再來談談大模型的分離式推理架構
1. 推理系統(tǒng)和訓練系統(tǒng)的區(qū)別
最簡單的一句話是: 推理系統(tǒng)沒有所謂的DP并行. 背后隱藏的一個含義是兩個系統(tǒng)的Workload是完全不一樣的.
1.1 訓練系統(tǒng)
到達速率和服務速率為確定性分布。
在訓練系統(tǒng)中數(shù)據(jù)以Batch的方式到達, 然后計算時間也相對確定, 一方面是因為backward過程的同步需求, 另一方面是訓練語料本身有長短的分布但也做了Padding, 當然可以通過一些技術對Padding進行優(yōu)化提升計算效率。
1.2 推理系統(tǒng)
到達速率假設為泊松分布, 服務速率受實現(xiàn)方式和服務策略影響。
推薦系統(tǒng)請求到達的分布假設是一個泊松分布, 另一方面input token和output token的分布則會帶來服務時間有一個特定的分布, 簡單的來看按泊松分布算, 或者有長尾的情況,例如Pareto分布.而Prefill-Decoder的方式也會影響這個分布, 因此在調(diào)度系統(tǒng)上該如何考慮是一個更值得深思的問題. 這些問題也是最近一段時間工作的一個方向。
1.3 推理系統(tǒng)SLO
對于不同的用戶而言(例如按照充值程度分金/銀/銅)SLO是不同的, 針對不同的SLO下的TTFT/TBT的整個推理系統(tǒng)的優(yōu)先級調(diào)度和延遲隱藏也有很多可以去做的事情. 另一個非常重要的工作是對用戶請求的服務時間的預測。
推理系統(tǒng)的請求和服務時間分布相對于訓練系統(tǒng)更加有不確定性, 因此在各個子系統(tǒng)內(nèi)的調(diào)度編排和Locality的利用上以及時間/空間折中處理上有著巨大的創(chuàng)新空間.其實這也是Prefill-Decode/KV-Cache Centric Sched有收益的本質(zhì)原因。
接下來我們分別從軟件系統(tǒng)和硬件系統(tǒng)來談談。
2. 軟件架構
從軟件架構來看, 數(shù)據(jù)和控制平面的分離是一個非常經(jīng)典的設計模式。
2.1 控制面
控制平面主要負責一些用戶請求服務時間預測/調(diào)度/集群管理和高可靠/Cache及相關的分離式內(nèi)存池管理的任務, 這些任務從架構上來看應該用通用的CPU進行處理。
2.2 數(shù)據(jù)面
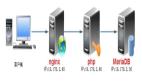
數(shù)據(jù)面主要是用于計算的Prefill Node和Decode Node以及一些彈性內(nèi)存池相關的數(shù)據(jù)搬移的工作. 從數(shù)據(jù)面來看, 其緩存結構在推薦系統(tǒng)中已經(jīng)有很好的借鑒, 那就是HugeCTR一類的框架中的Hierarchical Parameter Server。
 圖片
圖片
從Embedding Cache變成了需要在LLM處理KVCache, 但是相應的軟件棧和結構還是有區(qū)別的. Embedding TableLookup更多的是Hash Lookup ExatclyMatch. 而在LLM中KVCache的處理是一個Longest Prefix Match. 因此CPU Memory和SSD的軟件架構還需要一些調(diào)整。
2.3 存儲設計和內(nèi)存緩沖池
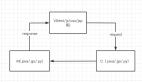
當然系統(tǒng)也會面臨DRAM不夠的問題需要落盤. 然后既要SSD容量大又要高I/O,同時還要考慮低成本和可運維. 因此在SSD前面構建一個分布式的彈性內(nèi)存池應該是必須要做的了, 這里有一篇華為《MemServe: Context Caching for Disaggregated LLM Serving with Elastic Memory Pool》[2]。
 圖片
圖片
另一個業(yè)務場景是DeepSeek會將用戶的上下文落盤到SSD中并保存24小時. 那么相應的軟件架構應該就很好構建了。
我們可以通過Trie樹或者TreeBitMap的算法來構建整個查詢樹。
當訪問到一個葉子后, 即記錄該葉子對應的KVCache所在的內(nèi)存的節(jié)點ID和指針并放入處理List, 以便以后進行異步的DMA/RDMA. 這些在用戶請求到達后即可進行異步執(zhí)行處理并在隊列適當?shù)臅r候由調(diào)度器控制執(zhí)行相應Prefill Node GPU VRAM的Prefetch。
Trie樹也可以根據(jù)input token做一些并行化的處理方式, 例如通過一致性Hash針對前幾個Token將workload分散到不同的CPU服務器上. 而這些服務器又可以構建成一個很大規(guī)模的彈性內(nèi)存池。
對于彈性內(nèi)存層的Cache Evict可以按照LRU的方式進行, 落盤的時候還需要考慮一些KVCache生命周期的問題. 落盤后也需要對Trie樹進行更新將其相應的葉子節(jié)點指針更新到指向某個文件的特定的塊。
談到落盤,可以借鑒類似于LSM的方式合并壓縮后落入磁盤, 并且還可以根據(jù)實際情況進行冷溫熱分層. 因此對于存儲落盤到SSD的場景, 個人并不是很喜歡在GPU實例上的本地SSD, 損壞后維修帶來的業(yè)務影響還是有的, 另一方面可能還會帶來一些workload偏斜的影響, 因此可能更傾向于一種分布式并行存儲的方式。
當然這里還有一個不同的地方是對于長時間沒有更新的block也需要定期的進行GC, 例如按照DeepSeek保留24h的做法, 可以對超過24h的數(shù)據(jù)刪除并在Trie樹上剪枝更新。
3. 硬件架構
3.1三網(wǎng)融合的推理系統(tǒng)
黃大年茶思屋最近也有一篇《英偉達、谷歌、Meta等5大巨頭Scale-up超節(jié)點規(guī)模大比拼,揭示未來AI網(wǎng)絡最優(yōu)解》[3]. 個人對這種不根據(jù)workload來談互聯(lián)的分析持懷疑態(tài)度, 但是有些結論是正確的. 其中最重要的一點就是“三網(wǎng)合一”即文章中的觀點。
當前的AI網(wǎng)絡是三個獨立網(wǎng):前端存儲網(wǎng)VPC(以太)、后端參數(shù)面(IB、RoCE2)和超節(jié)點(NVLink,HCCS)。三個網(wǎng)長期共存不合理的,一定會融合。
當然這個問題在方博士的文章中也有提及:
現(xiàn)在分離式架構都是用GPU訓練集群做推理,節(jié)點內(nèi)NVLink互聯(lián),節(jié)點間用IB或ROCE的RDMA互聯(lián)。這種配置分離式架構完全是浪費,好比李云龍攻打平安縣城,章明星稱之為富裕仗。
有幾個難題:
3.2 FrontEnd: CPU實例和GPU實例耦合
在這樣的一個推理系統(tǒng)中, NVL72-GB200是一個非常不錯的方案, ScaleUP規(guī)模大, 而CPU又直接和GPU有C2C的帶寬, 這樣控制面和彈性內(nèi)存池的設計難度會小不少.另一個問題是泊松分布到達下GPU的調(diào)度的問題,這個涉及一些GPU本身SIMT硬件架構的缺陷, 就不展開了。
而對于國內(nèi)非Grace-B/H的大概只能通過RDMA將彈性內(nèi)存池和GPU連接了, 因此需要VPC上跑超大規(guī)模RDMA并且完全商用的, 現(xiàn)階段全球能做的大概也就只有AWS SRD/Google Falcon和阿里云eRDMA. 而同時在這個網(wǎng)絡上又要兼顧Prefill Node之間的SP并行帶來的alltoall incast的影響, 對于其它很多客戶而言, 包括英偉達自己都是有很大挑戰(zhàn)的。
為什么需要呢, 從另一個角度來看,現(xiàn)在的Prefill/Decoder的轉移其實都是在8卡PCIe連接的同服務器的CPU上,然后再通過Messenger轉發(fā)到另一個Decoder實例, 并通過Async Load加載. 也就是說CPU的算力和內(nèi)存空間和GPU是綁定的, 外置的CPU服務器如果可以直接GDR訪問GPU顯存來做異步的調(diào)度和prefix lookup整個的性價比還應該有所提升。
 圖片
圖片
我們注意到Google Vertex AI很早就通過一些閑置的CPU實例和GPU混布來構建, 并且通過CPU實例來做參數(shù)服務器,當然還有一個是Cerebas的Swarm-X/Memory-X架構。
 圖片
圖片
另外Enfabrica也有一些機會,難怪NV也投資了。
3.3 ScaleOut: Prefill-Decode M:N的部署
即章明星老師提到的異構分離式架構, 需要在H800/A800和H20之間構建很高的Bi-Section帶寬, 同時考慮到組網(wǎng)規(guī)模的問題還需要避免網(wǎng)絡上hash沖突帶來的利用率降低的問題。
3.4 ScaleUP: 是否還需要Load/Store ?
針對推理系統(tǒng)來看, ScaleUP主要用于TP/SP并行,例如模型規(guī)模大了或者算力無法滿足SLO時或負載均衡的考慮帶來的并行策略. 細粒度的Load/Store訪存似乎并不需要,因此Eth-X這樣的方案或許也就夠用了.當然還有一些優(yōu)化方式,例如英偉達的GPS/PROACT/Fine-PACK的處理方式等. 當然另一方面有現(xiàn)成的NVLink用用也挺好的. 等待UALink似乎又要考慮一些問題, 例如BRCM Altas4的single vendor供應的問題和InfityFabric這些IP的成熟度, 當前的國產(chǎn)GPU廠商可能面臨二選一的決策, 但是還是請先考慮是否還需要Load/Store over Scale-UP Link。
這個問題的答案取決于業(yè)務部署模式的考慮,成本的衡量,彈性的重要程度,是否訓推一體,生態(tài)的兼容程度等. 未來多模態(tài)的業(yè)務場景也是一個變數(shù)。
3.5 彈性和成本視角
方博士也提到了一個問題Prefill和Decode Instance彈性擴縮容。
因為Prefill和Decode各自子集群網(wǎng)絡互聯(lián)可以用以太網(wǎng),沒準也可以根據(jù)負載彈性擴容Memory Pool和計算設備和存儲。
其實最終都是在成本上打算盤, 以后的服務就是按照Token印錢, 印刷機的成本, 推理流量的峰谷帶來的彈性供給, 都是值得考慮的問題。
當然具體的方案就不展開寫了...幾年前就探索過的工作。
 圖片
圖片
本質(zhì)的難題當時也講清楚了,內(nèi)存的兩個墻。
 圖片
圖片
這樣不就好了?
 圖片
圖片
當然還有一些隨路計算的東西,BRCM INCA/ NV SHARP也行, 網(wǎng)卡做Reduction/all-gather也行, 都是幾年前全做好的
 圖片
圖片
參考資料
[1]LLM分離式推理可能帶來的軟硬件變革的迷思: https://zhuanlan.zhihu.com/p/707199343
[2]MemServe: Context Caching for Disaggregated LLM Serving with Elastic Memory Pool: https://arxiv.org/abs/2406.17565
[3]英偉達、谷歌、Meta等5大巨頭Scale-up超節(jié)點規(guī)模大比拼,揭示未來AI網(wǎng)絡最優(yōu)解: https://mp.weixin.qq.com/s/5Oq6H1VBd3G2CTGwXtjq8A