DeepSeek效應初現:Grok-3補刀ChatGPT,OpenAI已在ICU?
語言模型競技場LM Arena,新的「全能冠軍」誕生了!
這次是「地球上最聰明的AI」——Grok 3。

Grok 3證明了Scaling Law的確有效,OpenAI技術護城河被攻破!


此前,DeepSeek證明不用Scaling Law也能達到OpenAI o1水平。
真是「一根筋,兩頭堵」:無論Scaling Law有用沒用,OpenAI的技術「窗戶紙」被捅破了。
這不得不懷疑OpenAI到底行不行?OpenAI的盈利模式有可持續性嗎?xAI+DeepSeek又能帶來什么?
Atreides Management的管理合伙人和首席投資官Gavin S. Baker,分享了自己對AI競爭的見解。

OpenAI時代結束
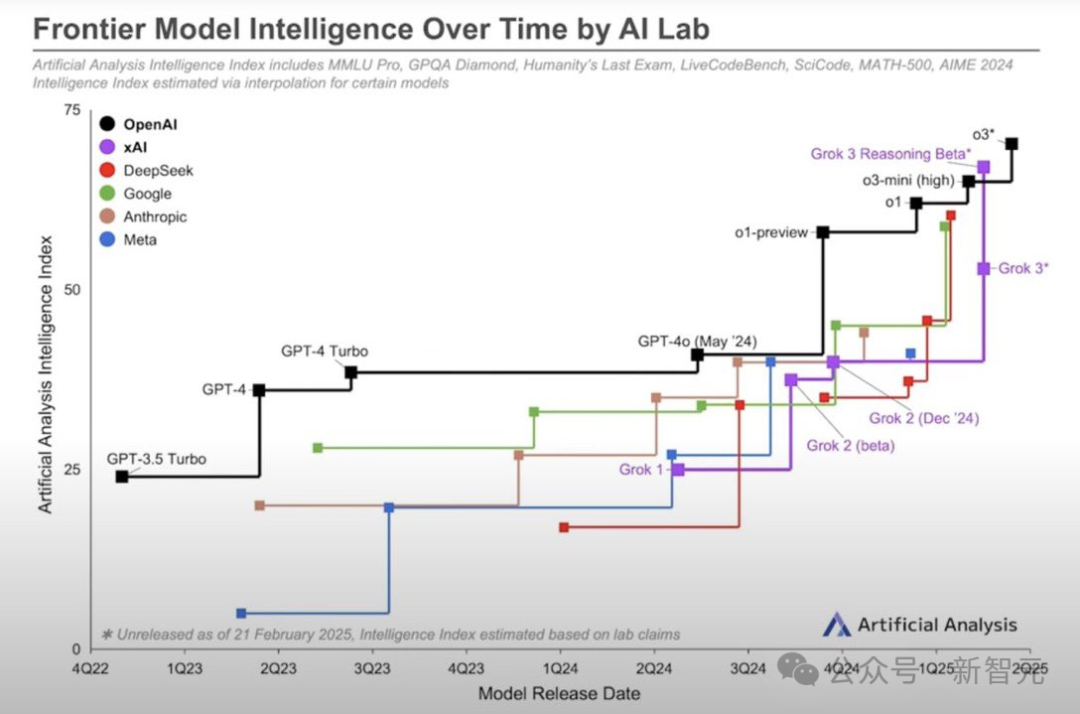
從2022年夏季到2024年春季,OpenAI在GPT-4上領先,直到谷歌和Anthropic追上了GPT-4。
OpenAI是首個積極采用傳統「Scaling Law」進行預訓練的公司,享受了大約7個季度的主導地位。
首次實現o1推理只帶來了幾個月的優勢。
如今,DeepSeek、谷歌和xAI與OpenAI大致處于同一水平,其中xAI可能稍占優勢。
谷歌和xAI預計很快會憑借其更好的基礎模型,顯著超越o3。
因此,OpenAI迫切需要推出GPT-5,作為未來「o5」推理模型的基礎。
奧特曼都承認,OpenAI未來的領先優勢將會縮小。
而微軟CEO納德拉則明確表示,在模型能力上,OpenAI一度擁有獨特的優勢,而這一即將結束。
OpenAI沒有獨門秘籍
谷歌和xAI都擁有獨特且有價值的數據源,這些數據源使它們逐漸區別于DeepSeek、OpenAI和Anthropic。
如果Meta在模型能力方面趕上,也會如此。
Gavin S. Baker認為:沒有訪問獨特且有價值數據的頂級AI模型,是有史以來貶值最快的資產。
蒸餾只會加劇這一現象。
微軟似乎也認同這一觀點:選擇了不再給OpenAI投入1600億美元進行預訓練,并取消了傳聞中的數據中心建設。

如果沒有訪問YouTube、X、TeslaVision、Instagram和Facebook等獨有數據,未來的尖端模型可能不會有投資回報(ROI)。
從這個角度看,扎克伯格的戰略似乎更加合理。
最終,獨有的數據可能是唯一能夠帶來差異化,并對預訓練萬億甚至千萬億級別參數模型的投資回報的基礎。
OpenAI難以一家獨大
經濟學家Ethan Mollick,則認為AI的確進入了新時代,OpenAI時代落幕了。

左圖是訓練Scaling Law,也就就是說模型規模越大,性能越強。訓練更大的模型需要增加計算能力、數據和能源的使用量。
通常,需要將計算能力增加10倍以獲得性能的線性增長。計算能力以FLOPs(浮點運算)衡量,這是計算機執行的基本數學運算的數量,如加法或乘法。
右圖是推理Scaling Law,也就就是說模型思考越久,它表現越好。
如果讓模型花更多計算能力去處理問題,就能得到更好的結果——
就像給聰明人幾分鐘額外時間來解決謎題一樣。
這稱之為測試時或推理時計算
第二個規模法則誕生了推理模型(Reasoner)。
在需要時,第三代模型都將作為Reasoners運行,因為有兩個優勢:更大的訓練規模,以及在解決問題時具有可擴展性。

這兩個Scaling Law正在極大地提升AI的數學能力,并且還在增加其他方面的能力。
如果有一個大型、智能的AI模型,就可以用它來創建更小、更快、更便宜的模型,這些模型的智能程度雖然不如母模型,但仍然相當高。
即使是小型模型,但加入了推理能力,它們會變得更加智能。這意味著AI的能力在提升,而成本卻在下降。
下圖展示了這一趨勢的迅速發展,y軸上表示AI的能力,x軸上表示成本的對數下降。
GPT-4剛發布時,每百token大約需要50美元(大約相當于一個單詞)。
而現在使用比比原始GPT-4更強大的Gemini 1.5 Flash,每百萬token的成本大約只有12美分,成本下降了99%+。
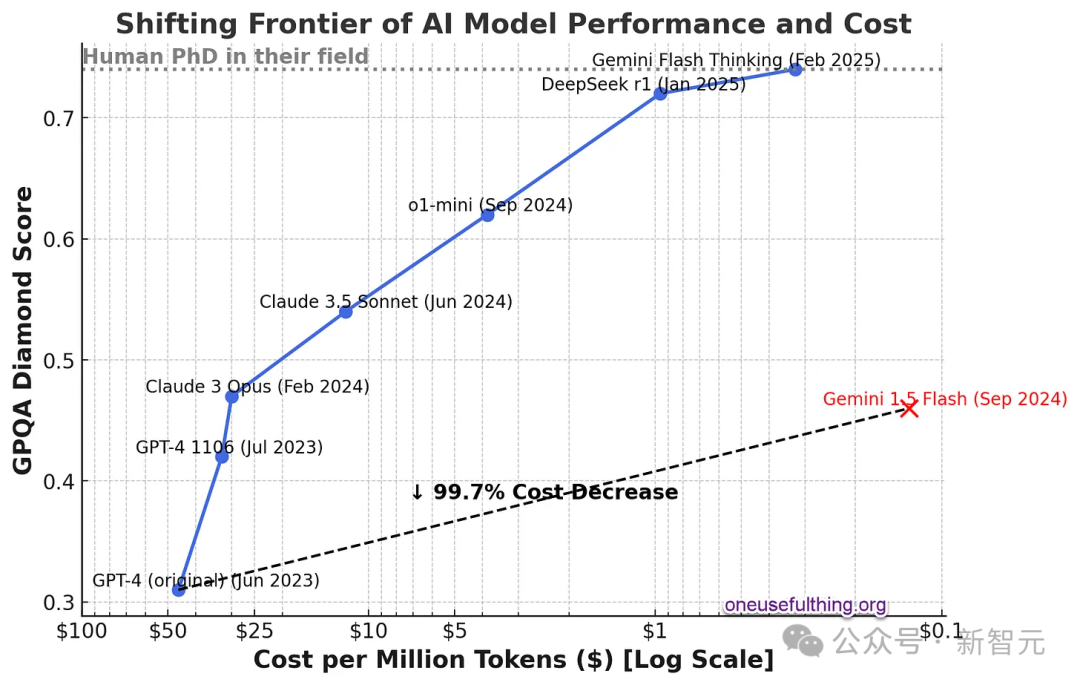
GPQA是一系列非常難的多項選擇題,旨在測試高級知識。擁有互聯網訪問權限的博士在其專業領域外的正確率為34%,在其專業領域內的正確率為81%。每百萬token的成本是使用模型的成本(Gemini Flash Thinking的成本是估算的)。
OpenAI內憂外患
Gavin S. Baker認為微軟之所以不給OpenAI提供1600億美元的預訓練資金,就是因為AI的預訓練是前期成本,并不能帶來利潤。
相反,微軟將提供OpenAI推理服務來賺錢。

The information估計軟銀今年將在OpenAI產品上投入超過20億美元,約占OpenAI收入的20%。25-30年,OpenAI在算力上的花費為3200億美元。2027年現金消耗達200億美元。
而在2023年,納德拉一度公開表示無法想象沒有AI的生活,要全力押注AI。

現在微軟和OpenAI的裂痕在持續加大。最近,納德拉的采訪更是被解讀為微軟與OpenAI不和,引起股價下跌。

去年,微軟就表示將非OpenAI的模型接入到Copilot中。
在未來某個時刻,微軟甚至可能使用開源模型來支持Copilot。

Copilot已有多家AI供應商
除了最大的外部合作伙伴,一些高管和重要員工也紛紛另立門戶。
前CTO,Mira Murati,與OpenAI的老同事聯合創立了Thinking Machines Lab,目標是AI研究和產品。
前首席科學家,Ilya Sutskever,創立了Safe Superintelligence,目標是AI安全。
創始員工,Andrej Karpathy,兩度加入OpenAI,最后選擇離開,創立Eureka Labs,主營業務為AI教育。
副總裁,Dario Amodei,創立Anthropic,最近剛剛推出了AI模型Claude 3.7 Sonnet。
更不要提,馬斯克還在法院提起訴訟,竭力阻止奧特曼將OpenAI轉為非營利公司。
AI的收入來自推理
如果Scaling Law還有效,訓練數據決定了未來大模型的投資回報,那么只有2到3家公司,會進行尖端模型的預訓練。
只要少數幾個巨型數據中心,就足以讓它們進行所需的連續集群預訓練。
其余的AI計算只需要一些較小的數據中心,這些數據中心經過地理優化,從而實現了低延遲和/或高成本效益的推理。
Gavin S. Baker認為:「經濟高效的推理 = 更便宜、質量較低的電力」。
現在,全世界有6-10家公司會預訓練尖端模型,但到那時,一切將截然不同。
請注意,推理模型的計算量非常大。測試時的計算意味著計算就是智能。
因此,與2023-2024年整個市場的「以預訓練為中心」相比,這種情況所需的計算量可能還要大。
這和目前的算力分布,完全不同:
不再是預訓練和推理各占50%的情況。
而可能變成預訓練只占5%,推理占95%。
很多硬件將針對推理進行優化,而很少針對預訓練優化。
卓越的基礎設施將至關重要。
所有這些都沒有考慮到設備上(on-device)推理和/或完全量化的影響。
而超級智能(ASI)的經濟效益,本質上是未知的。
Gavin S. Baker希望它們很高,但一個擁有140智商的模型,在設備上運行并訪問關于世界的獨特數據,對于大多數用例來說可能已經足夠。
ASI(超級智能)并不需要用來預訂旅行等任務。
到2030年,推理成本(即運行AI模型的成本)預計將超過訓練成本,因此OpenAI需要一個長期可持續的解決方案。
如果Stargate項目未能提供與微軟云服務相同的穩定性和效率,這可能會帶來重大風險。
時間會證明一切。
DeepSeek效應
即便是DeepSeek梁文峰公開表示,業內對DeepSeek-R1反應過度。他表示這只是一次一般的普通的創新,世界每天都有類似這樣的創新。
不妨假設一下,DeepSeek來自美國中西部某個實驗室。
比如,某個計算機科學實驗室買不起最新的英偉達芯片,只能使用舊硬件。
但他們有一個很棒的算法和系統部門,用幾百萬美元訓練了一個模型:
瞧,這個模型與o1大致相當。看,我們找到了一個新的訓練方法,我們優化了很多算法!
每個人都像「哦哇」一樣開始嘗試同樣的方法,然后歡呼:這是AI進步的一周!
美國股市也不會因此蒸發一萬億美元。
DeepSeek的確在大模型訓練上,取得了一些創新。但和其他從業人員一樣研究同樣的問題。
不僅如此,他們還發表了論文,并開源了模型。
在開源AI界,甚至出現了用最經濟的方法,復刻DeepSeek-R1「頓悟時刻」的競賽。
這一切就像是2004年的谷歌。
在2004年,谷歌在上市招股書S-1文件中,向世界透露他們使用分布式算法,在計算機網絡中將商品連接在一起,實現了最佳的性價比,從而構建了最大的超級計算機集群。

谷歌S-1文件鏈接:https://www.sec.gov/Archives/edgar/data/1288776/000119312504073639/ds1.htm
這與當時其他所有科技公司都不同,它們只是購買越來越大的大型機。
為了跟上不斷上升的交易量,一些大公司會從甲骨文購買越來越大的數據庫服務器。
谷歌的S-1描述了如何能夠超越大型機的可伸縮性限制。
后來,谷歌發表了MapReduce和BigTable論文,描述了用于管理和控制這個成本效益更高、功能更強大的超級計算機的算法。
谷歌在取得如此巨大成功之后,并沒有馬上發表論文,公開他們的做法。
相比之下,在與模型發布的同時,DeepSeek發表了論文。
DeepSeek的發展軌跡,與2004年谷歌展示自己的能力并沒有什么本質不同。
競爭對手仍然需要調整并實際去做這件事,但DeepSeek推動了這一領域的發展。
認為英偉達、OpenAI、Meta、微軟、谷歌等公司已經完蛋了,這種想法也沒什么理由。
當然,DeepSeek是一個新的、強大的新興公司,但AI領域不是每周都會出現這樣的情況嗎?
每個人都會在幾個月內復制這一成就,一切都會變得更便宜。
唯一的真正后果是,AI烏托邦/末日現在比以往任何時候都要近。