HippoRAG:基于海馬體記憶索引理論的知識密集型任務新突破

在自然語言處理領域,大語言模型(LLMs)已經取得了令人矚目的成就。然而,當面對知識密集型任務時,例如科學文獻綜述、法律案件簡報或醫療診斷,這些模型往往顯得力不從心。它們難以有效地整合新的或特定領域的知識,而現有的檢索增強生成(RAG)方法也因無法滿足復雜的跨段落或文檔的知識整合需求而受到限制。
為了解決這一問題,研究人員提出了 HippoRAG,這是一種受到海馬體記憶索引理論啟發的檢索增強生成方法,旨在增強語言模型處理知識密集型任務的能力,并優化信息檢索過程。
論文地址:https://arxiv.org/abs/2405.14831

1、海馬體記憶索引理論
海馬體記憶索引理論是描述人類長期記憶的一個成熟理論,由 Teyler 和 Discenna 提出。該理論解釋了人腦中負責長期記憶的不同組件和電路如何協同工作,以完成兩個主要目標:模式分離和模式完成。
海馬記憶索引理論是一個描述人類長期記憶的成熟理論,由 Teyler 和 Discenna提出,解釋了人腦中負責長期記憶的不同組件和電路如何協同工作以完成兩個主要目標:模式分離(pattern separation)和模式完成(pattern completion)。
- 模式分離:在記憶編碼過程中,新皮層接收和處理感知刺激,將其轉換為高級特征,然后傳遞到海馬體進行索引。海馬體中的顯著信號被納入索引,并相互關聯。這一過程確保了不同感知體驗的記憶表示是唯一的。
- 模式完成:在記憶檢索過程中,海馬體接收到部分感知信號后,利用其基于上下文的記憶系統識別索引中的完整且相關記憶,并將其回傳到新皮層進行模擬。即使提供的線索并不完整或精確,海馬體中的索引也能幫助定位相關的記憶條目。
海馬體在這個過程中扮演著關鍵角色。在記憶編碼階段,它接收來自新皮層的感知信息,并將顯著的信息信號加入索引;在記憶檢索階段,它通過索引觸發模式完成的過程,從而實現從部分提示恢復完整記憶的能力。
2、HippoRAG
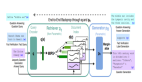
HippoRAG 的設計靈感來源于海馬體記憶索引理論,它模擬了人類大腦中模式分離和模式完成的過程,以更高效地處理需要復雜推理或大量背景知識的任務。

離線索引:構建知識圖譜
- 使用 LLM 進行開放信息提取(OpenIE):在離線索引階段,HippoRAG 利用指令調優的大語言模型(如 GPT-3.5 或 Llama-3.1)作為“人工新皮質”,從檢索語料庫中提取知識圖譜(KG)三元組。以開放信息抽取的方式,將文檔中的關鍵信息(如命名實體和關系)以離散的名詞短語形式提取出來,而不是采用密集的向量表示。這種方式實現了更精細的模式分離,使得 HippoRAG 能夠更有效地處理長文本和復雜關系。
- 構建無模式的知識圖譜:將 OpenIE 提取的三元組存儲在無模式的知識圖譜中。該圖譜包含實體節點、關系邊和同義詞邊。同義詞邊連接相似但不同的名詞短語,幫助 HippoRAG 在在線檢索階段更好地理解查詢。
- 使用檢索編碼器進行索引:使用預先訓練好的密集編碼器(如 ColBERTv2)為知識圖譜中的節點生成密集表示。這不僅有助于識別和添加同義詞邊,還能連接原本孤立但語義相似的節點,從而提高知識圖譜的連通性。
在線檢索:高效的知識整合
- 使用 LLM 進行命名實體識別(NER):在在線檢索階段,HippoRAG 模仿人腦的記憶檢索過程,使用 LLM 從查詢中提取命名實體。這些實體成為 HippoRAG 在知識圖譜中進行檢索的起點。
- 選擇查詢節點:使用檢索編碼器將查詢中的實體編碼成密集表示,并與知識圖譜中的節點表示進行相似度計算,選擇最相似的節點作為查詢節點。這些節點代表了與查詢相關的實體,并作為 HippoRAG 進行多跳推理的起點。
- 使用個性化 PageRank 進行檢索:一旦確定了查詢節點,HippoRAG 就可以開始執行模式完成的過程,這類似于人類記憶從部分提示恢復完整記憶的能力。具體來說,HippoRAG 采用個性化 PageRank(PPR)算法在知識圖譜上運行,以找到與查詢最相關的節點及其鄰域。根據選定的查詢節點,HippoRAG 設置 PPR 的個性化概率分布,其中查詢節點的概率設置為 1,其他節點的概率設置為 0。這意味著初始概率只集中在那些與查詢直接相關的節點上。隨著 PPR 算法的迭代,概率會沿著知識圖譜中的邊傳遞給其他節點。由于邊權重反映了節點間的關聯強度,因此更緊密相連的節點會獲得更高的概率值。除了直接關聯的節點外,PPR 還能夠探索幾跳之外的節點,從而捕捉到更廣泛的上下文信息。這種單步多跳檢索的能力使得 HippoRAG 在處理復雜問題時表現出色。
- 計算文檔得分并進行檢索:經過 PPR 算法后,HippoRAG 獲得了每個節點的概率得分,這些得分指示了節點與查詢的相關性。然后,系統將這些節點概率聚合回原始文檔,為每個文檔計算一個綜合得分,用于最終的段落排名。對于出現在多個文檔中的相同節點,HippoRAG 會將它們的概率得分累加到對應的文檔上,形成段落級別的評分。根據段落評分,HippoRAG 對所有候選文檔進行排序,挑選出最有可能包含正確答案的前幾個段落作為回答來源。
生成答案:自然語言生成與信息整合
最后,HippoRAG 利用檢索到的相關段落和知識圖譜結構,結合生成器模塊生成最終的答案。生成器可以根據提供的上下文生成自然語言的回答,確保答案不僅準確而且易于理解。這一過程可能涉及模板填充、文本摘要或其他形式的語言生成技術。如果一個問題需要整合來自不同段落的信息,生成器會巧妙地將這些片段組合成一個連貫的回答。
3、單步多跳高效解決復雜查詢
單步多跳是一種在信息檢索和問答系統中用于解決復雜查詢的技術,尤其是在需要跨多個文檔或段落進行推理的多跳問答(Multi-Hop QA)任務中。與傳統的多步多跳方法不同,單步多跳能夠在一次檢索操作中完成多跳推理,而不需要多次迭代檢索和生成步驟。
多跳問答的背景
多跳問答任務要求系統能夠通過多個文檔或段落中的信息進行推理,以回答復雜的問題。例如,問題可能是:“哪位斯坦福大學的教授研究阿爾茨海默病?”要回答這個問題,系統需要首先找到斯坦福大學的教授列表,然后找到研究阿爾茨海默病的教授,最后將這兩個信息結合起來找到答案。
傳統的多跳問答系統通常采用多步檢索的方法,即系統首先檢索與問題相關的第一個文檔,然后根據第一個文檔中的信息生成新的查詢,再進行第二次檢索,依此類推,直到找到所有必要的信息。這種方法雖然有效,但存在以下問題:
- 效率低:每次檢索都需要生成新的查詢并進行檢索,增加了計算成本和時間。
- 誤差累積:每一步的檢索和生成都可能引入誤差,導致最終答案不準確。
單步多跳的核心思想
單步多跳的核心思想是通過一次檢索操作完成多跳推理,而不需要多次迭代。具體來說,系統通過構建一個知識圖譜(KG)或類似的圖結構,將文檔中的實體和關系表示為圖中的節點和邊。當用戶提出一個多跳問題時,系統通過圖搜索算法(如個性化 PageRank,PPR)在圖中找到與查詢相關的節點和路徑,從而一次性檢索到所有必要的信息。
4、實驗結果
為了驗證 HippoRAG 的性能,研究人員在多個數據集上進行了實驗,包括 MuSiQue、2WikiMultiHopQA 和 HotpotQA。這些數據集涵蓋了多跳問答任務的不同場景,能夠全面評估 HippoRAG 的檢索和問答能力。

單步檢索結果
HippoRAG 在 MuSiQue 和 2WikiMultiHopQA 數據集超越其他方法,在 2WikiMultiHopQA 數據集上,R@2 和 R@5 提升顯著。在 HotpotQA 數據集上,HippoRAG 的性能與 ColBERTv2 相當。作者認為,2WikiMultiHopQA 的實體中心設計特別適合 HippoRAG,而 HotpotQA 的性能較低主要是因為其對知識整合的要求較低,以及概念-上下文權衡的問題。

多步檢索結果
IRCoT(Iterative Retrieval with Contextualized Objectives and Training)是一種迭代檢索方法,旨在通過多輪次的檢索過程來逐步精煉和聚焦于最相關的文檔或段落,以提高信息檢索和問答系統的準確性。實驗結果表明,IRCoT 和 HippoRAG 是互補的。

問答結果
實驗表明,HippoRAG 的檢索改進直接轉化為了更好的問答性能。特別是在依賴復雜推理和多源信息整合的問題上,HippoRAG 提供的支持使得生成的回答更加準確和詳盡。

消融實驗
OpenIE替代方案:通過測試使用不同OpenIE模型(如REBEL和Llama-3.1)對HippoRAG性能的影響。結果表明,GPT-3.5在生成知識圖譜(KG)時表現最佳,尤其是在生成三元組數量上遠超REBEL。Llama-3.1-70B在某些數據集上表現與GPT-3.5相當,甚至更好,表明開源模型可以作為低成本替代方案。
PPR替代方案:通過比較PPR算法與其他簡單的圖搜索方法,發現PPR在檢索關聯信息時更為有效,尤其是在多跳推理任務中。
消融實驗:通過消融實驗,發現節點特異性(Node Specificity)和同義詞邊(Synonymy Edges)對檢索性能有顯著影響。節點特異性在MuSiQue和HotpotQA數據集上表現較好,而同義詞邊在2WikiMultiHopQA數據集上效果顯著。

單步多跳檢索:HippoRAG的一個主要優勢是能夠在單步檢索中完成多跳推理任務,而傳統RAG方法需要多次迭代。實驗表明,HippoRAG在檢索所有支持文檔的成功率上顯著優于其他方法,尤其是在2WikiMultiHopQA數據集上,HippoRAG的改進幅度更大。

路徑發現多跳問題:HippoRAG在處理路徑發現多跳問題時表現出色,這類問題需要在不同段落之間找到相關實體,而傳統方法難以解決。HippoRAG通過其關聯圖和圖搜索算法,能夠有效識別相關實體并檢索出正確的段落。

5、總結
從實驗結果來看,HippoRAG 確實在知識密集型任務的處理上展現出獨特優勢。盡管文中提到未與 GraphRAG、GraphReader 等對比,且 QA 問答評估表現不如 GraphReader,并且從HippoRAG的方法細節中,可以了解到,HippoRAG對于信息的提取和表示相對粗糙,也是未來可以優化的地方。
在眾多引入 graph 的方法中,HippoRAG 引入海馬體記憶索引理論,無疑是故事講的最好的一個。其實,無論哪種方法,最重要的是實用性、工程性,期待各個方法的落地。