LeCun世界模型再近一步!Meta研究證明:AI可無先驗理解直覺物理
對物理的直觀理解是人類認知的基礎:期望物體的行為,具有可預測性,也就是說,物體不會突然出現或消失,穿過障礙物,或隨意改變形狀或顏色。
這種對物理的直觀理解,還在更多物種中得到證實,包括猴子、鯨魚、烏鴉等。
相關研究人員猜測:人類天生或嬰幼兒時期就具備一套進化形成的、古老的系統,專門用于表示和推理世界的基本屬性,比如物體、空間、數字、幾何形狀等。
Meta新研究證明,沒有任何先驗知識,自監督視頻模型V-JEPA,也能夠理解直觀物理學!
換句話說,通過觀察,V-JEPA覺醒了物理直覺,和人類一樣不需要硬編碼,天生如此!
V-JEPA不是去生成像素級的精準預測,而是在抽象的表示空間里進行預測。
這種方式更接近LeCun所認為的人類大腦處理信息的模式。
他甚至回歸X平臺,轉發論文通訊作者的post,宣布:「新方法學會了直觀物理」。
這次的主要發現如下:
- V-JEPA能夠準確且一致地分辨出,符合物理定律的視頻和違反物理定律的視頻,遠超多模態LLM和像素空間中的視頻預測方法。
- 雖然在實驗中觀察到改變模型的任一組件,都會影響性能,但所有V-JEPA模型都取得了明顯高于隨機水平的表現。

論文鏈接:https://arxiv.org/abs/2502.11831
V-JEPA被網友Abhivedra Singh評價為:AI的關鍵飛躍!
AI直觀物理: 第三條路
在語言、編碼或數學等高級認知任務上,現在高級的AI系統通常超越人類的表現。但矛盾的是,它們難以理解直觀物理,沒有物理直覺。
這就是莫拉維克悖論(Moravec's paradox),即對生物體來說微不足道的任務,對人工系統來說可能非常困難,反之亦然。
之前,有兩類研究致力于提高AI模型對直觀物理的理解:結構化模型和基于像素的生成模型:
1. 結構化模型:利用手工編碼的物體及在3D空間中關系的抽象表示,從而產生強大的心理「游戲引擎」,能夠捕捉人類的物理直覺。這是核心知識假設的一種可能的計算實現。
2. 基于像素的生成模型則持截然相反的觀點,否認需要任何硬編碼的抽象表示。相反,它們提出了通用的學習機制,即基于過去的感官輸入(例如圖像)來重建未來的感官輸入。
新研究則探討了位于這兩種對立觀點之間、第三類模型:聯合嵌入預測架構(Joint Embedding Predictive Architectures,JEPAs)。
新研究專注于視頻領域,特別是視頻聯合嵌入預測架構V-JEPA。V-JEPA在下列文章中首次提出。

論文鏈接:https://arxiv.org/abs/2404.08471
基于心理學的預期違背理論,這次直接探測直觀物理理解,而不需要任何特定任務的訓練或調整。
研究人員通過促使模型去想象未來的視頻表示,并將其預測與實際觀察到的未來視頻進行比較,獲得了定量的驚訝度,用來檢測違背的直觀物理概念。
測量直觀物理理解
預期違背
預期違背起源于發展心理學。
受試者(通常是嬰兒)會看到兩個相似的視覺場景,其中一個包含物理上的不可能事件。
然后通過各種生理測量方法,獲得他們對每個場景的「驚訝」反應,并用于確定受試者是否發生了概念違背。
這種范式已被擴展到評估AI系統的物理理解能力。
與嬰兒實驗類似,向模型展示成對的場景,其中除了違反特定直觀物理概念的單個方面或事件,其他所有方面(物體的屬性、物體的數量、遮擋物等)在兩個場景中都保持相同。
模型對不可能場景表現出更高的驚訝反應,反映了對被違背的概念的正確理解。
理解直觀物理的視頻預測
V-JEPA架構的主要開發目的,是提高模型適應高級下游任務的能力,直接從輸入中獲取,而不需要一連串的中間表征。
研究團隊驗證了一個假設,即這種架構之所以能成功完成高級任務,是因為它學會了一種表征方式,這種方式能隱含地捕捉到世界中物體的結構和動態,而無需直接表征它們。
如下圖所示,V-JEPA是通過兩個神經網絡實現的:
- 編碼器:從視頻中提取表示;
- 預測器:預測視頻中人為遮蔽部分的表示,比如隨機遮蔽的時空塊、隨機像素或未來幀。
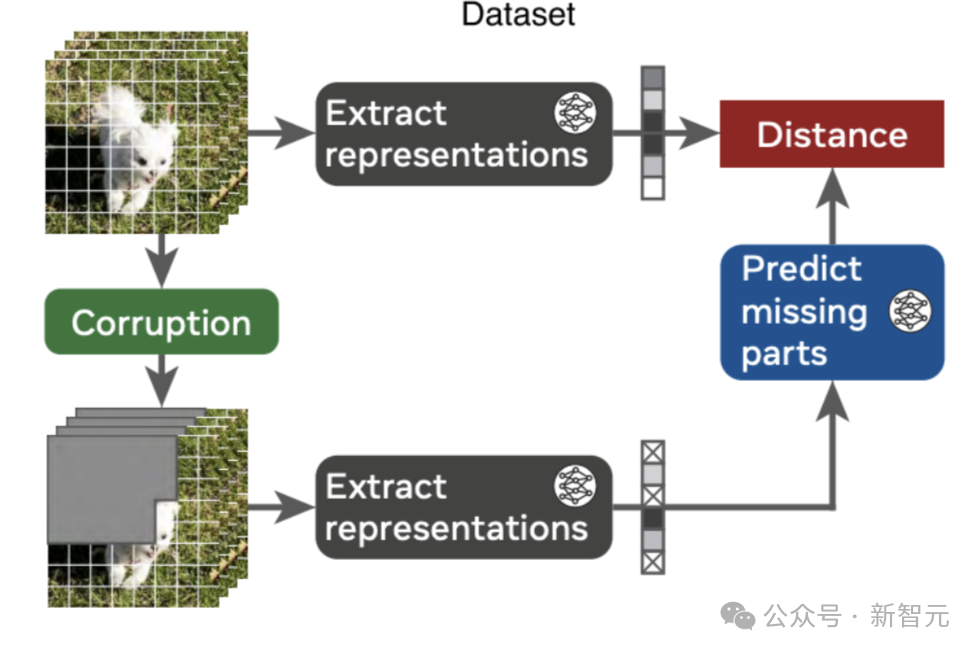
訓練從視頻和損壞版開始,首先提取表征。
然后,從損壞視頻的表征,來預測原始視頻的表征。通過編碼器和預測器的聯合訓練,編碼器能夠學習到編碼可預測信息的抽象表示,并舍棄低層次(通常較少語義)的特征。
經過訓練之后,在學習到的表征空間中,V-JEPA可以「修復」自然視頻。
在自監督訓練之后,可以直接使用編碼器和預測器網絡,無需任何額外的適應,來探測模型對世界理解的程度。
具體來說,通過遍歷視頻流,模型會對觀測到的像素進行編碼,并隨后預測視頻中后續幀的表示,如圖1.C所示:
從訓練好的V-JEPA 中,基于M個過去的幀,預測N個未來幀的表征。
然后比較預測與觀察到的事件表征,來計算驚訝度指標。
最后,使用驚訝度指標,決定兩個視頻中的哪一個違反了物理學定律。
通過記錄每個時間步的預測誤差——即預測的視頻表示與實際編碼的視頻表示之間的距離——獲得了一個在時間上對齊的、量化模型在視頻中驚奇程度的度量。
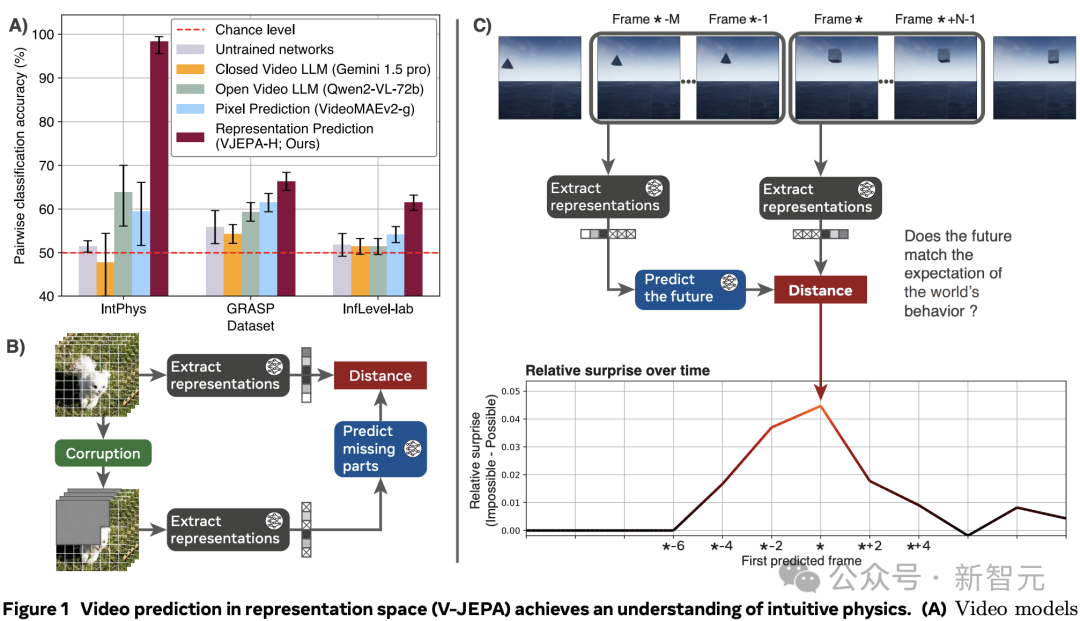
圖1:在表征空間中進行視頻預測(V-JEPA)實現對直觀物理的理解。
改變模型用來預測未來的過去視頻幀(上下文)的數量,可以控制記憶;通變視頻的幀率,可以控制運動的精細度。
AI發現「物理穿幫」鏡頭
研究團隊評估了三個數據集上的直觀物理理解:IntPhys的dev數據集、GRASP和 InfLevel-lab。
這些基準測試的組合提供了視覺質量(合成/照片級真實感)、場景多樣性以及直觀物理屬性的多樣性。具體而言,這些數據集的組合能夠探究對以下概念的理解:物體永恒性、連續性、形狀和顏色恒常性、重力、支持力、堅固性、慣性以及碰撞。
將V-JEPA與其他視頻模型進行比較,目的是研究視頻預測目標及表征空間對直觀物理理解的重要性。
此次考慮了兩類其他模型:視頻預測模型和多模態大型語言模型 (MLLM)。
- 視頻預測模型:直接在像素空間中進行預測,預訓練方法與V-JEPA在預測目標上相似,但通常學習到的表征空間的語義性較差 ,因此通常只有在針對特定任務微調后才具有實際應用。
- 多模態大語言模型:主要用于預測文本,并且在訓練過程中僅在事后與視頻數據結合,因此缺乏視頻預測的目標。
作為前者的代表性方法,作者評估VideoMAEv2。
盡管該模型使用了不同的預測目標和預訓練數據,但其預測空間的設置使得與V-JEPA進行比較成為可能。鑒于其預測性質,VideoMAEv2可像V-JEPA一樣,通過預測未來并通過預測誤差衡量驚訝程度來進行評估。
作為后者的典型的示例方法,作者研究了Qwen2-VL-7B和Gemini 1.5 Pro。
就參數數量和訓練數據量而言,這些模型都比V-JEPA大得多,并且它們主要從文本數據中學習。多模態大型語言模型,將視頻和可能的文本提示作為輸入,并學習生成相應的文本輸出。
由于MLLM只有文本輸出,因此無法使用基于定量驚訝度量去評估這些模型。
所以給模型一對視頻,詢問哪個視頻在物理上是不可能的, 如下所示。
|
|


對于每個方法,作者評估了原始研究中提出的旗艦模型。
進一步將全部模型與未訓練的神經網絡進行比較,以測試直覺物理理解的可學習性。對于每個屬性和模型,選擇的上下文大小要最大化性能,以便讓模型能夠適應不同的評估設置。
在3個直觀物理數據集IntPhys、GRASP和InfLevel上,使用違反預期范式,評估視頻模型。V-JEPA對不合理的視頻明顯更加「驚訝」,是唯一一個在所有數據集上表現出顯著優于未訓練網絡的性能的方法,在IntPhys、GRASP和InfLevel-lab數據集上分別達到了98%、66%和62%的平均準確率。
下圖總結了各方法在不同數據集上的對比分類性能(即,在一對視頻中檢測哪個是不可能的)。

更詳細的結果,參考下圖。
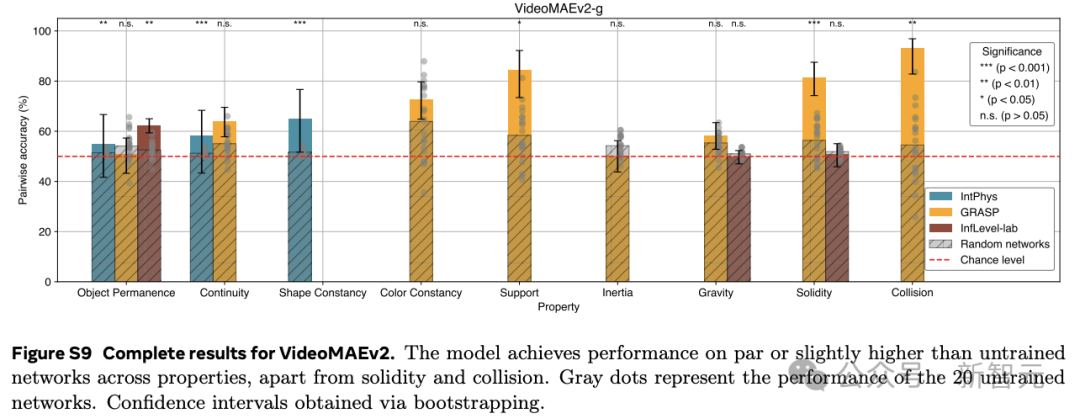
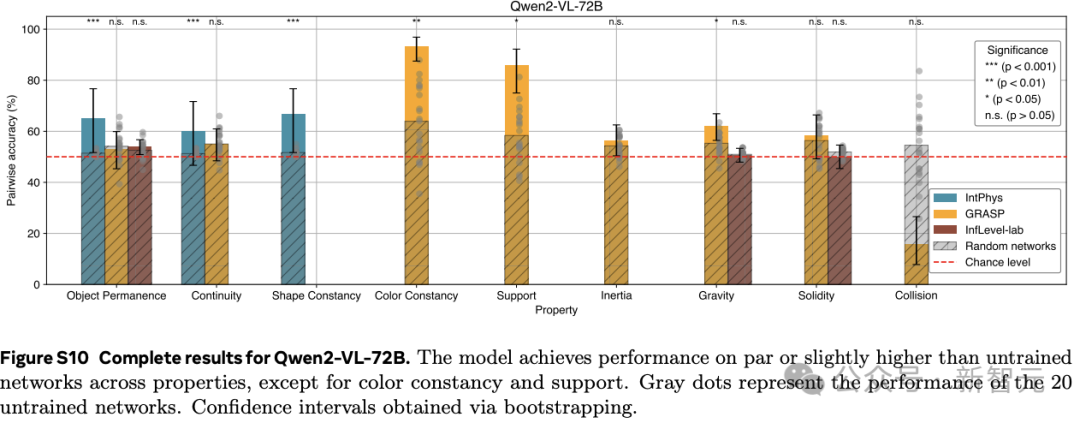
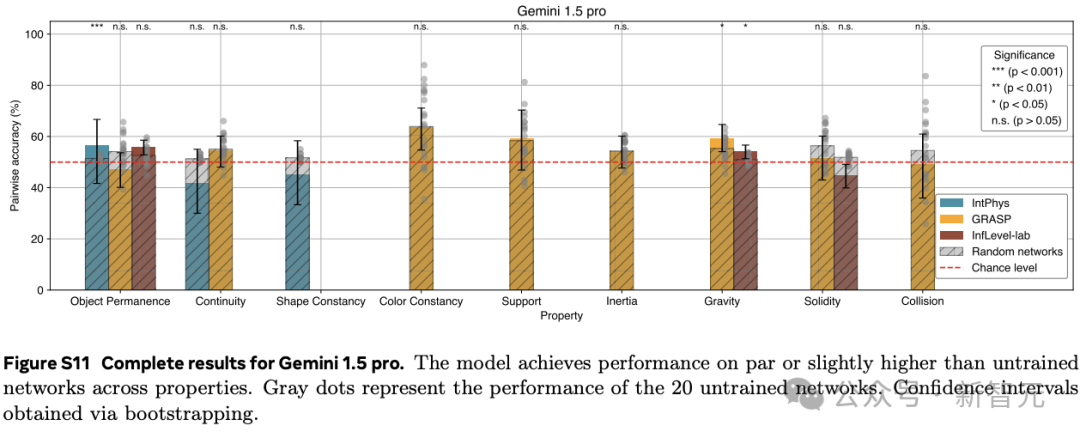
這些結果表明,在學習到的表示空間中,只做預測就足以發展出對直覺物理的理解。這個過程沒有依賴任何預定義的抽象概念,也沒有在預訓練或方法開發過程中使用基準知識。
而像素預測和多模態LLMs的低性能驗證了之前的發現。
這些比較進一步突顯了V-JEPA相對于現有的VideoMAEv2、Gemini 1.5 pro和Qwen2-VL-72B模型的優勢。
然而,這些結果并不意味著LLMs或像素預測模型無法實現直覺物理理解,而只是表明這一看似簡單的任務,對于前沿模型來說仍然困難。
V-JEPA深度剖析
為了解V-JEPA對不同直觀物理屬性的理解能力,研究者對其在各個數據集上的逐屬性性能進行了深入分析。
使用基于視覺Transformer-Large(ViT-L)架構的V-JEPA模型,在HowTo100M數據集上進行訓練。
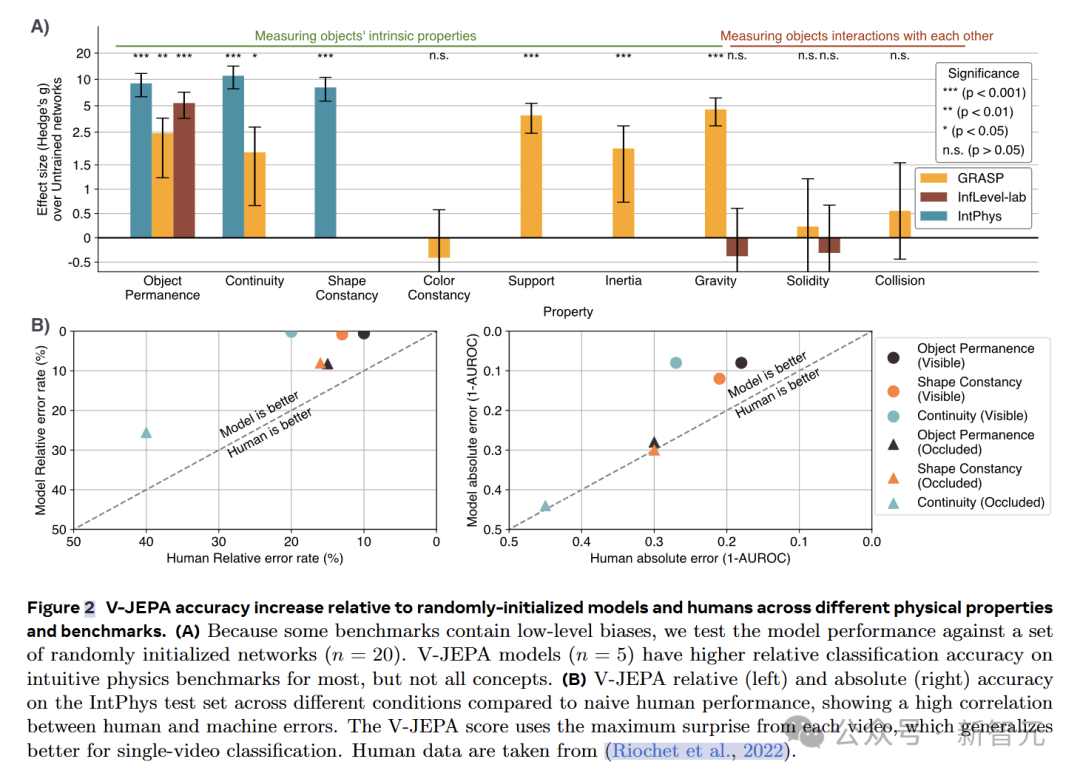
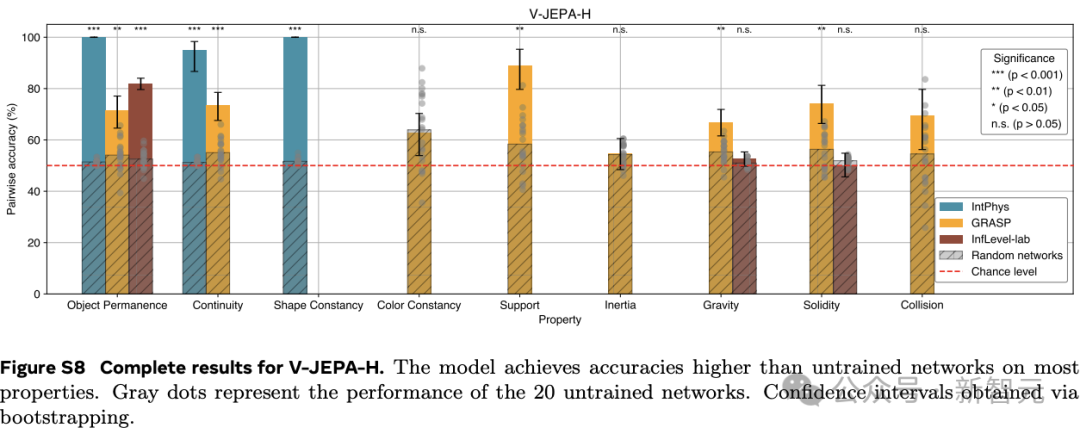
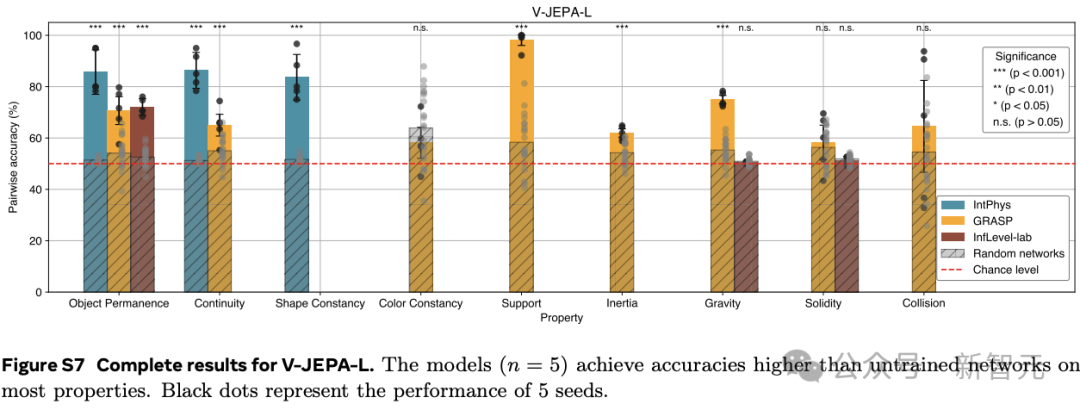
在IntPhys數據集上,V-JEPA在物體持久性、連續性和形狀恒定性等屬性上的表現遠超未訓練的網絡。
以物體持久性為例,V-JEPA的準確率達到了M=85.7,SD=7.6,而未訓練網絡的準確率僅為M=51.4,SD=1.0(t (4.0)=-8.9,p=4.19×10??),效應量g=9.0(95%置信區間 [6.3,11.7])差異非常顯著。
在GRASP數據集上,V-JEPA在物體持久性、連續性、支撐性、重力和慣性等屬性上的準確率同樣顯著高于未訓練網絡。然而,在顏色恒常性、堅固性或碰撞等屬性方面,并未觀察到顯著的提升。
在InfLevel數據集上,V-JEPA在物體持久性上的準確率有顯著提高,但在重力或堅固性方面則沒有明顯的優勢。
綜合來看,V-JEPA在與場景內容相關的屬性上表現出色,但在涉及需要理解上下文事件的類別或涉及精確物體交互建模,還存在一定的困難。
研究者推測,這些局限性主要來源于模型的幀率限制。
盡管如此,V-JEPA能從原始感知信號中學習必要的抽象概念,而無需依賴強先驗信息,展現出對直觀物理學的理解能力。這表明深度學習系統理解直觀物理概念并不一定需要核心知識。
研究人員還將V-JEPA與人類表現進行了對比,V-JEPA在所有直觀物理屬性上均達到或超過人類的表現。
在單個視頻分類任務中,使用視頻中的最大驚訝度而非平均值,能夠使V-JEPA的性能得到進一步提升。
對于物理違反事件發生在遮擋物后面的視頻,V-JEPA和人類的表現都會下降。在遮擋場景下,兩者的表現具有較高的相關性。
直觀物理學理解的關鍵
為了深入挖掘V-JEPA中直觀物理理解出現的內在機制,研究者進行了詳細的消融實驗,考察訓練數據、模型大小和預訓練預測任務這三個關鍵因素對直觀物理理解的影響。
預訓練任務的重要性
V-JEPA在訓練時采用的是塊掩蔽任務,即對視頻的整個持續時間內的一個大空間塊進行掩蔽,而在推理時則運用因果預測。
為了探究預訓練任務對直觀物理理解的具體影響,引入了兩種不同的替代方案:因果塊掩蔽和隨機掩蔽。
實驗結果顯示,預測任務對直觀物理理解的影響相對較小。盡管隨機掩蔽在視頻分類任務上會導致明顯的性能下降,但在IntPhys數據集上,其平均下降幅度僅約5分。
有趣的是,因果塊掩蔽雖然在測試時與模型的預測設置更為接近,但實際表現卻不如非因果塊掩蔽。
隨機掩蔽能夠取得一定的有效性能,這表明在抽象表征空間中進行預測才是關鍵所在,而不一定非要依賴特定的預訓練目標。
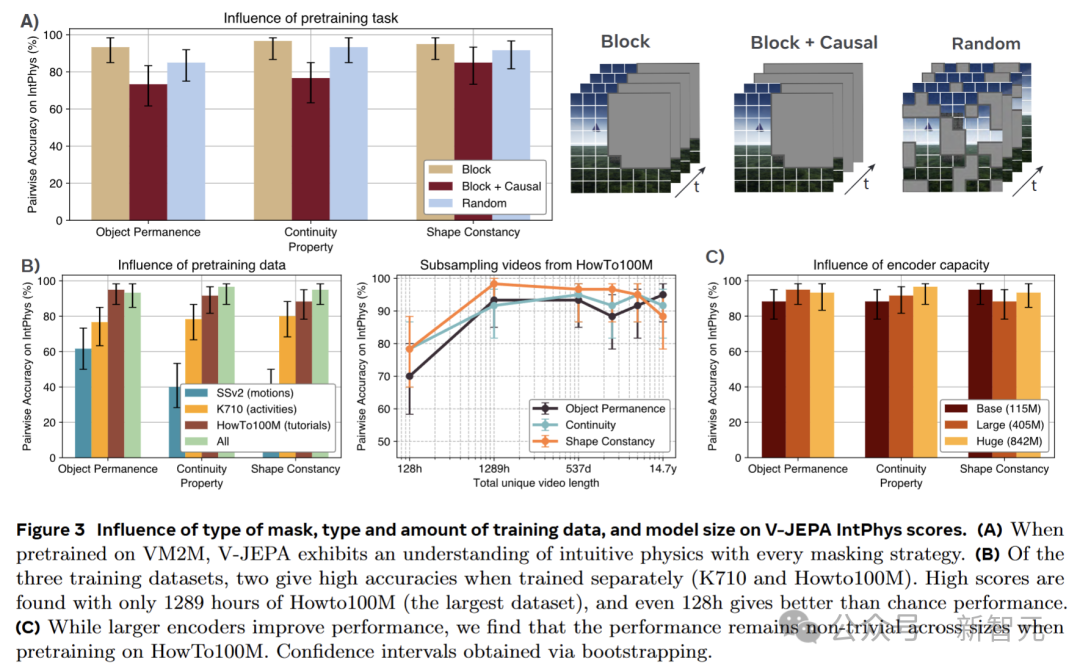
預訓練數據的關鍵作用
V-JEPA之前是在Kinetics 710、Something-Something-v2和HowTo100M三個數據集的混合(VideoMix2M)上進行訓練的。
為了研究預訓練數據對直觀物理性能的影響,分別使用這三個組件數據集重新訓練V-JEPA-L模型,并對HowTo100M進行子采樣,以探究數據集大小對模型性能的影響。
研究發現,數據源對模型性能有著顯著的影響。
僅使用基于運動理解的視頻(SSv2)進行訓練時,模型的性能接近隨機水平;側重于動作的數據(K710)能使模型獲得高于隨機水平的直觀物理理解能力;而教程視頻(HowTo)在單個組件數據集中展現出了最佳的性能。
通過對HowTo100M進行子采樣,進一步發現,即使使用僅占該數據集0.1%、僅代表128小時獨特視頻的小規模數據集,模型依然能有效地區分對直觀物理概念的違反情況,且在所有考慮的屬性上保持超過70%的成對準確率。
編碼器大小的影響
在深度學習領域,通常認為更大的模型具有更好的性能。
為了驗證這一觀點在V-JEPA模型中的適用性,團隊研究了V-JEPA在使用不同大小編碼器時的表現。
實驗結果表明,一般情況下,更大的模型確實表現更優。然而,一個參數僅有115M的小模型,仍然能夠達到超過85%的準確率。
這充分展示了V-JEPA模型對直觀物理理解的穩健性,即使是較小的模型也能實現對直觀物理的有效理解。