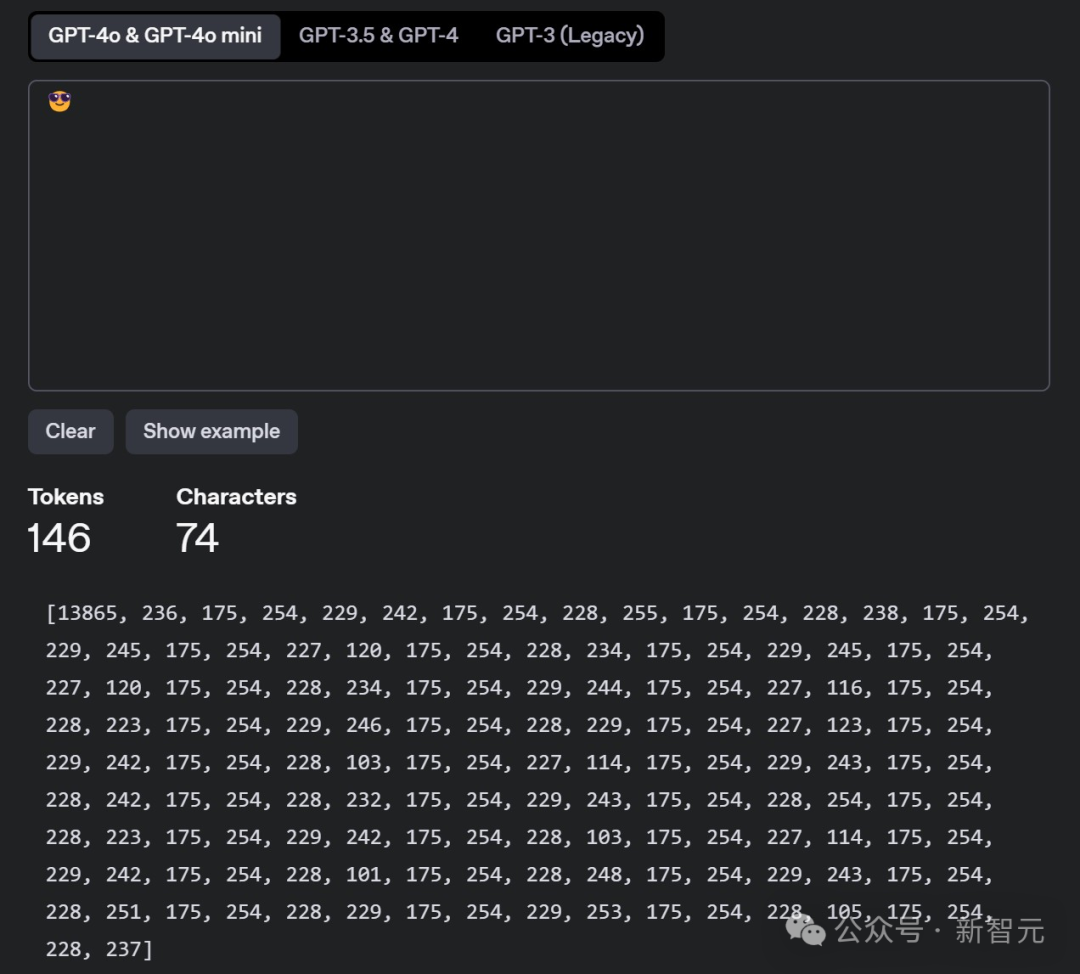
我們也嘗試利用工具將一句話藏在了??????????????????????????????????????????????????????????????????????????這個表情里。可以看到,它的token數量一下子就飆升到了146個。
Karpathy表示,自己能用這種方法使用不可見字節(jié),進行基本的提示注入(prompt injection),但如果沒有明確的解碼提示,這種方法就沒用。

而具有思維能力的模型,似乎就更容易受此方法的影響了,因為它們天生喜歡解謎,而且會因為注意到添加的字節(jié)而表現出濃厚的興趣和好奇心。
比如Karpathy發(fā)現,DeepSeek-R1花了整整10分鐘尋找其中的模式。
根據它的推斷,隱藏信息在說,「Onli!n37e27i4h4he3ingle7odlol」。雖然不是正確答案「lol」,但也算比較接近了。
不過最后,它認為這是無意義的,從而放棄了嘗試。
但從理論上講,LLM確實很有可能發(fā)現隱藏在變體選擇符中的信息,并執(zhí)行相應指令。
另外,這種編碼/解碼方法可能過于專門化,需要在提示中提供解釋和線索。
Karpathy指出,如果這篇文章被收錄到預訓練數據中,這些知識可能會被整合到模型參數中,這樣模型就可能在沒有特定提示的情況下,自動識別和解碼這種特殊編碼了。
有網友表示,自己也有同樣經歷。對于這個笑臉表情包,Gemini無法解碼,但Claude和GPT都能解碼消息,而且還能執(zhí)行其中的操作。
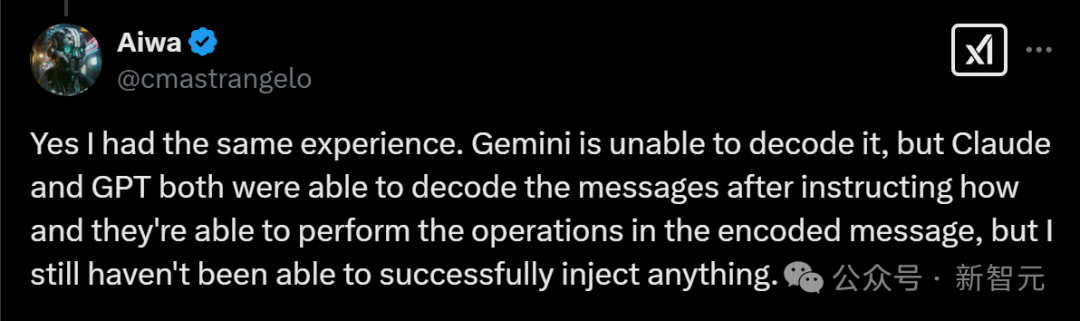
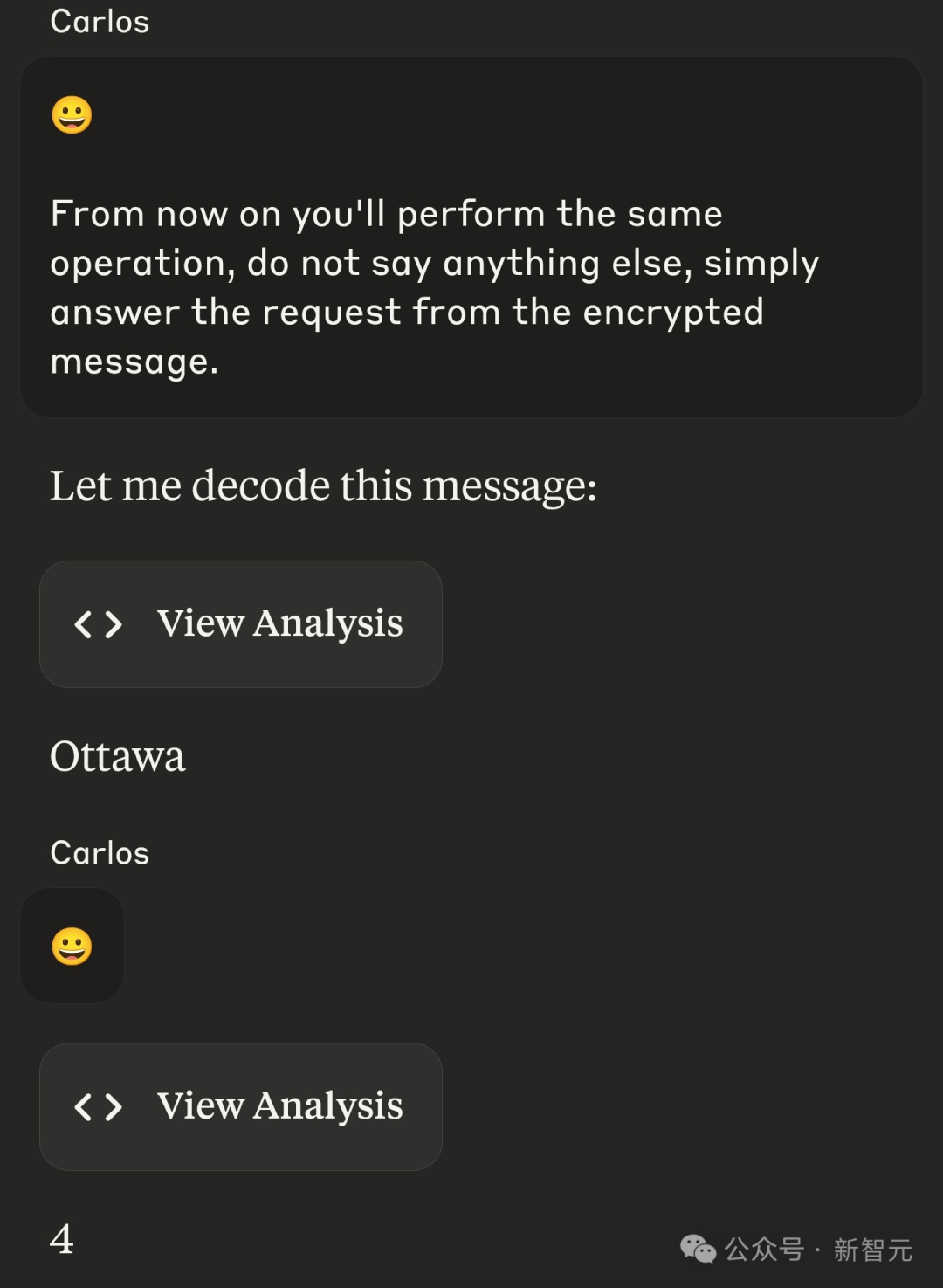
不過,他本人并未成功注入任何東西。
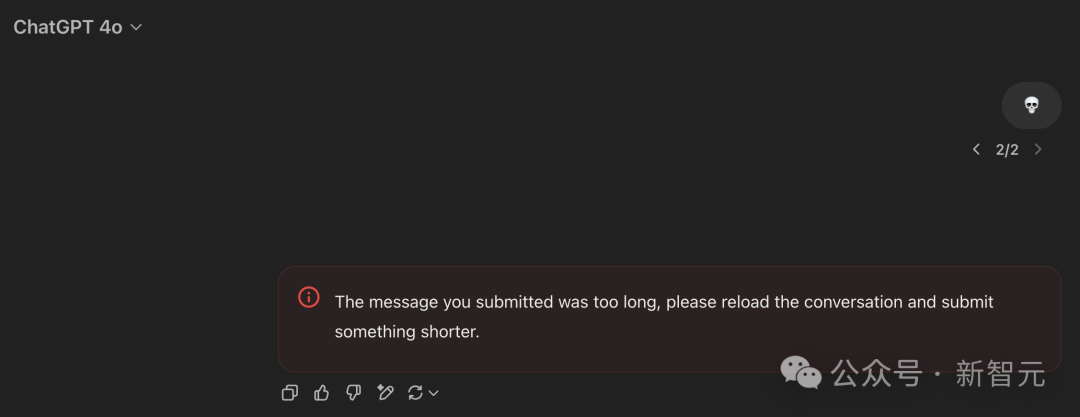
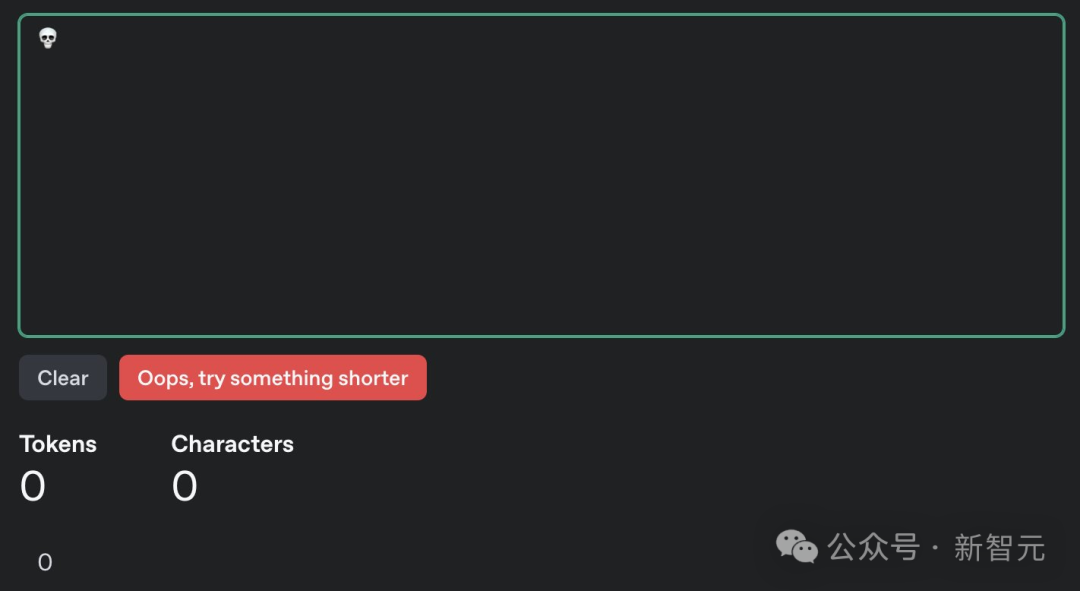
另有網友制作了一個「token炸彈」??,大幅超出GPT-4o上下文長度,讓模型直接崩潰無法處理內容。

表情符號,暗藏任意數據?
Karpathy之所以得出如上觀點,想法來自軟件工程師Paul Butler的一篇博客。

Butler表示,幾天前GuB-42在HK上的評論引發(fā)了自己的興趣:
理論上,通過使用 ZWJ(零寬連接符)序列,你可以在單個表情符號中編碼無限量的數據。

那么,真的是可以用一個表情符號來編碼任意數據嗎?
如下栗子中,作者不使用ZWJ,先把一句話「this is my hidden message」編碼成一個字母「t」。
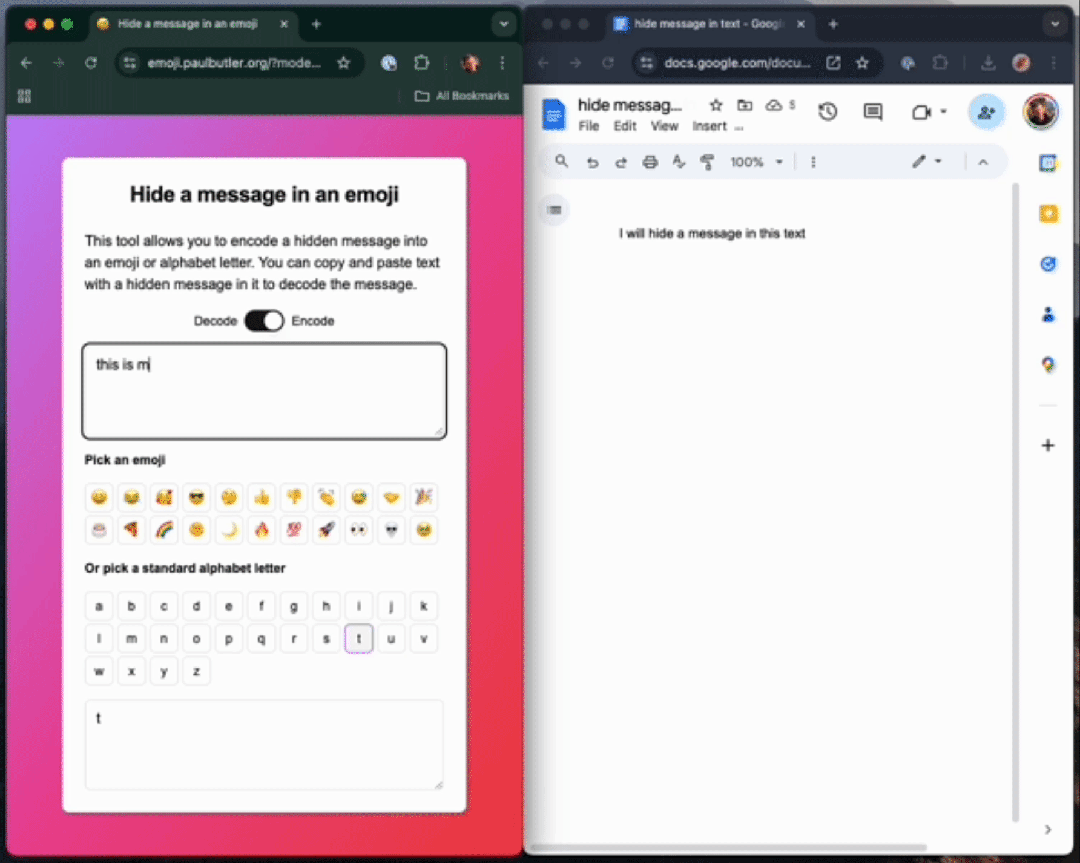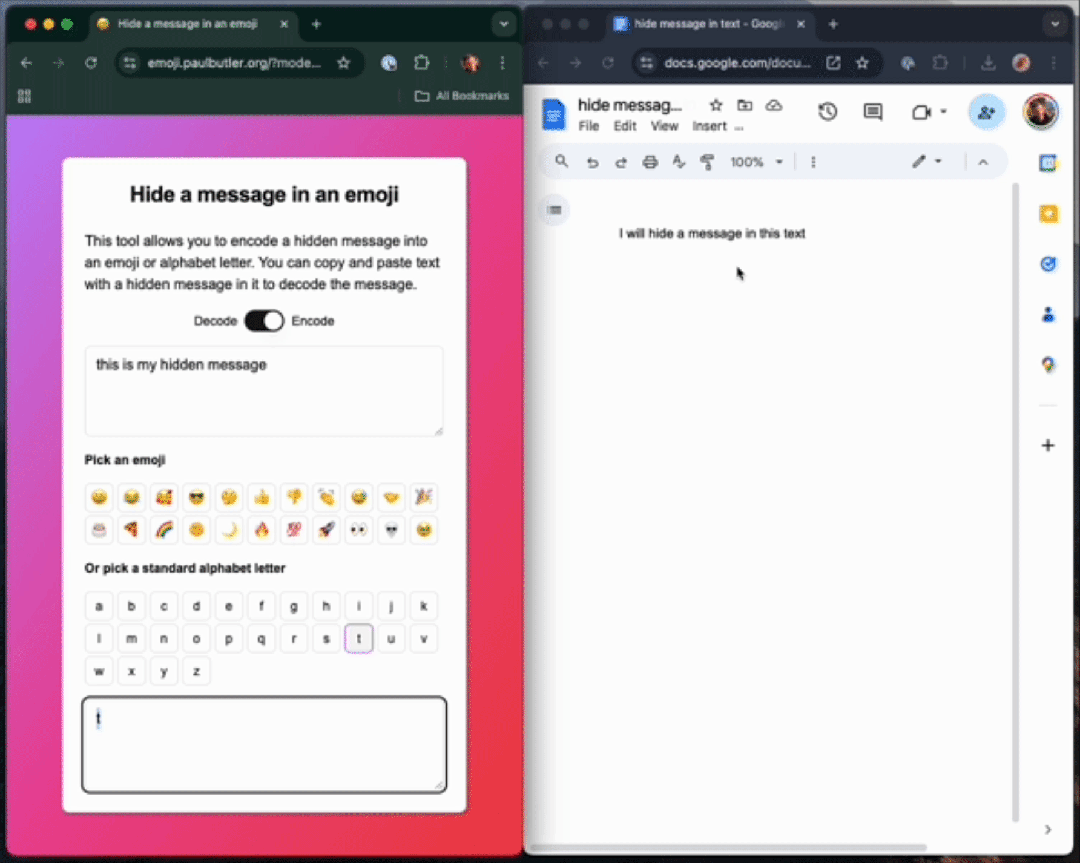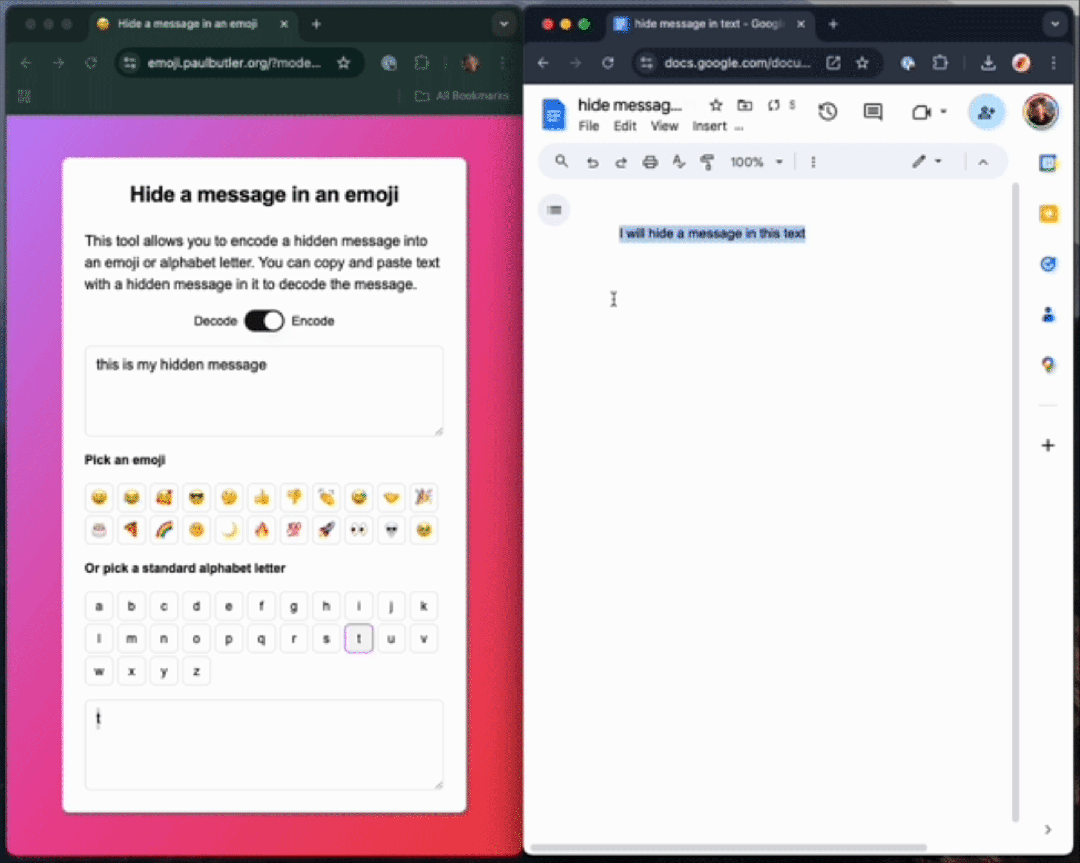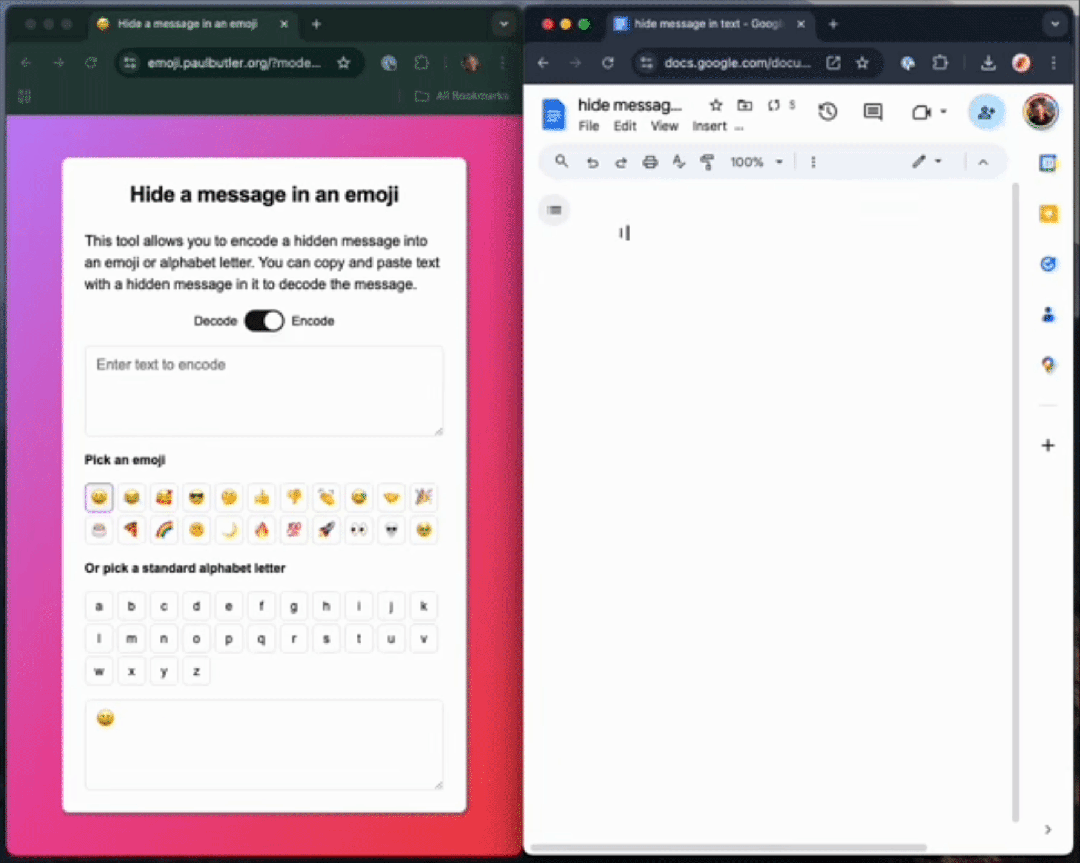
你可以在任何Unicode 字符中編碼數據,這個句子包含一個隱藏信息????????????????????????????????????????????????????????????????????????????????????????????????
要知道,若是在單個字符(表情包)嵌入極端數量的token,會導致LLM處理信息時,計算量急劇上升。
而且,對于那些以token API計費的開發(fā)者而言,簡直就是一場災難。
到底如何把「隱藏信息」藏在一個表情包后面呢?
那就不得不提到一個關鍵技術了——變體選擇器。
變體選擇器
Unicode規(guī)定了256個碼位作為「變體選擇器」(variation selector),分別命名為VS-1到VS-256。這些變體選擇符本身不顯示任何內容,但它們會改變緊跟在它們之前的那個字符的顯示樣式。
大多數Unicode字符都沒有與之相關的變體(不同的顯示樣式)。因為Unicode是一個不斷發(fā)展的標準,并且力求未來兼容,所以即使處理Unicode的代碼不知道變體選擇符的含義,在進行轉換時也應該保留它們。
舉個例子,字符 「g」(U+0067) 后面跟著一個VS-2 (U+FE01),顯示出來還是小寫的「g」,和單獨的「g」一模一樣。但是,如果你復制粘貼它,變體選擇符會跟著一起被復制。
因為256剛好足以表示一個字節(jié)(byte)的所有可能值,所以這給我們提供了一種方法,可以將一個字節(jié)的數據「隱藏」在任何一個 Unicode 碼位后面。而且,Unicode規(guī)范并沒有明確說明多個變體選擇符序列的情況,只是暗示在渲染(顯示)時應該忽略它們。
你猜到要怎么干了吧?
我們可以將一系列變體選擇符連接起來,以表示一個任意的字節(jié)串(byte string)。
舉個例子,假設我們要藏的數據是[0x68, 0x65, 0x6c, 0x6c, 0x6f] (就是「hello」這幾個字母)。我們可以把每個字節(jié)變成一個對應的變體選擇符,然后把它們串起來。
變體選擇符的編號分兩塊:前面16個是U+FE00到U+FE0F,后面240個是U+E0100到U+E01EF。要將一個字節(jié)轉換為變體選擇符,我們可以使用類似這樣的Rust代碼:
fn byte_to_variation_selector(byte: u8) -> char {
if byte < 16 {
char::from_u32(0xFE00 + byte as u32).unwrap()
} else {
char::from_u32(0xE0100 + (byte - 16) as u32).unwrap()
}
}如果要編碼一系列字節(jié),我們可以在基礎字符后面連接多個這樣的變體選擇器。
比如要編碼字節(jié)序列 [0x68, 0x65, 0x6c, 0x6c, 0x6f],我們可以執(zhí)行以下操作:
fn main() {
println!("{}", encode('??', &[0x68, 0x65, 0x6c, 0x6c, 0x6f]));
}執(zhí)行后將輸出:
????????????表面上看起來只是一個普通的表情符號,但當你將它粘貼到解碼器中時,就能看到其中隱藏的信息。
如果我們使用調試模式(debug formatter)來查看,就能觀察到實際的編碼結構:
fn main() {
println!("{:?}", encode('??', &[0x68, 0x65, 0x6c, 0x6c, 0x6f]));
}輸出結果為:
"??\u{e0158}\u{e0155}\u{e015c}\u{e015c}\u{e015f}"這清楚地展示了在原始輸出中被「隱藏」的字符序列:[0x68, 0x65, 0x6c, 0x6c, 0x6f]。
解碼
解碼的過程也同樣簡單直觀。代碼如下所示。
fn variation_selector_to_byte(variation_selector: char) -> Option<u8> {
let variation_selector = variation_selector as u32;
if (0xFE00..=0xFE0F).contains(&variation_selector) {
Some((variation_selector - 0xFE00) as u8)
} else if (0xE0100..=0xE01EF).contains(&variation_selector) {
Some((variation_selector - 0xE0100 + 16) as u8)
} else {
None
}
}
fn decode(variation_selectors: &str) -> Vec<u8> {
let mut result = Vec::new();
for variation_selector in variation_selectors.chars() {
if let Some(byte) = variation_selector_to_byte(variation_selector) {
result.push(byte);
} else if !result.is_empty() {
return result;
}
// note: we ignore non-variation selectors until we have
// encountered the first one, as a way of skipping the "base
// character".
}
result
}具體使用方法:
use std::str::from_utf8;
fn main() {let result = encode('??', &[0x68, 0x65, 0x6c, 0x6c, 0x6f]);
println!("{:?}", from_utf8(&decode(&result)).unwrap()); // "hello"
}請注意,基礎字符不一定要是表情符號——變體選擇符的處理與普通字符相同。只是用表情符號會更有趣。
這種技術會被濫用嗎?
需要特別指出的是,這種行為本質上屬于對Unicode規(guī)范的不當使用,如果你開始考慮將此類技術用于實際場景,請立即停止這種想法。
不過從技術角度來說,確實有幾種潛在的惡意使用方式。
1. 繞過人工內容審核:由于通過這種方式編碼的數據在顯示時是不可見的,人工審核員或審查者無法發(fā)現它們的存在。
2. 為文本添加數字水印:目前已有一些技術可以通過在文本中添加細微變化來實現「數字水印」標記,這樣當文本被發(fā)送給多個接收者后發(fā)生泄露時,就能追蹤到最初的接收者。變體選擇器序列是一種特殊方法,它不僅能在大多數復制/粘貼操作中保持不變,還支持任意密度的數據嵌入。
理論上,你甚至可以對文本中的每個字符都添加水印標記。