給大語言模型“開個眼”,看圖說話性能超CLIP!斯坦福等新方法無需多模態預訓練
本文經AI新媒體量子位(公眾號ID:QbitAI)授權轉載,轉載請聯系出處。
不靠多模態數據,大語言模型也能看得懂圖?!
話不多說,直接看效果。
就拿曾測試過BLIP-2的長城照片來說,它不僅可以識別出是長城,還能講兩句歷史:

再來一個奇形怪狀的房子,它也能準確識別出不正常,并且知道該如何進出:

故意把“Red”弄成紫色,“Green”涂成紅色也干擾不了它:

這就是最近研究人員提出的一種新模塊化框架——LENS??(Language-Enhanced Neural System)的識別效果。
重要的是,不需要額外在多模態數據集上進行預訓練,只用現成的大語言模型就能完成目標識別和視覺推理任務。
既省錢又省力!
研究人員表示:
這種方法在零樣本的情況下效果可與多模態大模型Kosmos,以及可開箱即用的Flamingo等端到端聯合預訓練模型相匹敵,性能甚至可能會更好。
網友看到這不淡定了:
激動啊家人們!用來訓練大模型的資源現在也可以被用于解決不同領域的問題了。??

還有網友表示:
想看哪個模塊最能提高視覺推理能力,這很有趣!

怎么做到的?
現有的LLM雖然在自然語言理解和推理方面表現出色,但都不能直接解決從視覺輸入進行推理的任務。
這項由Contextual AI和斯坦福大學研究人員共同完成的工作,利用LLM作為凍結的語言模型(不再進行訓練或微調),并為它們提供從“視覺模塊”獲取的文本信息,使其能夠執行目標識別和V&L(視覺和語言)任務。
 圖片
圖片
簡單來說,當你問關于一張圖片的內容時,該方法會先操作三個獨立的“視覺模塊”,Tag Module(提取標簽信息)、Attribute Module(提取屬性信息)、Intensive Captioning Module(生成詳細的圖像描述),以此提取出關于圖像的文本信息。
然后直接將這些信息輸入到推理模塊(Reasoning Module)中,也就是凍結的LLM,對問題進行響應回答。
 圖片
圖片
這樣一來,通過集成LENS可以得到一個跨領域自動適用的模型,無需額外的預訓練。并且能夠充分利用計算機視覺和自然語言處理領域的最新進展,最大限度地發揮這些領域的優勢。
在此前,已經有研究提出了幾種利用LLM解決視覺任務的方法。
- 其中一種方法是先訓練一個視覺編碼器,然后將每個圖像表示為連續嵌入序列,讓LLM能夠理解。
- 另一種方法是使用已經訓練對比的凍結視覺編碼器,同時引入新的層到凍結的LLM中,并從頭開始訓練這些層。
- 第三種方法是同時使用凍結的視覺編碼器(對比預訓練)和凍結的LLM,通過訓練輕量級transformer將它們對齊。
視覺編碼器是指用于將視覺輸入(如圖像或視頻)轉換為表示向量的模型或組件。它能夠將高維的視覺數據轉換為低維的表示,將視覺信息轉化為語言模型可以理解和處理的形式。
顯而易見,這三種方法都需要用數據集進行多模態預訓練。
 圖片
圖片
△視覺和語言模態對齊方法的比較,(a)代表上面所說的三種方法(b)是LENS的方法,??代表從頭開始訓練,??代表預訓練并凍結
LENS則是提供了一個統一的框架,使LLM的“推理模塊”能夠從“視覺模塊”提取的文本數據上進行操作。
在三個“視覺模塊”中,對于標簽這一模塊,研究人員搜集了一個多樣全面的標簽詞匯表。包括多個圖像分類數據集,目標檢測和語義分割數據集,以及視覺基因組數據集。為了能夠準確識別并為圖像分配標簽,研究人員還采用了一個CLIP視覺編碼器。
這一模塊的通用提示語是:
“A photo of {classname}”
用于提取屬性信息的視覺模塊中,則用到了GPT-3來生成視覺特征描述,以區分對象詞匯表中每個對象的類別。并且采用了一個對比預訓練的CLIP視覺編碼器,來識別并為圖像中的對象分配相關屬性。
在詳細描述信息的視覺模塊中,研究人員用BLIP的圖像字幕模型,并應用隨機的top-k采樣為每個圖像生成N個描述。這些多樣化的描述直接傳遞給“推理模塊”,無需進行任何修改。
而在最后的推理模塊,LENS可以與任何LLM集成,將上面的提取的信息按照下面的格式進行整合:
Tags: {Top-k tags}
Attributes: {Top-K attributes}
Captions: {Top-N Captions}.
OCR: this is an image with written “{meme text}” on it.
Question: {task-specific prompt} \n Short Answer:值得一提的是,表情包也被考慮在內了,為此研究人員專門加入了一個OCR提示。
性能比CLIP好
為了展示LENS的性能,研究人員用了8塊NVIDIA A100 (40GB)顯卡進行了實驗,并默認冷凍的LLM為Flan-T5模型。
對于視覺任務,研究人員評估了8個基準,并在零樣本和少樣本設置下與目標識別領域的最新模型進行了比較。
 圖片
圖片
△LENS在目標識別任務中的零樣本結果
經上表可看出,在零樣本情況下,由ViT-H/14作為視覺主干和Flan-T5xxl作為凍結LLM組成的LENS,平均表現比CLIP高了0.7%。LENS的其它組合在大多數情況下,表現也優于CLIP。
有趣的是,研究人員在目標識別任務中發現:
凍結的LLM的大小與分類性能之間似乎沒有直接關系。而標簽生成架構(ViT主干)的大小與性能之間存在對應關系。
 圖片
圖片
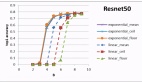
△少樣本下,LENS在視覺任務上的平均性能。
如上圖所示,研究人員還繪制了除ImageNet之外的所有數據集的平均視覺性能圖,并觀察到:
更多樣本有助于提高性能。同時,凍結LLM的性能與視覺性能之間沒有直接關系,而更好的視覺主干有助于提高平均視覺性能。
對于視覺與語言任務,研究人員評估了四個具有代表性的視覺問答任務,并與需要進行額外預訓練來對齊視覺和語言模態的最新模型進行了比較。
在零樣本設置上,與VQAv2、OK-VQA、Rendered-SST和Hateful Memes最先進的方法進行比較,LENS表現依舊能與依賴大量數據進行對齊預訓練的方法相競爭。即使與規模更大、更復雜的系統如Flamingo、BLIP-2、Kosmos相比也是如此。

雖然LENS在大多數情況下表現良好,但也有一些失敗的情況:
 圖片
圖片
研究人員認為:
LENS的視覺能力嚴重依賴于其底層的視覺組件。這些模型的性能有進一步提升的空間,需要將它們的優勢與LLM結合起來。
傳送門:
[1]https://huggingface.co/papers/2306.16410(論文鏈接)
[2]https://github.com/ContextualAI/lens(代碼已開源)