













一次推理解決復合問題:基于MoE的大語言模型知識模塊可擴展融合推理架構MeteoRA
本文來自南京大學計算機學院軟件研究所徐經緯DeepEngine團隊,作者為徐經緯準聘助理教授、碩士生賴俊宇和黃云鵬。目前該論文已被 ICLR2025 接收。
在大語言模型領域中,預訓練 + 微調范式已經成為了部署各類下游應用的重要基礎。在該框架下,通過使用搭低秩自適應(LoRA)方法的大模型參數高效微調(PEFT)技術,已經產生了大量針對特定任務、可重用的 LoRA 適配器。但使用 LoRA 適配器的微調方法需要明確的意圖選擇,因此在搭載多個 LoRA 適配器的單一大語言模型上,自主任務感知和切換方面一直存在挑戰。
為此,團隊提出了一個可擴展、高效的多任務嵌入架構 MeteoRA。該框架通過全模式混合專家模型(MoE)將多個特定任務的 LoRA 適配器重用到了基礎模型上。該框架還包括了一個新穎的混合專家模型前向加速策略,以改善傳統實現的效率瓶頸。配備了 MeteoRA 框架的大語言模型在處理復合問題時取得了卓越的性能,可以在一次推理中高效地解決十個按次序輸入的不同問題,證明了該模型具備適配器及時切換的強化能力。

- 論文標題:MeteoRA: Multiple-tasks Embedded LoRA for Large Language Models
- 論文地址:https://arxiv.org/abs/2405.13053
- 項目主頁:https://github.com/NJUDeepEngine/meteora
該工作的創新點主要有以下部分:
- 可擴展的 LoRA 集成框架:MeteoRA 框架能夠整合現有的 LoRA 適配器,并提供了大語言模型自主按需選擇和切換不同 LoRA 的能力。
- 混合專家模型的前向加速策略:揭示了混合專家模型的效率問題,使用新的 GPU 內核操作實現了前向傳播加速策略,在保持內存開銷不變的同時實現了平均約 4 倍的加速。
- 卓越的模型性能:評估表明使用 MeteoRA 框架的大語言模型在復合任務中表現出了卓越的性能,因而增強了大語言模型在結合使用現成 LoRA 適配器上的實際效果。
相關工作
低秩適應 (LoRA):低秩適應 [1] 提供了一種策略來減少下游任務微調所需要的可訓練參數規模。對于一個基于 Transformer 的大語言模型,LoRA 會向每一個基本線性層的權重矩陣注入兩個可訓練的低秩矩陣,并用兩個低秩矩陣的相乘來代表模型在原來權重矩陣上的微調。LoRA 可以用于 Transformer 中自注意力模塊和多層感知機模塊的 7 種權重矩陣,有效縮減了微調權重的規模。應用低秩適應技術可以在不改變預訓練模型參數的前提下,使用自回歸語言模型的優化目標來訓練 LoRA 適配器的參數。
多任務 LoRA 融合:LoRA 適配器通常被微調來完成特定的下游任務。為了增強大語言模型處理多種任務的能力,主流的做法有兩種。一種方法是從多種任務中合并數據集,在此基礎上訓練單一的 LoRA 適配器,但相關研究已經證明同時學習不同領域的知識很困難。[2] 另一種方法是直接將多種 LoRA 適配器整合到一個模型中,如 PEFT [3]、S-LoRA [4]。但是流行的框架必須要明確指定注入的 LoRA 適配器,因此模型缺乏自主選擇和及時切換 LoRA 的能力。現有的工作如 LoRAHub [5] 可以在不人為指定的情況下完成 LoRA 適配器的選擇,但仍舊需要針對每一個下游任務進行少量的學習。
混合專家模型(MoE):混合專家模型是一種通過組合多個模型的預測結果來提高效率和性能的機器學習范式,該范式通過門控網絡將輸入動態分配給最相關的 “專家” 來獲得預測結果。[6] 該模型利用來自不同專家的特定知識來改善在多樣、復雜的問題上的總體表現,已有研究證明 MoE 在大規模神經網絡上的有效性 [7]。對于每個輸入,MoE 只會激活一部分專家,從而在不損害模型規模的基礎上顯著提高計算效率。該方法已被證實在擴展基于 Transformer 的應用架構上十分有效,如 Mixtral [8]。
方法描述
該工作提出了一個可擴展、高效的多任務嵌入架構 MeteoRA,它能夠直接使用開源社區中或面向特定下游任務微調好的 LoRA 適配器,并依據輸入自主選擇、及時切換合適的 LoRA 適配器。如圖 1 所示,MeteoRA 模塊可以被集成到注意力模塊和多層感知機模塊的所有基本線性層中,每一個模塊都包括了一系列低秩矩陣。通過 MoE 前向加速策略,大語言模型能夠高效解決廣泛的問題。

圖 1:集成了 MeteoRA 模塊實現 MoE 架構的大語言模型框架
圖 2 展示了 MeteoRA 模塊的內部結構。MeteoRA 模塊中嵌入了多個 LoRA 適配器,并通過一個門控網絡來實現 MoE 架構。該門控網絡會依據輸入選擇 top-k 個 LoRA 適配器,并將它們組合作為微調權重進行前向傳播。通過這種架構,門控網絡會執行路由策略,從而根據輸入選取合適的 LoRA 適配器。每一個 MeteoRA 模塊都包含一個獨立的門控網絡,不同門控網絡依據它們的輸入獨立決策,并在全部解碼器模塊的前向傳播過程中動態選取不同 LoRA 適配器。
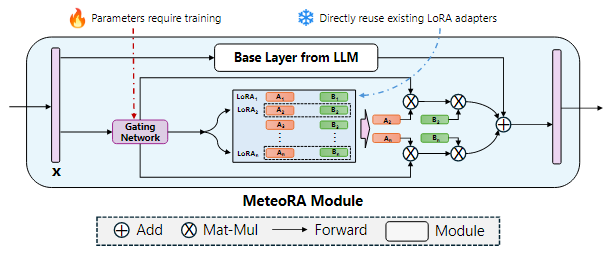
圖 2:應用 MoE 模型集成 LoRA 嵌入的 MeteoRA 模塊的架構
MeteoRA 模塊的訓練遵循自回歸語言建模任務下的模型微調準則,訓練中需要保持基本的大語言模型權重和預訓練的 LoRA 適配器參數不變。由于 MeteoRA 模塊支持選擇權重最高的若干個 LoRA 適配器,團隊引入了一種將自回歸語言建模損失和所有門控網絡損失組合起來的聯合優化方案。該優化函數綜合了自回歸模型中的預測損失和 MeteoRA 模塊中 LoRA 分類的交叉熵損失,實現門控網絡的訓練。
MeteoRA 模塊的核心組件是整合了多個 LoRA 適配器的 MoE 架構。首先,團隊將 LoRA 整合成在 HBM 上連續分配的張量。對于每個批次的輸入序列中的每個標記,由于該模塊需要利用門控網絡找到 LoRA 適配器的編號索引集合,MeteoRA 模塊幾乎不可能與單獨的 LoRA 模塊保持相同的效率。基于原始循環(loop-original)的簡單實現 [8] 采用 for-loop 遍歷 LoRA 適配器,在每次遍歷中對該適配器的候選集合應用 LoRA 前向傳遞。該方法簡單地將所有批次的所有標記拆成 LoRA 數量個集合,并且使得每個集合按順序傳遞。然而,考慮到輸入標記相互獨立的性質,這種方法無法充分利用并行化 GEMM 算子 [9] 加速,尤其是當某些 LoRA 適配器僅被少數標記選擇,或是待推理標記小于 LoRA 數量時,實驗中可能花費最多 10 倍的運行時間。
該工作采用了前向傳播加速策略 bmm-torch,直接索引全部批次標記的 top-k 適配器,這會利用到兩次 bmm 計算。相比于原始的循環方法,bmm-torch 基于 PyTorch 提供的 bmm 操作符 [10] 并行化所有批次標記的 top-k 個適配器,實現了約 4 倍的加速。在實驗中該策略僅比它的上限單 LoRA 模塊慢 2.5 倍。由于 PyTorch 的索引約束(indexing constraints)[11],bmm-torch 需要分配更大的內存執行批處理,當批次或者輸入長度過大時 bmm-torch 的大內存開銷可能成為瓶頸。為此,該工作使用了 Triton [12] 開發了自定義 GPU 內核算子,不僅保持了 bmm-torch 約 80% 的運算效率,而且還保持了原始循環級別的低內存開銷。
實驗結果
該工作在獨立任務和復合任務上,對所提出的架構和設計進行了廣泛的實驗驗證。實驗使用了兩種知名的大語言模型 LlaMA2-13B 和 LlaMA3-8B,圖 3 顯示了集成 28 項任務的 MeteoRA 模塊與單 LoRA、參考模型 PEFT 在各項獨立任務上的預測表現雷達圖。評估結果表明,無論使用哪種大語言模型,MeteoRA 模型都具備與 PEFT 相近的性能,而 MeteoRA 不需要顯式地激活特定的 LoRA。表 1 展示了所有方法在各項任務上的平均分數。
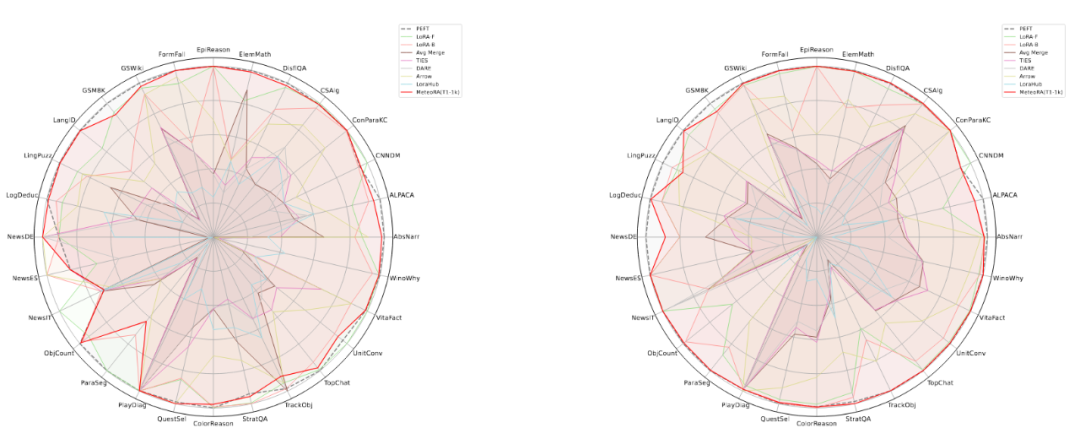
圖 3:MeteoRA 模型在 28 項選定任務上的評估表現
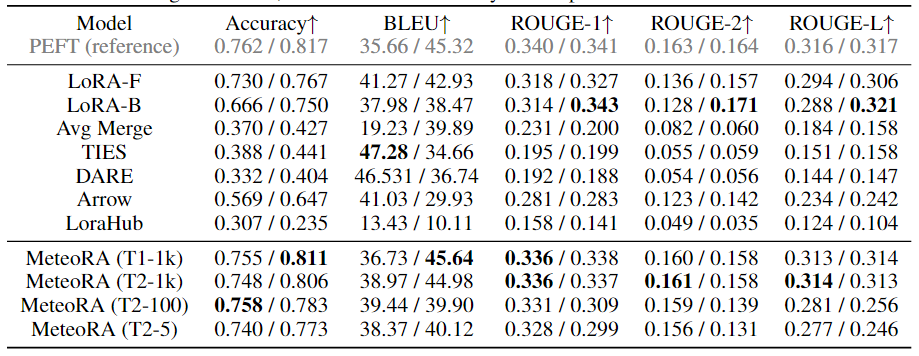
表 1:各模型在 28 項選定任務上的平均表現
為了驗證該模型按順序解決復合問題的能力,該工作通過串行連接獨立的任務來構建 3 個數據集,分別整合了 3、5、10 項任務,期望模型能夠按次序解決同一序列中輸入的不同類別問題。實驗結果如表 2 所示,可見隨著復合任務數的提升,MeteoRA 模塊幾乎全面優于參考 LoRA-B 模型。
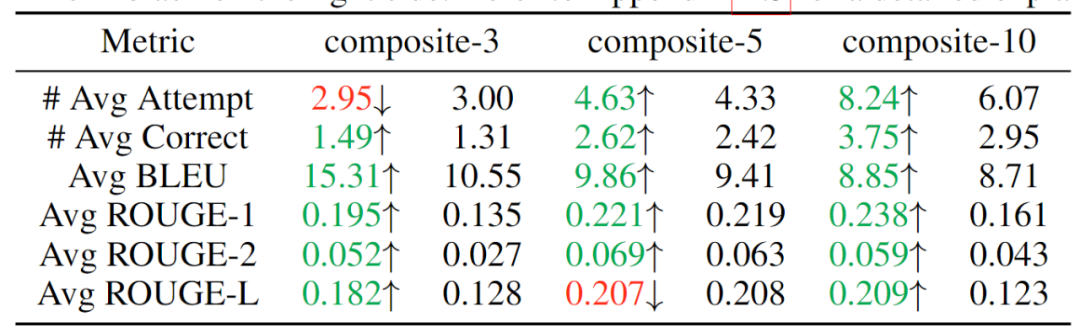
表 2:復合任務的評估結果,左側為 MeteoRA 模塊,右側為 LoRA-B
為了更進一步驗證門控網絡在 MeteoRA 模塊中的功能,該工作展示了在復合任務推理過程中采用 top-2 策略的 LoRA 選擇模式。在兩個相鄰任務的連接處,門控網絡正確執行了 LoRA 的切換操作。

圖 4:在 3 項任務復合中 LoRA 選取情況的例子
為了驗證采用自定義 GPU 算子的前向傳播設計的運算效率,該工作在 28 項任務上截取了部分樣本,將新的前向傳播策略與其上限和原始實現對比。評估結果如圖 5 所示,展現了新的加速策略卓越的性能。

圖 5:四種不同的前向傳播策略在 28 項任務上的整體運行時間




























