大模型強(qiáng)化學(xué)習(xí)新發(fā)現(xiàn):刪減84%數(shù)據(jù)反提升效果
在人工智能領(lǐng)域,"更大即更強(qiáng)" 的理念一直主導(dǎo)著大模型強(qiáng)化學(xué)習(xí)的發(fā)展方向。特別是在提升大語言模型的推理能力方面,業(yè)界普遍認(rèn)為需要海量的強(qiáng)化學(xué)習(xí)訓(xùn)練數(shù)據(jù)才能獲得突破。然而,最新研究卻給出了一個令人驚喜的發(fā)現(xiàn):在強(qiáng)化學(xué)習(xí)訓(xùn)練中,數(shù)據(jù)的學(xué)習(xí)影響力遠(yuǎn)比數(shù)量重要。通過分析模型的學(xué)習(xí)軌跡,研究發(fā)現(xiàn)精心選擇的 1,389 個高影響力樣本,就能超越完整的 8,523 個樣本數(shù)據(jù)集的效果。這一發(fā)現(xiàn)不僅挑戰(zhàn)了傳統(tǒng)認(rèn)知,更揭示了一個關(guān)鍵事實(shí):提升強(qiáng)化學(xué)習(xí)效果的關(guān)鍵,在于找到與模型學(xué)習(xí)歷程高度匹配的訓(xùn)練數(shù)據(jù)。

- 論文標(biāo)題:LIMR: Less is More for RL Scaling
- 論文地址:https://arxiv.org/pdf/2502.11886
- 代碼地址:https://github.com/GAIR-NLP/LIMR
- 數(shù)據(jù)集地址:https://huggingface.co/datasets/GAIR/LIMR
- 模型地址:https://huggingface.co/GAIR/LIMR
一、挑戰(zhàn)傳統(tǒng):重新思考強(qiáng)化學(xué)習(xí)的數(shù)據(jù)策略
近期,強(qiáng)化學(xué)習(xí)在提升大語言模型的推理能力方面取得了顯著成效。從 OpenAI 的 o1 到 Deepseek R1,再到 Kimi1.5,這些模型都展示了強(qiáng)化學(xué)習(xí)在培養(yǎng)模型的自我驗(yàn)證、反思和擴(kuò)展思維鏈等復(fù)雜推理行為方面的巨大潛力。這些成功案例似乎在暗示:要獲得更強(qiáng)的推理能力,就需要更多的強(qiáng)化學(xué)習(xí)訓(xùn)練數(shù)據(jù)。
然而,這些開創(chuàng)性工作留下了一個關(guān)鍵問題:到底需要多少訓(xùn)練數(shù)據(jù)才能有效提升模型的推理能力?目前的研究從 8000 到 150000 數(shù)據(jù)量不等,卻沒有一個明確的答案。更重要的是,這種數(shù)據(jù)規(guī)模的不透明性帶來了兩個根本性挑戰(zhàn):
- 研究團(tuán)隊(duì)只能依靠反復(fù)試錯來確定數(shù)據(jù)量,這導(dǎo)致了大量計(jì)算資源的浪費(fèi)
- 領(lǐng)域內(nèi)缺乏對樣本數(shù)量如何影響模型性能的系統(tǒng)性分析,使得難以做出合理的資源分配決策
這種情況促使研究團(tuán)隊(duì)提出一個更本質(zhì)的問題:是否存在一種方法,能夠識別出真正對模型學(xué)習(xí)有幫助的訓(xùn)練數(shù)據(jù)?研究從一個基礎(chǔ)場景開始探索:直接從基座模型出發(fā),不借助任何數(shù)據(jù)蒸餾(類似 Deepseek R1-zero 的設(shè)置)。通過深入研究模型在強(qiáng)化學(xué)習(xí)過程中的學(xué)習(xí)軌跡,研究發(fā)現(xiàn):并非所有訓(xùn)練數(shù)據(jù)都對模型的進(jìn)步貢獻(xiàn)相同。有些數(shù)據(jù)能夠顯著推動模型的學(xué)習(xí),而有些則幾乎沒有影響。
這一發(fā)現(xiàn)促使研究團(tuán)隊(duì)開發(fā)了學(xué)習(xí)影響力度量(Learning Impact Measurement, LIM)方法。通過分析模型的學(xué)習(xí)曲線,LIM 可以自動識別那些與模型學(xué)習(xí)進(jìn)程高度匹配的 "黃金樣本"。實(shí)驗(yàn)結(jié)果證明了這一方法的有效性:
- 精選的 1,389 個樣本就能達(dá)到甚至超越使用 8,523 個樣本的效果。
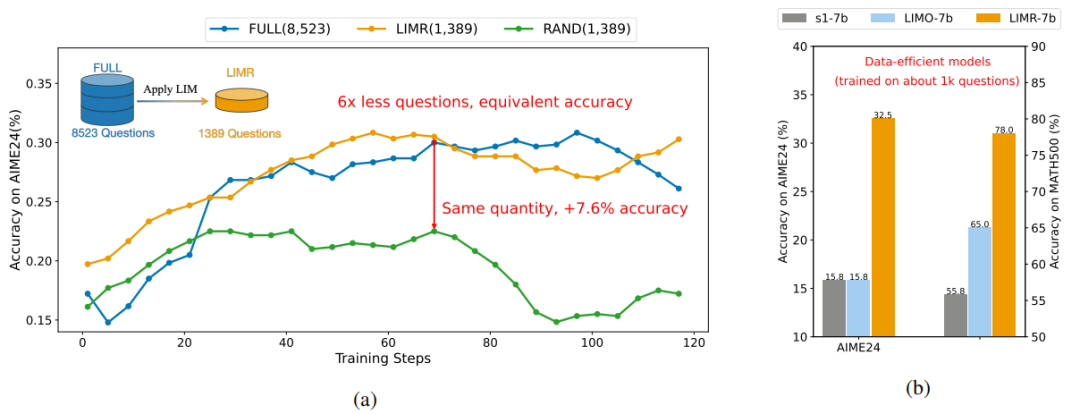
精選 1,389 個樣本就能達(dá)到全量數(shù)據(jù)的效果,在小模型上強(qiáng)化學(xué)習(xí)優(yōu)于監(jiān)督微調(diào)
這些發(fā)現(xiàn)更新了學(xué)術(shù)界對強(qiáng)化學(xué)習(xí)擴(kuò)展的認(rèn)知:提升模型性能的關(guān)鍵不在于簡單地增加數(shù)據(jù)量,而在于如何找到那些真正能促進(jìn)模型學(xué)習(xí)的高質(zhì)量樣本。更重要的是,這項(xiàng)研究提供了一種自動化的方法來識別這些樣本,使得高效的強(qiáng)化學(xué)習(xí)訓(xùn)練成為可能。
二、尋找 "黃金" 樣本:數(shù)據(jù)的學(xué)習(xí)影響力測量(LIM)
要找到真正有價值的訓(xùn)練樣本,研究團(tuán)隊(duì)深入分析了模型在強(qiáng)化學(xué)習(xí)過程中的學(xué)習(xí)動態(tài)。通過對 MATH-FULL 數(shù)據(jù)集(包含 8,523 個不同難度級別的數(shù)學(xué)問題)的分析,研究者發(fā)現(xiàn)了一個有趣的現(xiàn)象:不同的訓(xùn)練樣本對模型學(xué)習(xí)的貢獻(xiàn)存在顯著差異。
學(xué)習(xí)軌跡的差異性
在仔細(xì)觀察模型訓(xùn)練過程中的表現(xiàn)時,研究者發(fā)現(xiàn)了三種典型的學(xué)習(xí)模式:
- 部分樣本的獎勵值始終接近零,表明模型對這些問題始終難以掌握
- 某些樣本能迅速達(dá)到高獎勵值,顯示模型很快就掌握了解決方法
- 最有趣的是那些展現(xiàn)出動態(tài)學(xué)習(xí)進(jìn)展的樣本,它們的獎勵值呈現(xiàn)不同的提升速率
這一發(fā)現(xiàn)引發(fā)了一個關(guān)鍵思考:如果能夠找到那些最匹配模型整體學(xué)習(xí)軌跡的樣本,是否就能實(shí)現(xiàn)更高效的訓(xùn)練?

(a) 不同訓(xùn)練樣本在訓(xùn)練過程中展現(xiàn)出的多樣化學(xué)習(xí)模式。(b) 樣本學(xué)習(xí)軌跡與平均獎勵曲線(紅色)的比較。
LIM:一種自動化的樣本評估方法
基于上述觀察,研究團(tuán)隊(duì)開發(fā)了學(xué)習(xí)影響力測量(Learning Impact Measurement, LIM)方法。LIM 的核心思想是:好的訓(xùn)練樣本應(yīng)該與模型的整體學(xué)習(xí)進(jìn)程保持同步。具體來說:
1. 計(jì)算參考曲線
首先,計(jì)算模型在所有樣本上的平均獎勵曲線作為參考:
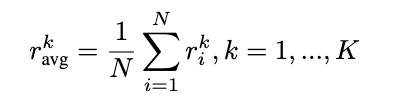
這條曲線反映了模型的整體學(xué)習(xí)軌跡。
2. 評估樣本對齊度
接著,為每個樣本計(jì)算一個歸一化的對齊分?jǐn)?shù):
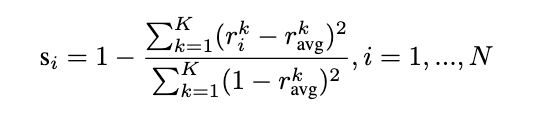
這個分?jǐn)?shù)衡量了樣本的學(xué)習(xí)模式與整體學(xué)習(xí)軌跡的匹配程度。分?jǐn)?shù)越高,表示該樣本越 "有價值"。
3. 篩選高價值樣本
最后,設(shè)定一個質(zhì)量閾值 θ,選取那些對齊分?jǐn)?shù)超過閾值的樣本。在實(shí)驗(yàn)中,設(shè)置 θ = 0.6 篩選出了 1,389 個高價值樣本,構(gòu)成了優(yōu)化后的 LIMR 數(shù)據(jù)集。
對比與驗(yàn)證
為了驗(yàn)證 LIM 方法的有效性,研究團(tuán)隊(duì)設(shè)計(jì)了兩個基線方法:
1. 隨機(jī)采樣(RAND):從原始數(shù)據(jù)集中隨機(jī)選擇 1,389 個樣本
2. 線性進(jìn)度分析(LINEAR):專注于那些顯示穩(wěn)定改進(jìn)的樣本
這些對照實(shí)驗(yàn)幫助我們理解了 LIM 的優(yōu)勢:它不僅能捕獲穩(wěn)定進(jìn)步的樣本,還能識別那些在早期快速提升后趨于穩(wěn)定的有價值樣本。
獎勵設(shè)計(jì)
對于獎勵機(jī)制的設(shè)計(jì),研究團(tuán)隊(duì)借鑒了 Deepseek R1 的經(jīng)驗(yàn),采用了簡單而有效的規(guī)則型獎勵函數(shù):
- 當(dāng)答案完全正確時,給予 + 1 的正向獎勵
- 當(dāng)答案錯誤但格式正確時,給予 - 0.5 的負(fù)向獎勵
- 當(dāng)答案存在格式錯誤時,給予 - 1 的負(fù)向獎勵
這種三級分明的獎勵機(jī)制不僅能準(zhǔn)確反映模型的解題能力,還能引導(dǎo)模型注意答案的規(guī)范性。
三、實(shí)驗(yàn)驗(yàn)證:少即是多的力量
實(shí)驗(yàn)設(shè)置與基準(zhǔn)
研究團(tuán)隊(duì)采用 PPO 算法在 Qwen2.5-Math-7B 基座模型上進(jìn)行了強(qiáng)化學(xué)習(xí)訓(xùn)練,并在多個具有挑戰(zhàn)性的數(shù)學(xué)基準(zhǔn)上進(jìn)行了評估,包括 MATH500、AIME2024 和 AMC2023 等競賽級數(shù)據(jù)集。
主要發(fā)現(xiàn)
實(shí)驗(yàn)結(jié)果令人振奮。使用 LIMR 精選的 1,389 個樣本,模型不僅達(dá)到了使用全量 8,523 個樣本訓(xùn)練的性能,在某些指標(biāo)上甚至取得了更好的表現(xiàn):
- 在 AIME2024 上達(dá)到了 32.5% 的準(zhǔn)確率
- 在 MATH500 上達(dá)到了 78.0% 的準(zhǔn)確率
- 在 AMC2023 上達(dá)到了 63.8% 的準(zhǔn)確率
相比之下,隨機(jī)選擇相同數(shù)量樣本的基線模型(RAND)表現(xiàn)顯著較差,這證實(shí)了 LIM 選擇策略的有效性。

三種數(shù)據(jù)選擇策略的性能對比:LIMR 以更少的數(shù)據(jù)達(dá)到更好的效果
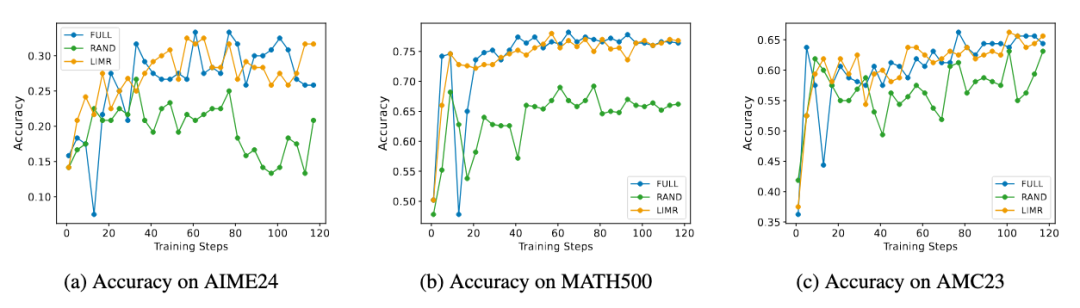
LIMR 在三個數(shù)學(xué)基準(zhǔn)測試上的訓(xùn)練動態(tài)表現(xiàn)與全量數(shù)據(jù)相當(dāng),顯著優(yōu)于隨機(jī)采樣
訓(xùn)練動態(tài)分析
更有趣的是模型在訓(xùn)練過程中表現(xiàn)出的動態(tài)特征。LIMR 不僅在準(zhǔn)確率上表現(xiàn)出色,其訓(xùn)練過程也展現(xiàn)出了更穩(wěn)定的特征:
- 準(zhǔn)確率曲線與使用全量數(shù)據(jù)訓(xùn)練的模型幾乎重合
- 模型生成的序列長度變化更加合理,展現(xiàn)出了更好的學(xué)習(xí)模式
- 訓(xùn)練獎勵增長更快,最終也達(dá)到了更高的水平
這些結(jié)果不僅驗(yàn)證了 LIM 方法的有效性,也表明通過精心選擇的訓(xùn)練樣本,確實(shí)可以實(shí)現(xiàn) "少即是多" 的效果。
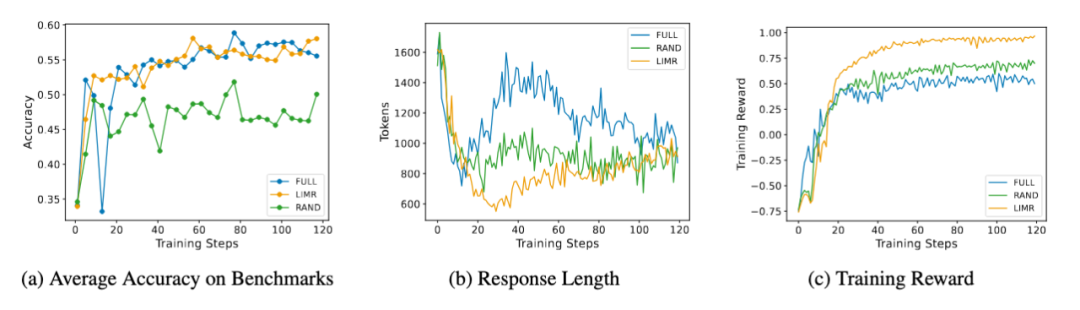
LIMR 的訓(xùn)練動態(tài)分析:從精選樣本中獲得更穩(wěn)定的學(xué)習(xí)效果
四、數(shù)據(jù)稀缺場景下的新發(fā)現(xiàn):RL 優(yōu)于 SFT
在探索高效訓(xùn)練策略的過程中,研究者們發(fā)現(xiàn)了一個令人深思的現(xiàn)象:在數(shù)據(jù)稀缺且模型規(guī)模較小的場景下,強(qiáng)化學(xué)習(xí)的效果顯著優(yōu)于監(jiān)督微調(diào)。
為了驗(yàn)證這一發(fā)現(xiàn),研究者們設(shè)計(jì)了一個精心的對比實(shí)驗(yàn):使用相同規(guī)模的數(shù)據(jù)(來自 s1 的 1000 條數(shù)據(jù)和來自 LIMO 的 817 條數(shù)據(jù)),分別通過監(jiān)督微調(diào)和強(qiáng)化學(xué)習(xí)來訓(xùn)練 Qwen-2.5-Math-7B 模型。結(jié)果令人印象深刻:
- 在 AIME 測試中,LIMR 的表現(xiàn)較傳統(tǒng)監(jiān)督微調(diào)提升超過 100%
- 在 AMC23 和 MATH500 上,準(zhǔn)確率提升均超過 10%
- 這些提升是在使用相近數(shù)量訓(xùn)練樣本的情況下實(shí)現(xiàn)的
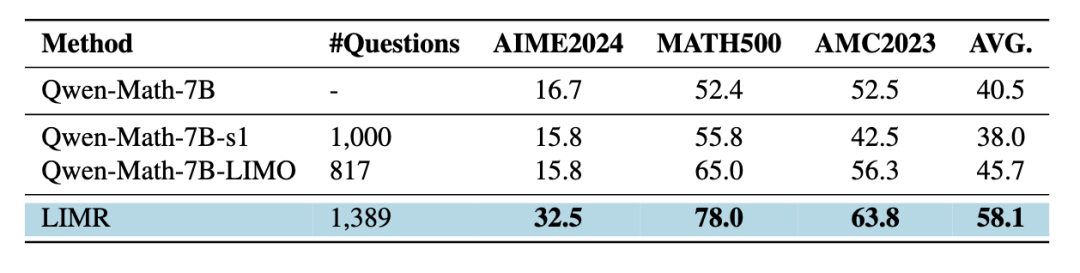
小模型上的策略對比:強(qiáng)化學(xué)習(xí)的 LIMR 優(yōu)于監(jiān)督微調(diào)方法
這一發(fā)現(xiàn)具有重要意義。雖然 LIMO 和 s1 等方法已經(jīng)證明了在 32B 規(guī)模模型上通過監(jiān)督微調(diào)可以實(shí)現(xiàn)高效的推理能力,但研究表明,對于 7B 這樣的小型模型,強(qiáng)化學(xué)習(xí)可能是更優(yōu)的選擇。
這個結(jié)果揭示了一個關(guān)鍵洞見:在資源受限的場景下,選擇合適的訓(xùn)練策略比盲目追求更具挑戰(zhàn)性的數(shù)據(jù)更為重要。通過將強(qiáng)化學(xué)習(xí)與智能的數(shù)據(jù)選擇策略相結(jié)合,研究者們找到了一條提升小型模型性能的有效途徑。