大模型訓練或無需“純凈數據”!北大團隊新研究:隨機噪聲影響有限,新方法讓模型更抗噪
傳統的大語言模型訓練需要依賴”純凈數據”——那些經過仔細篩選、符合標準語法且邏輯嚴密的文本。但如果這種嚴格的數據過濾,并不像我們想象中那般重要呢?
這就像教孩子學語言:傳統觀點認為他們應該只聽語法完美的標準發音。但現實情況是,孩童恰恰是在接觸俚語、語法錯誤和背景噪音的過程中,依然能夠掌握語言能力。
來自北大的研究人員通過在訓練數據中刻意添加隨機亂碼進行驗證。他們試圖測試模型在性能受損前能承受多少”壞數據”。
實驗結果表明,即便面對高達20%的”垃圾數據”,訓練依然可以正常進行,且Next-token Prediction (NTP) loss受到的影響不足1%!他們不僅揭示了噪聲與模型性能的復雜關系,還提出了一種創新的“局部梯度匹配”方法,讓模型在噪聲環境中依然保持強勁表現。

是什么:隨機噪音會有什么影響?
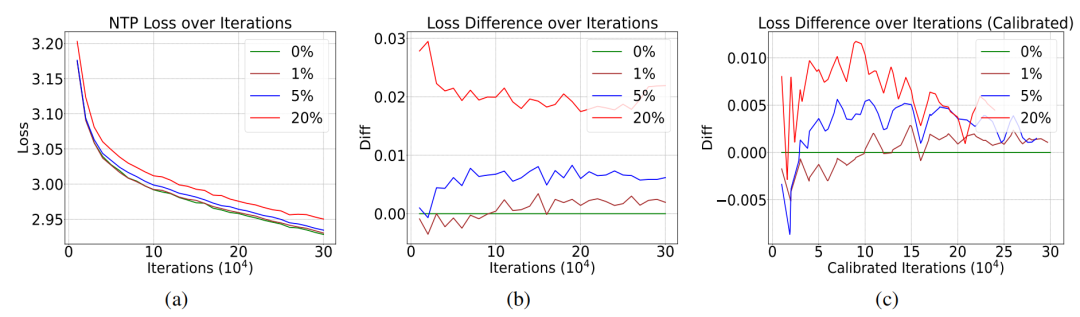
研究者利用OpenWebText數據集,訓練了多個GPT-2相同架構和參數量的語言模型。他們首先生成了一串范圍在0到50256(GPT-2 tokenizer的大小)的整數,其中每個數都遵循0到50256的均勻分布。這樣是為了模擬由于解碼錯誤或網頁崩潰導致的隨機亂碼經過tokenizer之后的結果。之后,研究團隊向OpenWebText中注入占比1%-20%的隨機噪聲,正常進行Next-token Prediction的預訓練。
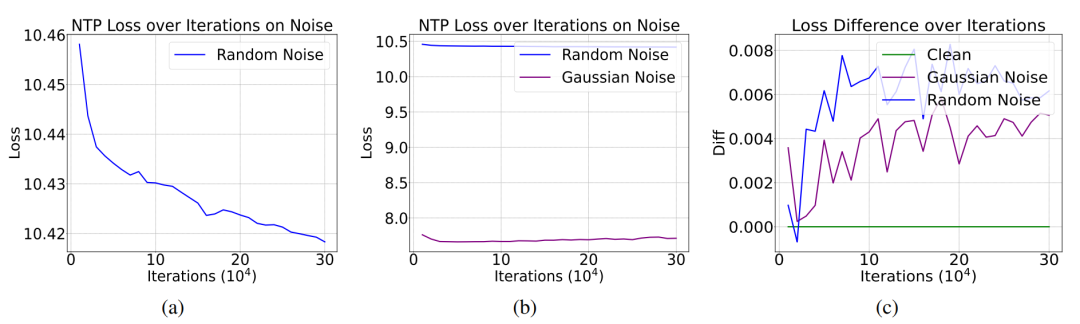
實驗結果揭示了一個反直覺現象:盡管NTP loss受到噪音的影響有些微提升,但是增加幅度遠小于噪音占比。即使20%的數據被污染,模型的下一個詞預測損失僅上升約1%。
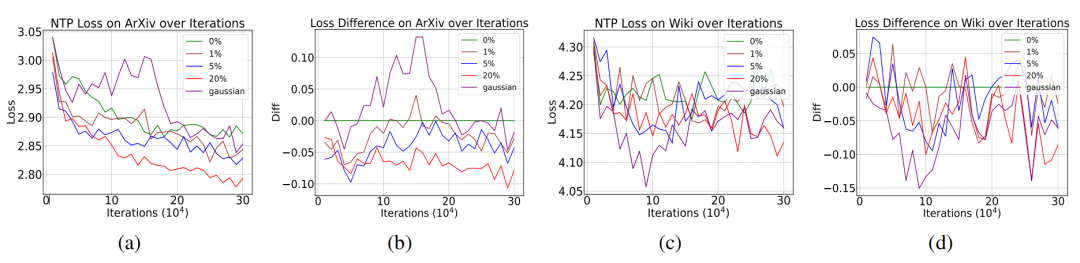
更令人驚訝的是,在arXiv和Wikipedia語料測試中,含噪模型甚至展現出更低的NTP loss。
這些反常現象的出現引發了研究團隊的思考。他們想要知道這種現象出現的背后原因。
為什么:理論角度分析隨機噪音
遵照之前的理論工作,研究團隊把NTP過程建模成在 (給定前綴, 下一token) 的聯合概率分布上的分類任務。用P^c表示干凈分布,P^n表示噪音分布,作者指出,我們真正關心的不是模型在噪音P^n上的損失,而是在噪音分布上訓練出來的模型 h 與最優模型 h* 在干凈分布P^c上的 NTP loss 差距。
為了給出證明,研究團隊首先注意到,在隨機亂碼中找到一段有意義文本的概率極低。用數學語言來描述,這意味著干凈分布P^c和噪音分布P^n的支撐集(support set)的交集可以認為是空集。
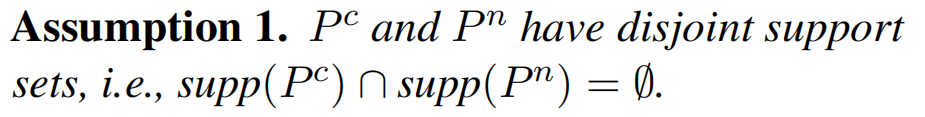
基于這條假設,研究團隊成功證明,當噪音占比 α 足夠小時,P^n的存在不改變 NTP loss的全局最小值。哪怕 α 足夠大,噪音對損失函數帶來的影響也遠小于其占比。

由于Assumption 1并不只在隨機噪音時成立,因此結論可以推廣到其他情況。最直接的場景便是多語言模型的訓練。顯然,在一種語言(英語)看來,另一種語言(漢語)就是隨機亂碼,他們之間的token彼此是不重合的,兩者對應的分布自然沒有交集,也就滿足了Assumption 1。因此,Proposition 1表明,在多語言數據集中進行預訓練,單個語言的性能不會受到太大的影響。這就解釋了多語言模型的成功。此外,Proposition 1還可以解釋為什么在充滿背景噪音的數據集上訓練的音頻模型可以成功。
為了進一步檢驗上述理論,研究團隊還隨機生成了先驗分布服從高斯分布的隨機噪音。由于高斯分布有規律可循,這種噪音對應的NTP loss更低。按照Proposition 1的結論,更低NTP loss的噪音P^n對模型性能的影響更小。實驗結果驗證了這一預言,也就證明了Proposition 1的正確性。
怎么做:如何彌補隨機噪音的影響
盡管預訓練損失變化微弱,下游任務卻暴露出隱患。實驗顯示,在高斯噪音上訓練的模型,盡管其相比隨機噪音對應模型的NTP loss更低,但在文本分類下游任務中的準確率卻下降高達1.5%。這種“損失-性能解耦”現象表明,預訓練指標NTP loss無法全面反映模型的實際能力。研究者指出,噪聲會扭曲特征空間的梯度分布,導致微調時模型對細微擾動過于敏感。
針對這一挑戰,團隊提出了一種即插即用的解決方案——局部梯度匹配損失(LGM)。具體來說,由于在下游任務應用大模型時幾乎不會從頭預訓練,研究團隊在黑盒模型的假設下提出了LGM這一微調方法。其無需訪問模型參數,而是通過向特征添加高斯噪聲并約束原始/擾動特征的梯度差異,直接增強分類頭的抗噪能力。其核心思想在于:迫使模型在特征擾動下保持決策一致性,從而彌合噪聲導致的特征偏移。對于黑盒模型提取的特征 t,首先添加一定程度高斯擾動得到 \hat{t},然后將分類頭關于t和 \hat{t} 的梯度差作為損失函數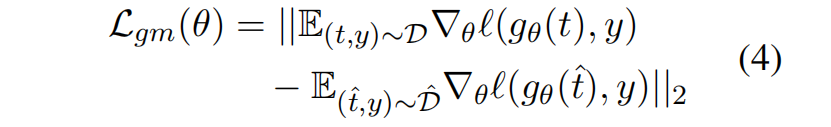
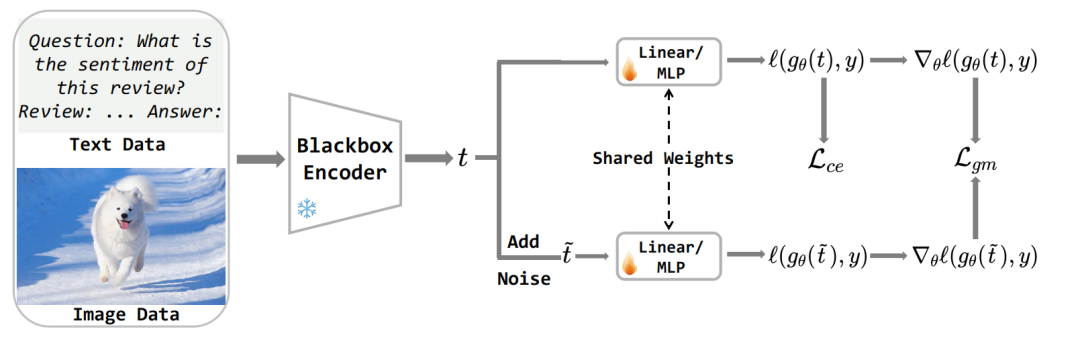
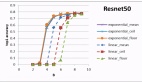
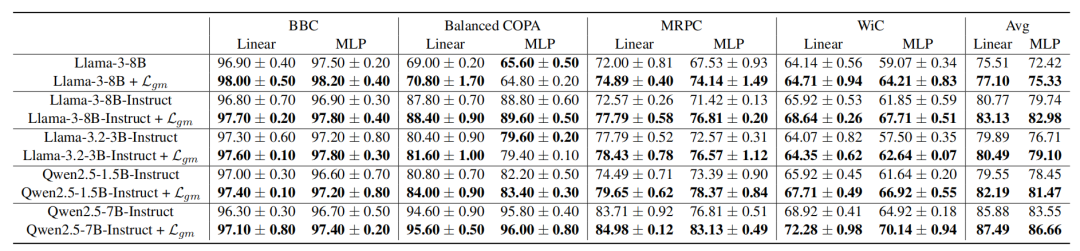
實驗部分,團隊在8個自然語言理解和14個視覺分類數據集上驗證了模型性能。
對于受到噪音影響的模型,LGM可以顯著增強性能。

出乎意料的是,當把LGM用在干凈模型(如Llama-3、ViT-L)上時,下游任務準確率仍可提升1%-3%。

為了解釋LGM的成功,研究團隊從 Sharpness-Aware Minimization的角度,證明了LGM損失和損失函數的光滑程度、對輸入的敏感程度有緊密關系:
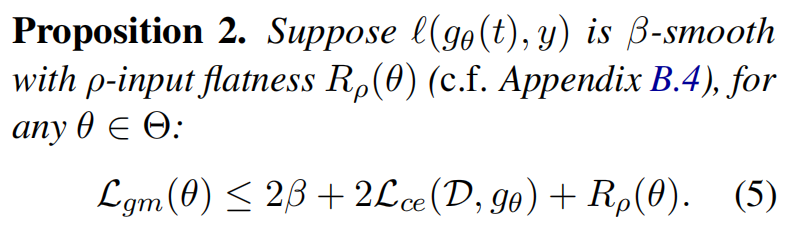
啟示與展望:數據清洗的新思考
這項研究為大規模預訓練提供了全新視角:
- 效率革命:適度保留隨機噪聲可降低數據清洗成本,尤其對資源有限的團隊意義重大
- 理論擴展:理論框架可用于解釋多語言模型的成功,還可用于其他模態
- 數據增強:可控噪聲注入或成新型正則化手段,提升模型泛化能力
當然,研究也存在局限:實驗僅基于GPT-2規模模型,超大規模模型(如GPT-4)的噪聲耐受性仍需驗證。團隊計劃進一步探索噪聲類型與模型容量的動態關系,以及LGM在其他模態中的應用。