













騰訊優(yōu)圖提出首個基于DiT的高保真虛擬試衣算法FitDiT
今天介紹的文章來自公眾號粉絲投稿,騰訊優(yōu)圖提出首個基于DiT的高保真虛擬試衣算法FitDiT,給定一個人像圖像和一個衣物圖像,就可以生成一個展示人物穿著所提供衣物的圖像。FitDiT 在虛擬試穿中表現(xiàn)出色,解決了各種場景中與紋理感知保存和尺寸感知試穿相關(guān)的挑戰(zhàn)。

1. 引言
基于圖像的虛擬試穿是當前電商場景流行且前景看好的圖像合成技術(shù),能夠顯著改善消費者的購物體驗并降低服裝商家的廣告成本。顧名思義,虛擬換衣任務(wù)的目標是生成穿著給定服裝的目標模特的圖像。但是目前的基于GAN 和 U-Net Diffusion的模型在豐富紋理維持以及服裝尺寸適配方面有所欠缺,其中我們發(fā)現(xiàn)U-Net的擴散結(jié)構(gòu)的對高分辨率潛在特征的關(guān)注較少,會導致紋理維持較差。為了解決這個問題,我們提出了 FitDiT ,是首個基于DiT結(jié)構(gòu)的高保真虛擬換衣工作,通過更加關(guān)注高分辨率特征,克服了當前 U-Net 擴散模型在復雜紋理維護方面的局限性。
對于豐富的紋理感知維護,我們提出了一種服裝先驗進化策略,以更好地精確掌握服裝的圖案知識,并在像素空間中采用頻譜距離損失來保留復雜的圖案。此外,對于尺寸感知試穿,我們提出了一種擴張松弛掩模增強方法,使用粗矩形掩模來降低服裝形狀的泄漏,并使模型能夠自適應(yīng)地學習服裝的整體形狀。大量的定性和定量實驗有力地證明了 FitDiT 優(yōu)于最先進的虛擬試穿模型,特別是在處理尺寸不匹配的紋理豐富的服裝方面。此外,它對單個 1024 × 768 圖像的推理時間達到了 4.57 秒,超越了現(xiàn)有方法。這些發(fā)現(xiàn)是推動虛擬試穿領(lǐng)域發(fā)展的重要里程碑,使現(xiàn)實世界中更復雜的應(yīng)用成為可能。
FitDiT方案相比現(xiàn)有的開源算法有以下優(yōu)勢:
- 1. 更清晰的紋理信息
- 2. 更好的衣服版型維持能力 3.更少的推理耗時
相關(guān)鏈接
- ? 論文地址:https://arxiv.org/pdf/2411.10499
- ? 項目主頁:https://byjiang.com/FitDiT/
- ? 代碼倉庫:https://github.com/BoyuanJiang/FitDiT
- ? 體驗地址:http://demo.fitdit.byjiang.com/
2. 效果展示

圖 1. FitDiT 在虛擬試穿中表現(xiàn)出色,解決了各種場景中與紋理感知保存和尺寸感知試穿相關(guān)的挑戰(zhàn)。

圖 2. 具有復雜服裝紋理、CVDD 視覺效果。放大后效果最佳。
3. 方法介紹
3.1 模型概述
FitDiT的目標是給定一個人像圖像和一個衣物圖像,生成一個展示人物穿著所提供衣物的圖像。這一過程可以被視為一個基于示例的圖像修復任務(wù),涉及使用衣物 作為參考來填充被掩碼的人像圖像。FitDiT采用并行分支架構(gòu),其中GarmentDiT從輸入的衣物圖像中提取詳細的衣物特征,然后通過混合注意力機制將這些特征注入到DenoisingDiT中。
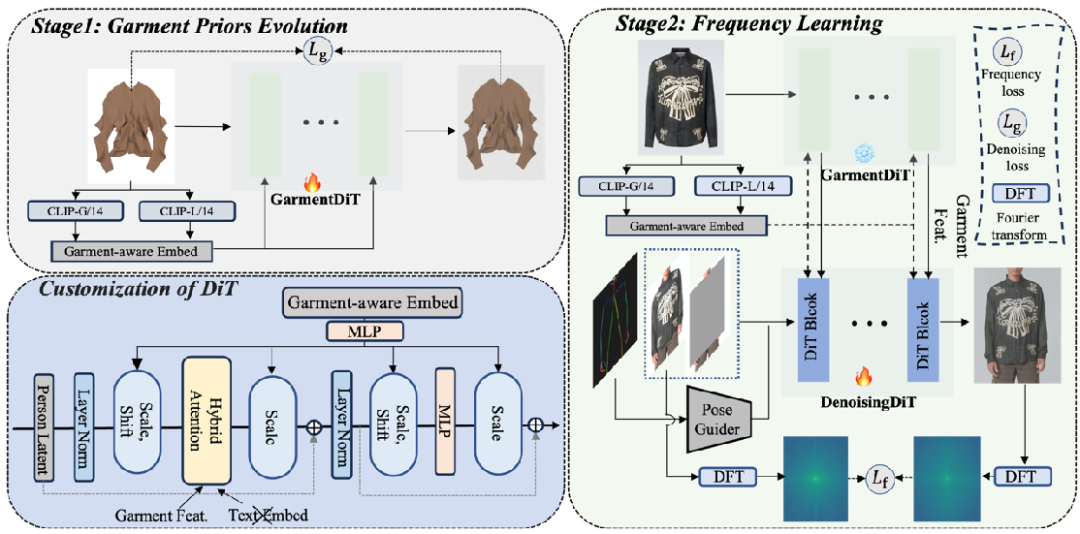
3.2 DiT的定制化
原始的穩(wěn)定擴散模型(SD3)是一個文本到圖像的模型,由一系列堆疊的MM-DiT塊組成。我們分析了文本到圖像和虛擬試衣任務(wù)之間的差異,并為虛擬試衣特別定制了模型。
- ? 結(jié)構(gòu)精簡:原始SD3使用OpenCLIP bigG/14, CLIP-ViT/L和T5-xxl作為文本編碼器來處理文本提示,但對于虛擬試衣,生成的圖像主要由給定的衣服決定,文本提示的影響有限。因此,我們移除了SD3中的文本編碼器,節(jié)省了約72%的參數(shù),同時提高了模型訓練和推理的速度,并減少了內(nèi)存使用。
- ? 將服裝作為全局控制條件:在虛擬試衣任務(wù)中,不同類型的衣物(如上身、下身、連衣裙)通常使用統(tǒng)一的模型進行訓練,這可能會導致訓練過程中的混淆。我們提出使用OpenCLIP bigG/14,和CLIP-ViT/L的圖像編碼器將給定的衣物編碼成garment-aware embedding,然后與時間步embedding結(jié)合,產(chǎn)生DiT模塊中AdaLN的控制參數(shù),以衣物感知的方式調(diào)制DiT塊中的特征。
- ? 衣物特征注入:為了提取衣物特征,我們首先將衣物輸入到GarmentDiT中,并在時間步 t=0 時保存GarmentDiT注意力模塊中的key和value的特征,這些特征包含了豐富的衣物紋理信息。然后在每個去噪步驟中,我們使用混合注意力機制將保存的衣物特征注入到DenoisingDiT中。
3.3 擴張放松掩碼策略
傳統(tǒng)的跨類別試衣方法通常會遇到形狀渲染不準確的問題,因為它們通常基于人體解析輪廓嚴格構(gòu)建mask。這種掩碼構(gòu)建策略可能導致訓練過程中衣物形狀信息的泄露,導致模型在推理時傾向于填充整個掩碼區(qū)域。為了緩解這個問題,我們提出了一種擴張放松掩碼策略,允許模型在訓練期間自動學習目標衣物的最優(yōu)長度。
3.4 衣物紋理增強
為了在試衣過程中保持豐富的紋理,我們提出了一個兩階段訓練策略。首先,我們通過衣物先驗演化階段來微調(diào)GarmentDiT,使其能夠更好的捕捉衣服的細節(jié)信息。其次是DenoisingDiT訓練,它結(jié)合了頻率損失和去噪損失。
- ? 衣物先驗演化:衣物特征提取器在試衣任務(wù)中保持紋理細節(jié)方面起著至關(guān)重要的作用。我們提出了一個簡單而有效的衣物先驗演化策略來增強我們的GarmentDiT。
- ? 頻率學習:我們提出了像素空間中的頻率譜距離損失,使模型在優(yōu)化過程中更多地關(guān)注頻率域中存在顯著差距的部分。
4. 實驗結(jié)果
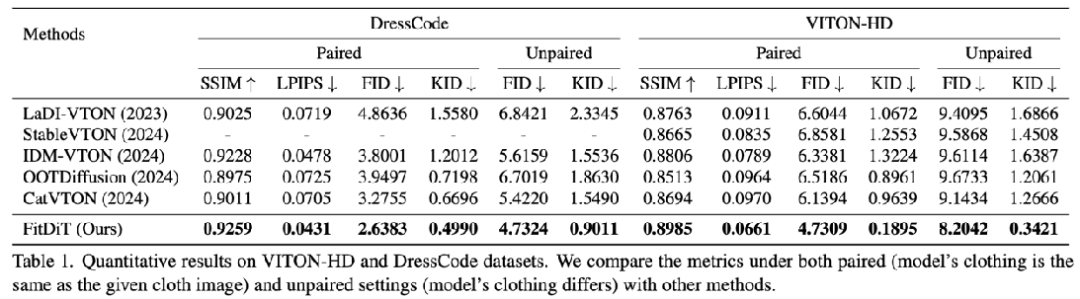
在開源數(shù)據(jù)集上的對比
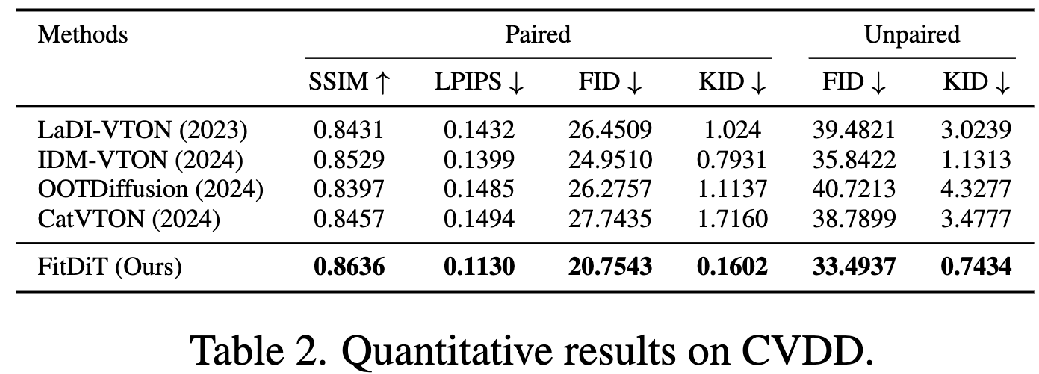
在我們提出的復雜換衣數(shù)據(jù)集(CVDD)上的對比

不同算法的性能對比,統(tǒng)一使用H20測試,分辨率為768x1024,20步去噪。結(jié)合CPU offload技術(shù),F(xiàn)itDiT推理需要的顯存可以進一步降低到6G。



























