RAG(一)RAG開山之作:知識密集型NLP任務(wù)的“新范式”

在AI應(yīng)用爆發(fā)的時代,RAG(Retrieval-Augmented Generation,檢索增強(qiáng)生成)技術(shù)正逐漸成為AI 2.0時代的“殺手級”應(yīng)用。它通過將信息檢索與文本生成相結(jié)合,突破了傳統(tǒng)生成模型在知識覆蓋和回答準(zhǔn)確性上的瓶頸。不僅提升了模型的性能和可靠性,還降低了成本,增強(qiáng)了可解釋性。
今天來看一篇RAG領(lǐng)域的開山之作,2020年Meta AI發(fā)表在NIPS上的一篇工作。

先來看下研究動機(jī):大語言模型(LLM)雖然功能強(qiáng)大,但存在一些局限性,例如知識更新不及時、容易產(chǎn)生“幻覺”(即生成與事實不符的內(nèi)容),以及在特定領(lǐng)域或知識密集型任務(wù)中表現(xiàn)不佳。RAG通過引入外部知識庫,檢索相關(guān)信息來增強(qiáng)模型的輸出,從而解決這些問題。
1、方法介紹

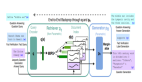
RAG模型結(jié)合了一個檢索器(retriever)和一個生成器(generator),這兩個組件協(xié)同工作來完成知識密集型的語言生成任務(wù)。
- 檢索器 (Retriever)
 :檢索器負(fù)責(zé)根據(jù)輸入序列x檢索文本文檔z。基于DPR(Dense Passage Retriever)構(gòu)建,使用預(yù)訓(xùn)練的查詢編碼器和文檔編碼器來計算查詢與文檔之間的相似度,并選擇最相關(guān)的前K個文檔。
:檢索器負(fù)責(zé)根據(jù)輸入序列x檢索文本文檔z。基于DPR(Dense Passage Retriever)構(gòu)建,使用預(yù)訓(xùn)練的查詢編碼器和文檔編碼器來計算查詢與文檔之間的相似度,并選擇最相關(guān)的前K個文檔。 - 生成器 (Generator)
 :生成器是一個預(yù)訓(xùn)練的序列模型(如BART-large),用于根據(jù)輸入序列x和檢索到的文檔z來生成目標(biāo)序列y。它通過將原始輸入與檢索到的內(nèi)容拼接起來作為新的上下文來進(jìn)行解碼。
:生成器是一個預(yù)訓(xùn)練的序列模型(如BART-large),用于根據(jù)輸入序列x和檢索到的文檔z來生成目標(biāo)序列y。它通過將原始輸入與檢索到的內(nèi)容拼接起來作為新的上下文來進(jìn)行解碼。 - 最大內(nèi)積搜索 (Maximum Inner Product Search, MIPS):通過計算查詢向量q(x)和所有文檔向量d(z)之間的內(nèi)積,找到與查詢最相關(guān)的前K個文檔z。
對于整個方法概括來說,用戶提供的文本查詢x 首先被送入查詢編碼器,得到查詢的向量表示q(x)。利用MIPS算法,在文檔索引中快速查找與查詢q(x)最相似的前K個文檔 。這些文檔作為潛在的知識來源,幫助生成更準(zhǔn)確的回答。最后,根據(jù)輸入序列x 和檢索到的文檔z 來生成目標(biāo)y。
。這些文檔作為潛在的知識來源,幫助生成更準(zhǔn)確的回答。最后,根據(jù)輸入序列x 和檢索到的文檔z 來生成目標(biāo)y。
RAG模型使用概率框架來處理檢索到的文檔作為潛在變量z,這篇文章提出兩種方式來邊緣化這些潛在文檔:
- RAG-Sequence Model:RAG-Sequence 模型使用單一的檢索文檔來生成完整的序列。具體來說,檢索器檢索出 top K 文檔,生成器為每個文檔生成輸出序列的概率
p(y∣x)p(y∣x)p(y ∣ x),然后對這些概率進(jìn)行邊緣化處理:

- RAG-Token Model:與此不同的是,RAG-Token允許每個輸出token依賴于不同的文檔。這意味著對于每一個token,模型都會重新評估一次所有可能的文檔,并據(jù)此調(diào)整生成的概率分布。
邊緣化的數(shù)學(xué)解釋
設(shè)輸入序列為 x,目標(biāo)序列為 y,檢索到的文檔集合為 Z。對于給定的輸入x 和目標(biāo)y,我們希望找到一個概率p(y∣x),即在給定輸入的情況下生成目標(biāo)序列的概率。然而,因為我們引入了額外的文檔信息z,所以我們實際上需要考慮的是條件概率p(y∣x,z)。
但是,z 是未知的,所以不能直接使用這個條件概率。為此,我們可以利用貝葉斯公式來將z 積分出去,從而得到不依賴于特定文檔的p(y∣x):

這里p(z∣x)表示給定查詢x 的情況下文檔z 被檢索出來的概率,這由檢索器給出;而p(y∣x,z)則是生成器基于輸入x 和文檔z 生成目標(biāo)y 的概率。通過遍歷所有可能的文檔 z 并加權(quán)求和它們各自的貢獻(xiàn),這樣就實現(xiàn)了對潛在文檔 z 的邊緣化。
檢索器:DPR
檢索組件 基于 DPR ,DPR 采用雙編碼器架構(gòu):
基于 DPR ,DPR 采用雙編碼器架構(gòu):

其中,d(z) 是文檔的密集表示,q(x) 是查詢表示。使用預(yù)訓(xùn)練的DPR來初始化檢索器,通過最大內(nèi)積搜索,計算具有最高先驗概率 的k個文檔列表,并構(gòu)建文檔索引,將文檔索引稱為非參數(shù)化記憶。
的k個文檔列表,并構(gòu)建文檔索引,將文檔索引稱為非參數(shù)化記憶。
生成器:BART
生成器組件 可以使用任何編碼器-解碼器模型來實現(xiàn),本文使用 BART-large,在生成時將輸入x 與檢索到的內(nèi)容z 簡單拼接。 BART 生成器的參數(shù)θ稱為參數(shù)化記憶。
可以使用任何編碼器-解碼器模型來實現(xiàn),本文使用 BART-large,在生成時將輸入x 與檢索到的內(nèi)容z 簡單拼接。 BART 生成器的參數(shù)θ稱為參數(shù)化記憶。
訓(xùn)練
模型采用了負(fù)對數(shù)似然損失函數(shù)訓(xùn)練,即最小化給定輸入x 下真實輸出 y 的負(fù)對數(shù)概率。在訓(xùn)練期間,不直接監(jiān)督應(yīng)該檢索哪些文檔,而是讓模型學(xué)習(xí)如何更好地利用檢索到的信息來提高生成質(zhì)量。此外,為了避免頻繁更新龐大的文檔索引帶來的高昂成本,只微調(diào)查詢編碼器和生成器。
解碼
測試時,RAG-Sequence 和 RAG-Token 需要不同的方法來近似 。 RAG-Token 模型可以看作是一個標(biāo)準(zhǔn)的自回歸 seq2seq 生成器,其轉(zhuǎn)移概率為:
。 RAG-Token 模型可以看作是一個標(biāo)準(zhǔn)的自回歸 seq2seq 生成器,其轉(zhuǎn)移概率為:

解碼可以通過插入修改后的轉(zhuǎn)移概率 進(jìn)入常規(guī)的束搜索算法完成。
進(jìn)入常規(guī)的束搜索算法完成。
對于RAG-Sequence,整個序列的似然
2、實驗結(jié)果
開放域問答
RAG-Token 和 RAG-Sequence 在所有四個任務(wù)上均達(dá)到了新的最先進(jìn)水平(僅在TriviaQA的一個特定測試集上除外)。

抽象問答
盡管沒有使用黃金段落,RAG的表現(xiàn)依然接近需要這些段落才能達(dá)到最優(yōu)表現(xiàn)的模型。
RAG 模型比 BART 更少產(chǎn)生幻覺,并且更頻繁地生成符合事實的文本。

Jeopardy 問題生成
表2 顯示了Q-BLEU-1度量的結(jié)果。表4展示了人工評估結(jié)果。表 3 顯示了每個模型的典型生成。
RAG-Token 模型特別擅長于從多個檢索到的文檔中提取信息并組合成復(fù)雜的Jeopardy問題。例如,在生成包含兩個不同書籍標(biāo)題的問題時,它能夠分別從不同的文檔中獲取每個書名的信息。
圖2 提供了一個具體的例子,展示了當(dāng)生成“太陽”一詞時,文檔2(提到《太陽照常升起》)的概率較高;而在生成“A Farewell to Arms”時,文檔1(提到海明威的這部作品)的概率較高。
隨著每個書名的第一個token被生成后,文檔概率分布趨于平坦化,這表明生成器能夠在不依賴特定文檔的情況下完成整個題目。
非參數(shù)化記憶的作用:通過檢索相關(guān)文檔,RAG模型可以引導(dǎo)生成過程,挖掘出存儲在參數(shù)化記憶中的具體知識。例如,即使只提供了部分解碼"The Sun",BART基線也能完成生成"The Sun Also Rises",說明這些信息已經(jīng)存儲在BART的參數(shù)中,但RAG能更好地利用外部知識源來增強(qiáng)生成質(zhì)量。


事實驗證
表2 顯示了FEVER任務(wù)上的分類準(zhǔn)確性。對于三類分類任務(wù)(支持/反駁/信息不足),RAG得分距離最先進(jìn)模型僅4.3%以內(nèi);對于二類分類任務(wù)(支持/反駁),差距更是縮小到2.7%以內(nèi)。
RAG能夠在不依賴檢索監(jiān)督信號的情況下,通過僅提供聲明并自己檢索證據(jù),實現(xiàn)與復(fù)雜管道系統(tǒng)相當(dāng)?shù)男阅堋?/span>
生成多樣性
RAG-Sequence 的生成更加多樣化,而RAG-Token次之,兩者都顯著優(yōu)于BART。

檢索機(jī)制的有效性
結(jié)果表明,學(xué)習(xí)檢索(即在訓(xùn)練過程中更新檢索器)對 RAG 模型的性能至關(guān)重要。密集檢索器在大多數(shù)任務(wù)中表現(xiàn)優(yōu)于傳統(tǒng)的 BM25 檢索器,尤其是在需要語義匹配和復(fù)雜查詢處理的任務(wù)中。對于某些特定任務(wù)(如 FEVER),基于詞重疊的 BM25 方法可能更為有效。

檢索更多文檔的效果

3、總結(jié)
RAG的意義簡單總結(jié)以下幾點:
- 提升模型性能:RAG顯著提高了生成模型在問答、文本生成等任務(wù)中的準(zhǔn)確性和可靠性。
- 降低訓(xùn)練成本:無需大規(guī)模預(yù)訓(xùn)練即可實現(xiàn)知識更新和性能提升。
- 增強(qiáng)可解釋性:通過檢索過程為生成結(jié)果提供明確依據(jù),增強(qiáng)了用戶對AI系統(tǒng)的信任。
- 推動行業(yè)創(chuàng)新:RAG技術(shù)在醫(yī)療、金融、法律等多個領(lǐng)域的應(yīng)用,推動了AI在特定領(lǐng)域的深度落地。
總的來說,RAG技術(shù)在AI應(yīng)用爆發(fā)的時代,憑借其對生成模型的增強(qiáng)和優(yōu)化,正在成為推動AI發(fā)展的關(guān)鍵力量。它不僅提升了模型的性能和可靠性,還降低了成本,增強(qiáng)了可解釋性。隨著技術(shù)的不斷演進(jìn),RAG將在更多領(lǐng)域?qū)崿F(xiàn)深度應(yīng)用,為AI的未來發(fā)展提供強(qiáng)大動力。