













如何讓大模型感知知識圖譜知識?螞蟻聯合實驗室:利用多詞元并行預測給它“上課”
如何讓大模型感知知識圖譜知識?
螞蟻聯合實驗室:利用多詞元并行預測給它“上課”。
大語言模型的飛速發展打破了許多自然語言處理任務間的壁壘。通常情況下,大語言模型以預測下一個詞元(Token)為訓練目標,這與許多自然語言處理任務十分契合。
但對于知識圖譜而言,實體作為最基本的數據單元,往往需要多個自然語言詞元才能準確描述,這導致知識圖譜與自然語言之間存在明顯的粒度不匹配。
為了解決這一問題,螞蟻團隊提出了一種基于大語言模型的多詞元并行預測方法K-ON,其利用多詞元并行預測機制能夠一次生成對所有實體的評估結果,進而實現語言模型實體層級的對比學習。

其結果收錄于AAAI 2025 Oral。論文一作目前在浙江大學攻讀博士。
實驗結果表明,本文方法在多個數據集上的知識圖譜補全任務中均優于現有方法。
基于多詞元并行預測的實體對比學習
詞元是語言模型所能處理的最基本元素,通常需要數個詞元組成的文本標簽才能準確描述和鑒別知識圖譜中的實體。雖然為每個實體創建一個新的詞元并在微調過程中學習這些詞元的表示不失為一種替代方案,但這種方式訓練調優成本較高,且可能會對大模型的性能產生負面影響,通用性也受到限制。
本文探討了如何高效利用多個詞元描述知識圖譜中的實體以解決知識圖譜相關問題的方法。首先,直接優化經典的序列預測損失可能會導致大模型缺乏對知識圖譜實體的認識,從而出現生成知識圖譜中不存在的實體的問題;且考慮到知識圖譜中實體的數量,將所有實體以文本上下文的方式輸入給大模型顯然也是不現實的。
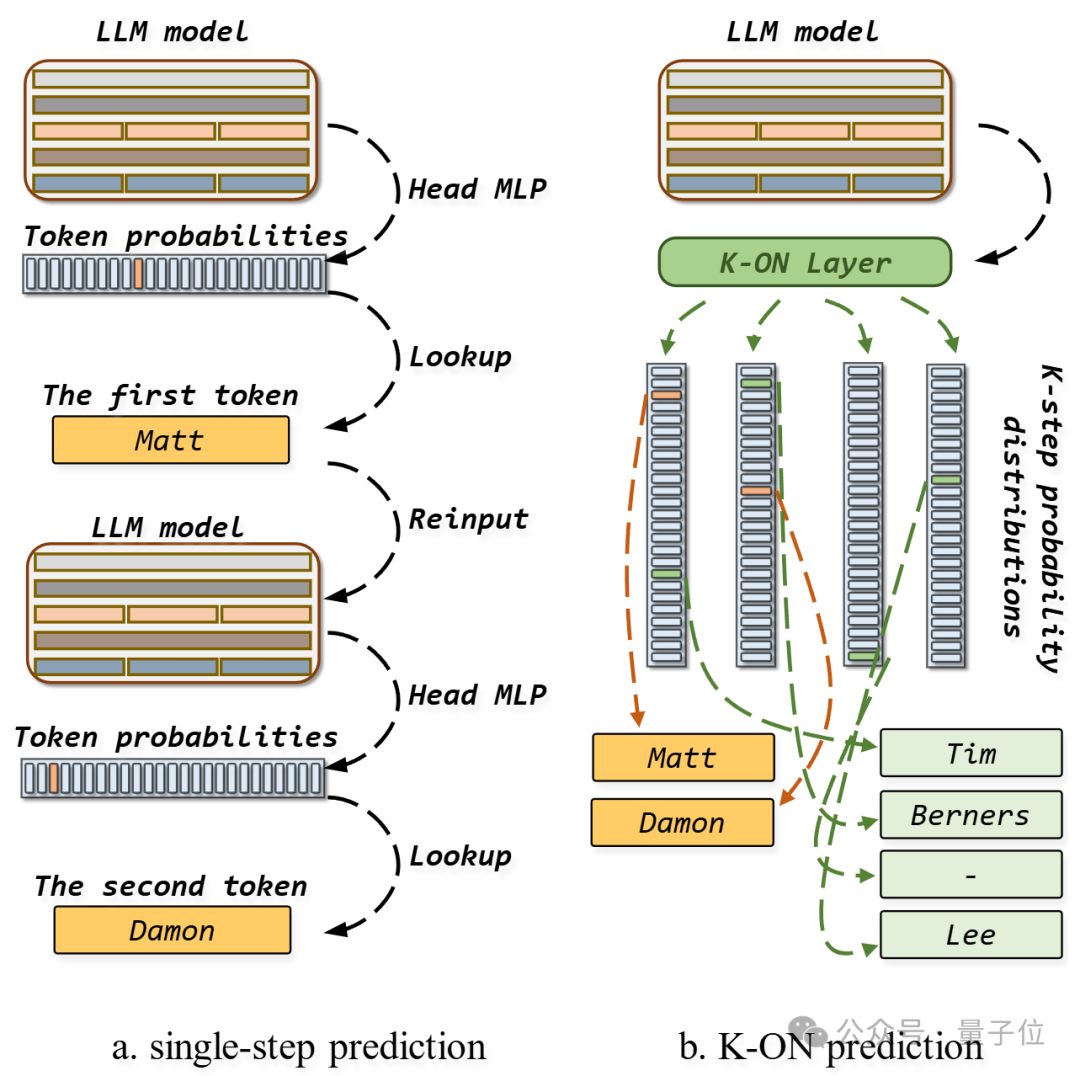
以上圖為例,假設任務是給定不完整三元組以預測目標實體Matt Damon。左圖中使用常規連續單詞元預測方式生成結果需要多個子步驟,且無法直接處理多個實體。因此,現有大多數知識圖譜相關方法僅將大模型應用于簡單任務上,如驗證三元組的正確性或從有限數量的候選實體中選擇正確答案。
相比之下,本文提出的K-ON方法使用K個輸出層并行預測多個實體不同位置詞元的概率,這與目前DeepSeek等大模型中使用的多詞元預測技術有著一定的相似性,且本文方法進一步借助了實體層級的對比學習在模型輸出層上累加知識圖譜知識。
K-ON完成知識圖譜補全任務的方法論
如下圖所示,K-ON并行評估知識圖譜候選實體分數的過程可分為五步:
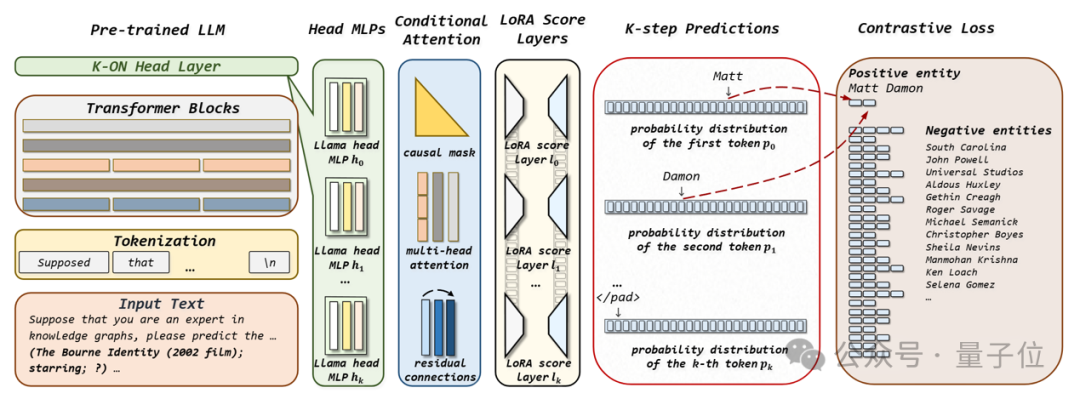
(1)與現有微調大模型的方法相似,K-ON將知識圖譜補全問題以文本指令的方式輸入大模型;
(2) 經大模型Transformer模塊處理后的輸出狀態被輸入至K-ON模塊中,該模塊由多個原大模型輸出層MLP構成,對應為要預測實體的不同位置的詞元;
(3) 接著,K-ON使用Conditional Transformer混合不同位置的信息,并考慮到詞元前后的順序依賴性;
(4) 然后,使用低秩適應技術(LoRA)將原大模型評分層構造為K個新的評分層,從而把上一步的輸出結果轉換為對實體K個連續詞元的概率預測分布;
(5) 最后便可以從不同位置的概率預測分布中抽取各實體詞元對應的概率值,進而一次評估所有候選實體的分數。
在獲取候選實體分數后,便可使用知識圖譜表示學習領域中最為常用的對比學習損失使大模型掌握知識圖譜中實體的分布:
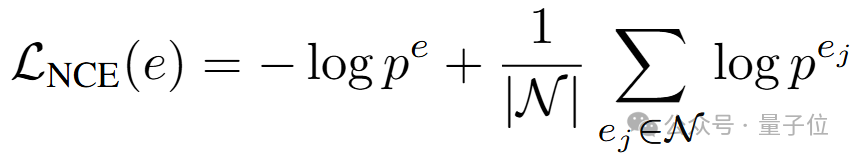
此處 pe、 pej分別代表正樣本和負樣本的分數,均由K-ON模塊并行生成。除了實體層級的對比學習外,本文還進一步考慮使用詞元序列對齊使多詞元并行預測的結果與原本大模型單步連續預測的結果相接近。為實現這一目標,本文首先引入常用的單步預測損失以在訓練語料上微調原輸出層參數:
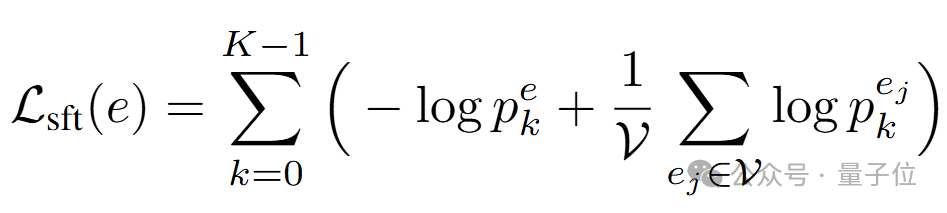
這里的下標k指代組成實體的詞元的序號。
接著便可令K-ON模塊中一次評估的K個詞元的概率分布與常規連續單詞元預測得到的K個概率分布對齊:
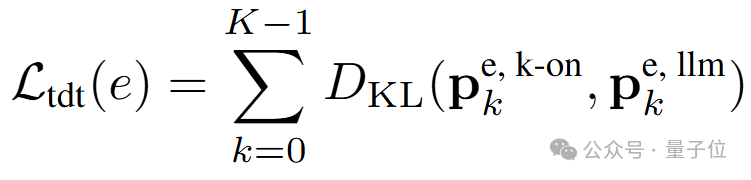
此處上標 k-on、llm 分別指代K-ON和常規連續預測所得到的分數。
最后,訓練K-ON完成知識圖譜補全任務的基本流程可總結如下:

實驗結果:效率更高、成本更低、效果更好
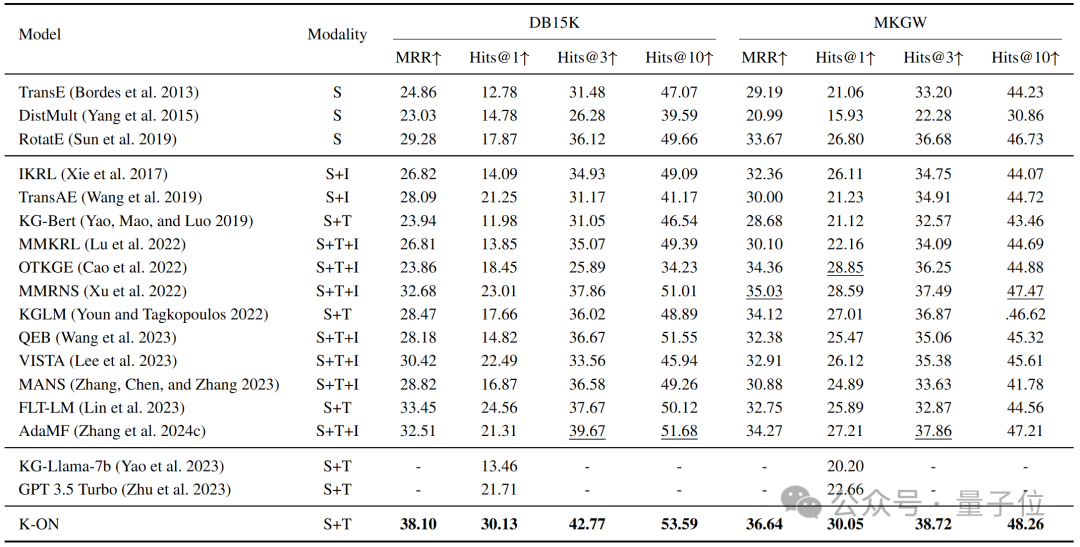
下表展示K-ON在知識圖譜補全任務上的實驗結果,除傳統方法外,本文還與同樣基于大模型的方法以及多模態方法進行了比較。不難看出,K-ON在所有數據集及指標上均取得了優于現有方法的結果,且與一些使用額外圖像數據的方法相比,仍具有一定優勢。
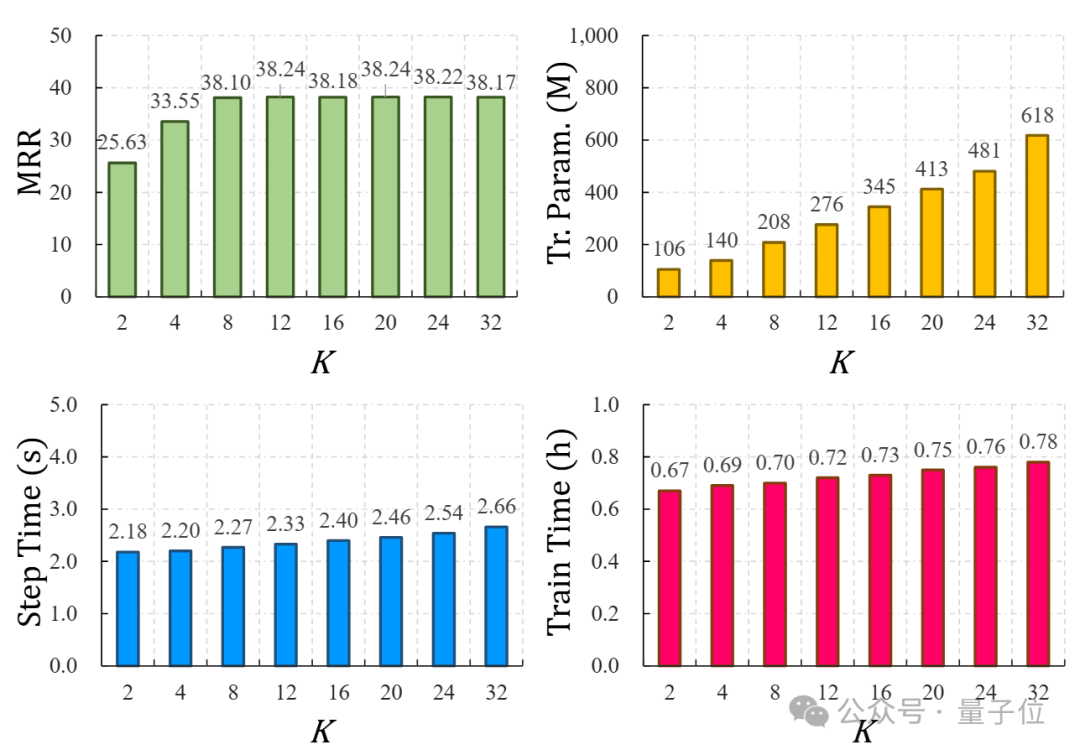
下圖中進一步分析了K-ON中隨著K值的增加,模型各方面性能的變化,這里K的取值直接決定了單個實體最多可以由多少詞元表達。如圖所示,當K取值過小時,由于表達能力不足,K-ON取得的實驗結果很差,但增加至8以后帶來的性能提升已不明顯,而模型可訓練參數量卻穩步上升。
值得注意的是,推理所用單步時間及總訓練時間受K值影響不大,這說明了K-ON多詞元并行預測的高效性。
不僅如此,本文還對K-ON所實現的實體層級的對比學習進行了分析,如下圖所示。可以看出,在幾乎不對訓練效率造成影響的前提下,K-ON可輕易實現涉及上千個負樣本實體的對比學習,但負樣本數量并不是越多越好,將其設為128個左右便可取得最優結果。

本文提出了一種多詞元并行預測方法,通過實體層級的對比學習使大模型能夠感知知識圖譜知識。充分的實驗結果表明,本文方法在知識圖譜相關任務上具有顯著性能優勢,并且較常規大模型方案具有更高的訓練與推理效率。
論文地址:
https://arxiv.org/pdf/2502.06257
螞蟻有18篇技術論文被收錄
當地時間2月25日,AAAI 2025將在美國賓夕法尼亞州費城舉辦,會議為期11天,于3月4日結束。AAAI 由國際人工智能促進協會主辦,為人工智能領域的頂級國際學術會議之一,每年舉辦一屆。AAAI 2025 共有12957篇有效投稿,錄用3032篇,錄取率為 23.4%。
螞蟻有18篇技術Paper收錄,其中3篇Oral,15篇Poster,研究領域涉及增強大模型隱私保護、提高推理速度與推理能力、提升大模型訓練效率、降低模型幻覺等。


























