













微軟Phi-4家族新增兩位成員,5.6B多模態單任務超GPT-4o,3.8B小模型媲美千問7B
動輒百億、千億參數的大模型正在一路狂奔,但「小而美」的模型也在閃閃發光。
2024 年底,微軟正式發布了 Phi-4—— 在同類產品中表現卓越的小型語言模型(SLM)。僅用了 40% 合成數據,140 億參數的 Phi-4 就在數學性能上擊敗了 GPT-4o。
剛剛,微軟又隆重介紹了 Phi-4 模型家族的兩位新成員:Phi-4-multimodal (多模態模型)和 Phi-4-mini(語言模型)。Phi-4-multimodal 改進了語音識別、翻譯、摘要、音頻理解和圖像分析,而 Phi-4-mini 專為速度和效率而設計,兩者都可供智能手機、PC 和汽車上的開發人員使用。

項目地址:https://huggingface.co/microsoft/phi-4
在技術報告中,微軟對這兩個模型進行了更加詳細的介紹。
- Phi-4-Multimodal 是一個多模態模型,它將文本、視覺和語音 / 音頻輸入模態整合到一個模型中。它采用新穎的模態擴展方法,利用 LoRA 適配器和特定模態路由器,實現了多種推理模式的無干擾結合。例如,盡管語音 / 音頻模態的 LoRA 組件只有 46 億參數,但它目前在 OpenASR 排行榜上排名第一。Phi-4-Multimodal 支持涉及(視覺 + 語言)、(視覺 + 語音)和(語音 / 音頻)輸入的場景,在各種任務中的表現均優于此前的大型視覺 - 語言模型和語音 - 語言模型。
- Phi-4-Mini 是一個擁有 38 億參數的語言模型,在高質量的網絡和合成數據上進行了訓練,其性能明顯優于近期類似規模的開源模型,并在需要復雜推理的數學和編碼任務上與兩倍于其規模的模型不相上下。這一成就得益于精心設計的合成數據配方,該配方強調高質量的數學和編碼數據集。與上一代產品 Phi-3.5-Mini 相比,Phi-4-Mini 的詞匯量擴大到了 20 萬個,從而能更好地支持多語言應用,同時還采用了分組查詢功能,從而能更高效地生成長序列。
Phi-4-Multimodal 是這家公司的首個多模態語言模型,微軟表示:「Phi-4-multimodal 標志著我們人工智能發展的一個新里程碑。
此外,微軟還進一步訓練了 Phi-4-Mini 以增強其推理能力。結果顯示,它與 DeepSeek-R1-Distill-Qwen-7B 和 DeepSeek-R1-Distill-Llama-8B 等規模更大的先進推理系統相媲美。

接下來,讓我們看看技術細節。
模型架構
兩個模型都使用 tokenizer o200k base tiktoken ,詞匯量為 200,064 個,旨在更高效地支持多語言和多模態輸入和輸出。所有模型都基于僅解碼器的 Transformer,并支持基于 LongRoPE 的 128K 上下文長度。
語言模型架構
Phi-4-mini 由 32 層 Transformer 組成,專為速度和效率而設計,Phi-4-Mini 還有一些特殊的「省內存」技巧:
首先是分組查詢注意力機制(GQA),模型在處理長序列時能夠快速地聚焦于關鍵信息片段。這優化了長上下文生成時的 KV 緩存。具體來說,模型使用 24 個查詢頭和 8 個 K/V 頭,將 KV 緩存消耗減少到標準大小的三分之一。
其次是輸入 / 輸出嵌入綁定技術,實現了資源的優化利用,同時與 Phi-3.5 相比提供了更廣泛的 20 萬詞匯覆蓋。
此外,在 RoPE 配置中,使用了分數 RoPE 維度,確保 25% 的注意力頭維度與位置無關。這種設計能讓模型更平滑地處理較長的上下文。
Phi-4-Mini 峰值學習率的計算公式為:
LR*(D) = BD^(-0.32),
其中 B 是超參數,D 是訓練 token 的總數,通過調整 D = 12.5B、25B、37.5B 和 50B 來擬合 B 值。
多模態模型架構
Phi-4-Multimodal 采用了「Mixture of LoRA」技術,通過整合特定模態的 LoRAs 來實現多模態功能,同時完全凍結基礎語言模型。該技術優于現有方法,并在多模態基準上實現了與完全微調模型相當的性能。此外,Phi-4-Multimodal 的設計具有高度可擴展性,允許無縫集成新的 LoRA,以支持更多模態,而不會影響現有模態。
該模型的訓練過程由多個階段組成,包括語言訓練(包括預訓練和后訓練),然后將語言骨干擴展到視覺和語音 / 音頻模態。
對于語言模型,研究者使用高質量、推理豐富的文本數據來訓練 Phi-4-Mini。值得注意的是,他們加入了精心策劃的高質量代碼數據集,以提高編碼任務的性能。
語言模型訓練完成后,研究者凍結了語言模型,并實施「Mixture of LoRA」技術,繼續多模態訓練階段。
具體來說,在訓練特定模態編碼器和投影器的同時,還訓練了兩個額外的 LoRA 模塊,以實現與視覺相關的任務(如視覺 - 語言和視覺 - 語音)和與語音 / 音頻相關的任務(如語音 - 語言)。它們都包含預訓練和后訓練階段,分別用于模態對齊和指令微調。

Phi-4-Multimodal 模型架構。
性能評估
Phi-4-multimodal
雖然 Phi-4-multimodal 只有 5.6B 參數,但它將語音、視覺和文本處理無縫集成到一個統一的架構中,所有這些模態都在同一個表征空間內同時處理。
Phi-4 多模態能夠同時處理視覺和音頻。下表顯示了在圖表 / 表格理解和文檔推理任務中,當視覺內容的輸入查詢為合成語音時的模型質量。與其他可以將音頻和視覺信號作為輸入的現有最先進的全方位模型相比,Phi-4 多模態模型在多個基準測試中取得了更強的性能。

圖 1:所列基準包括 SAi2D、SChartQA、SDocVQA 和 SInfoVQA。進行對比的模型有:Phi-4-multimodal-instruct、InternOmni-7B、Gemini-2.0-Flash-Lite-prvview-02-05、Gemini-2.0-Flash 和 Gemini1.5-Pro。
Phi-4-multimodal 在語音相關任務中表現出了卓越的能力。它在自動語音識別 (ASR) 和語音翻譯 (ST) 方面都優于 WhisperV3 和 SeamlessM4T-v2-Large 等專業模型。該模型以令人印象深刻的 6.14% 的單詞錯誤率在 Huggingface OpenASR 排行榜上名列前茅,超過了 2025 年 2 月之前的最佳表現 6.5%。此外,它是少數幾個成功實現語音摘要并達到與 GPT-4o 模型相當的性能水平的開放模型之一。該模型在語音問答 (QA) 任務上與 Gemini-2.0-Flash 和 GPT-4o-realtime-preview 等接近的模型存在差距,因為模型尺寸較小導致保留事實 QA 知識的能力較弱。

圖 2:Phi-4 多模態語音基準。
在下方視頻中,Phi-4-multimodal 分析了語音輸入并幫助規劃西雅圖之旅:

Phi-4-multimodal 同樣在各種基準測試中都表現出了卓越的視覺能力,最顯著的是在數學和科學推理方面取得了優異的表現。盡管規模較小,但該模型在通用多模態能力(如文檔和圖表理解、光學字符識別 (OCR) 和視覺科學推理)方面仍保持著極具競爭性的表現,與 Gemini-2-Flash-lite-preview/Claude-3.5-Sonnet 等相當或超過它們。

Phi-4-multimodal 展示了強大的推理和邏輯能力,適合分析任務。參數量更小也使得微調或定制更容易且更實惠。下表中展示了 Phi-4-multimodal 的微調場景示例。

下方視頻展示了 Phi-4-multimodal 的推理能力:
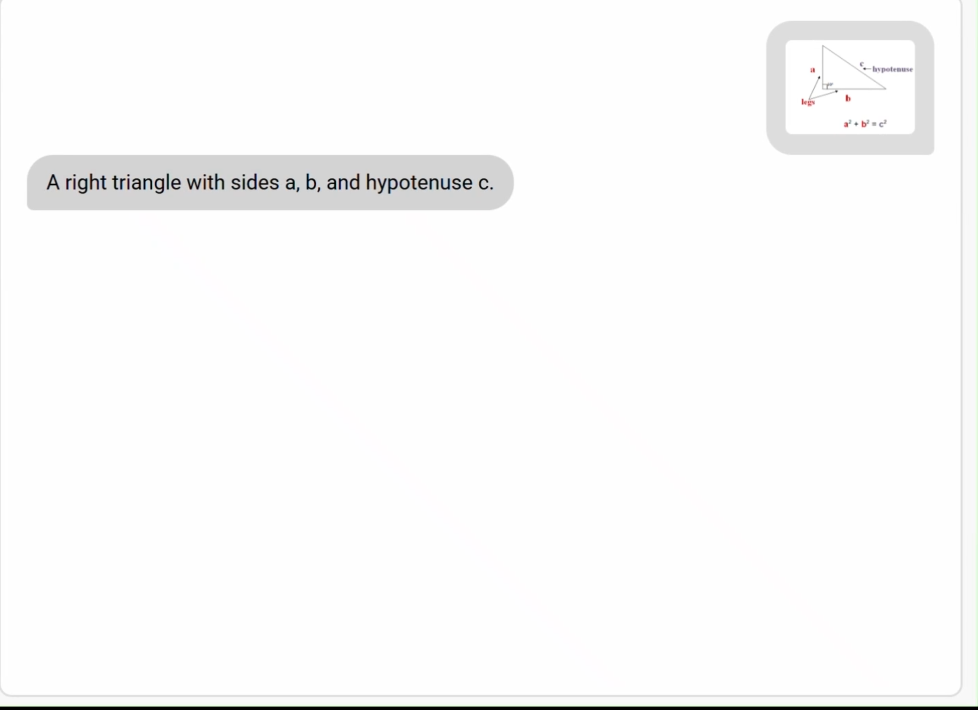
Phi-4-mini:3.8B,小身材大能量
Phi-4-Mini 和 Phi-4-Multimodal 共享同一個語言模型骨干網絡。Phi-4-mini 雖然體積小巧,但它承襲了 Phi 系列前作的傳統,在推理、數學、編程、指令遵循和函數調用等任務上超越了更大的模型。
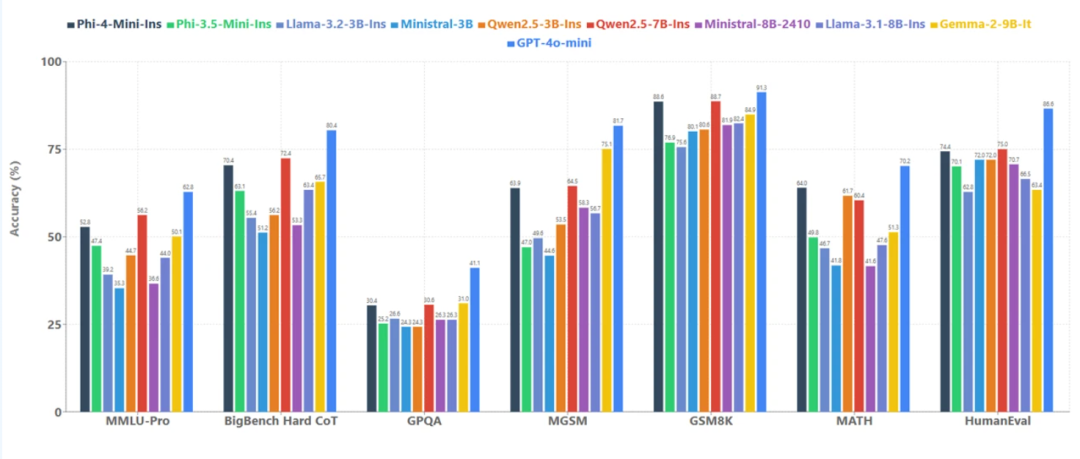
Phi-4-mini 在各種測試集中和較小模型的成績對比
更重要的是,開發者們可以基于 Phi-4-mini 構建出一個可擴展的智能體系統,它可以借函數調用、指令跟隨、長上下文處理以及推理能力來訪問外部知識,從而彌補自身參數量有限的不足。
通過標準化協議,Phi-4-mini 的函數調用可以與結構化的編程接口無縫集成。當用戶提出請求時,Phi-4-mini 能夠對查詢進行分析,識別并調用相關的函數以及合適的參數,接收函數輸出的結果,并將這些結果整合到最終的回應之中。
在設置合適的數據源、API 和流程之后,Phi-4-mini 可以部署在你家,當你的智能家居助手,幫你查看監控有沒有異常。
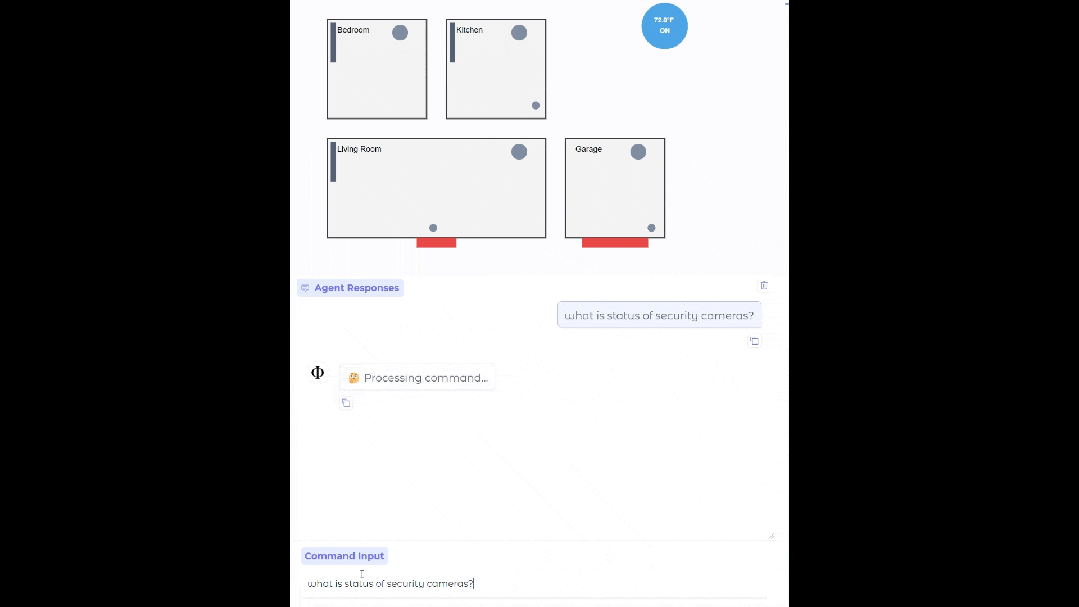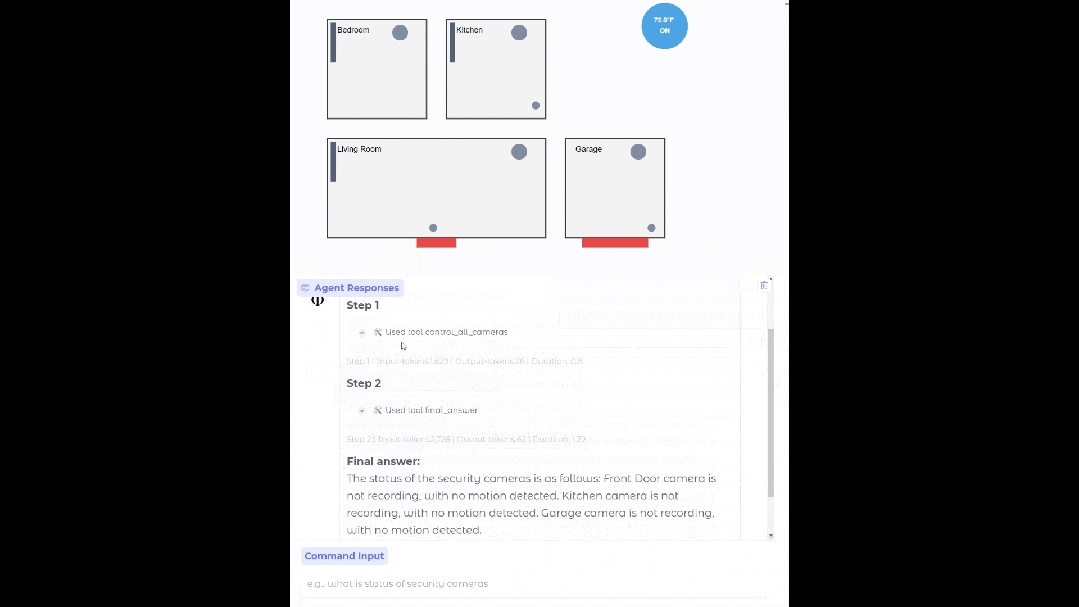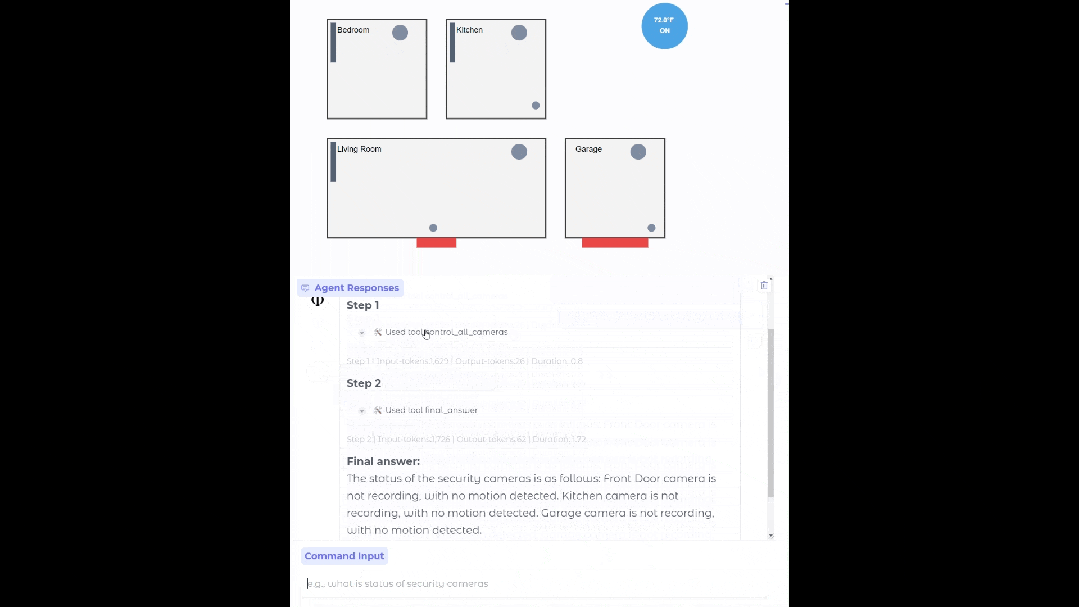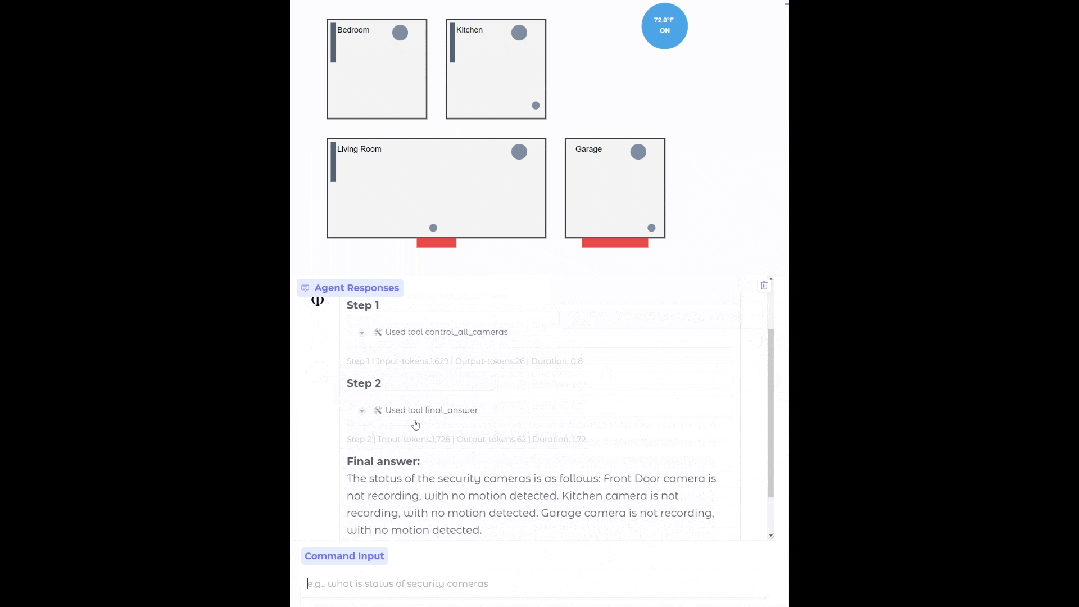
基于 Phi-4-mini 的家居智能體
通過標準化協議,函數調用使得模型可以與結構化的編程接口無縫集成。當用戶提出請求時,Phi-4-mini 可以對查詢進行分析,識別并調用相關的函數以及合適的參數,接收函數輸出的結果,并將這些結果整合到最終的回應之中。這樣一來,就構建了一個可擴展的基于智能體的系統,借助定義良好的函數接口,模型能夠連接到外部工具、應用程序接口(API)以及數據源,進而增強自身的能力。下面的例子就模擬了 Phi-4-mini 控制智能家居的場景。
因為體積較小,Phi-4-mini 和 Phi-4-multimodal 模型可以在計算資源有限的環境中使用,尤其是在用 ONNX Runtime 優化后。
訓練數據
Phi-4-mini 性能明顯優于近期類似規模的開源模型,有一個重要原因就是高質量的訓練數據。
相比上一代 Phi-3.5-Mini,研究人員選擇了更嚴格的數據過濾策略,加入了針對性的數學和編程訓練數據、特殊清洗過的 Phi-4 合成數據,還通過消融實驗重新調整了數據混合比例,增加推理數據的比例為模型帶來了顯著提升。
具體來說,研究人員從推理模型生成了大量合成的思維鏈(CoT)數據,同時采用基于規則和基于模型的兩種篩選方法來剔除錯誤的生成結果,將正確的采樣答案標記為首選生成,將錯誤的標記為非首選,并創建 DPO 數據。
不過,這些數據僅用于實驗性推理模型,所以正式發布的 Phi-4-Mini 版本檢查點中沒有這些 CoT 數據。
在后訓練階段,與 Phi-3.5-Mini 相比,Phi-4-Mini 使用了更大規模和更多樣化的函數調用和摘要數據。研究人員合成了大量的指令跟隨數據來增強模型的指令跟隨能力。
在編程方面,研究人員加入了大量的代碼補全數據,比如要求模型在現有代碼片段中間生成缺失代碼的任務。這挑戰了模型對需求和現有上下文的理解能力,帶來了顯著的性能提升。
Phi-4-Multimodal 模型的預訓練階段涉及豐富多樣的數據集,視覺 - 語言訓練數據包含 0.5T 圖像 - 文本文檔、OCR 數據、圖表理解等;語音相關的訓練數據涵蓋真實和合成數據,使用內部 ASR 模型轉錄音頻并計算原始文本與轉錄之間的詞錯率(WER)來衡量合成語音的質量。
更多詳情,請訪問原項目地址。






























