在長文本上比Flash Attention快10倍!清華等提出APB序列并行推理框架
在 ChatGPT 爆火兩年多的時間里,大語言模型的上下文窗口長度基準線被拉升,以此為基礎所構建的長 CoT 推理、多 Agent 協作等類型的高級應用也逐漸增多。
隨之而來的是,長文本推理速度被提出更高要求,而基于現有 Transformer 架構的模型受限于注意力機制的二次方復雜度,難以在較短時延內處理超長文本請求。
針對這一痛點,清華大學 NLP 實驗室聯手中南大學、北京郵電大學以及騰訊微信 AI 實驗室取得了突破,共同提出了 APB 框架 —— 其核心是一個整合了稀疏注意力機制的序列并行推理框架,通過整合局部 KV 緩存壓縮方式以及精簡的跨 GPU 通信機制,解決了長上下文遠距離語義依賴問題,在無性能損失的前提下大幅度提升超長文本預填充的效率。
在 128K 文本上,APB 能夠出色地平衡性能與速度,達到相較于傳統 Flash Attention 約 10 倍的加速比,在多種任務上甚至具有超越完整 Attention 計算的性能;與英偉達提出的同為分布式設定下的 Star Attention 相比,APB 也能達到 1.6 倍加速比,在性能、速度以及整體計算量上均優于 Star Attention。

- 論文鏈接:https://arxiv.org/pdf/2502.12085
- GitHub 鏈接:https://github.com/thunlp/APB
這一方法主要用于降低處理長文本請求的首 token 響應時間。未來,APB 有潛力運用在具有低首 token 響應時間要求的模型服務上,實現大模型服務層對長文本請求的高效處理。
瓶頸:加速長文本預填充效率
長文本預填充的效率受到計算的制約。由于注意力機制的計算量與序列長度呈二次方關系,長文本的計算通常是計算瓶頸的。主流加速長文本預填充的路線有兩種,提升并行度和減少計算:
- 提升并行度:我們可以將注意力機制的計算分布在不同設備上來提升并行度。當一個 GPU 的算力被充分的利用時,簡單的增加 GPU 的數量就可以增加有效算力。現存研究中有各種各樣的并行策略,包括張量并行、模型并行、序列并行等。對于長文本推理優化,序列并行有很大的優化潛力,因為它不受模型架構的制約,具有很好的可擴展性。
- 減少計算:另一個加速長文本預填充的方式是減少計算,即使用稀疏注意力。我們可以選擇注意力矩陣中計算的位置,并不計算其他位置來減少整體的計算量。此類方法通常會帶來一定的性能損失。計算時忽略重要的上下文會導致無法處理某些任務。
然而,簡單地提升并行度和減少計算并不能在加速長文本預填充上取得足夠的效果。若要將二者結合又具有極大挑戰,這是因為稀疏注意力機制中,決定計算何處注意力通常需要完整輸入序列的信息。在序列并行框架中,每個 GPU 僅持有部分 KV 緩存,無法在不通過大規模通信的前提下獲得足夠的全局信息來壓縮注意力的計算。
針對這一問題,有兩個先驅方法:一是英偉達提出的 Star Attention ,直接去除了序列并行中的所有通信,并只計算每個 GPU 上局部上下文的注意力,但這樣計算也導致了很大程度的性能損失;二是卡內基梅隆大學提出的 APE,關注 RAG 場景下長文本預填充加速,通過將上下文均勻分割、對注意力進行放縮和調整 softmax 溫度,實現并行編碼,同樣在需要遠距離依賴的場景上有一定的性能損失。
區別于上述方法,APB 通過設計面向序列并行場景的低通信稀疏注意力機制,構建了一個更快、性能更好,且適配通用長文本任務的長文本加速方法。
APB:面相序列并行框架的稀疏注意力機制
相較于之前的研究,APB 通過如下方法提出了一種面相序列并行框架的稀疏注意力機制:

- 增加較小的 Anchor block:Star Attention 中引入的 Anchor block(輸入序列開始的若干 token)能夠極大恢復性能,然而其尺寸需要和局部上下文塊一樣大。過大的 anchor block 會在 FFN 中引入過多的額外開銷。APB 通過減少 anchor block 的大小,使其和上下文塊的 1/4 或 1/8 一樣大。
- 解決長距離語義依賴問題:先前研究某些任務上性能下降的原因是它們無法處理長距離語義依賴,后序 GPU 分塊無法看到前序上下文塊中的信息,導致無法處理特定任務。APB 通過構建 passing block 的方式來解決這一問題。Passing block 由前面設備上的重要 KV 對組成。每個上下文塊先被壓縮,然后將被壓縮的上下文塊通信到后續 GPU 上來構建 passing block。
- 壓縮上下文塊:在不進行大規模通信的前提下,每個設備只對自己持有的上下文有訪問權限。因此,現存的 KV Cache 壓縮算法(例如 H2O 和 SnapKV)不適用于這一場景,因為它們依賴全序列的信息。然而,該特點與 Locret 一致,KV Cache 重要性分數僅僅與對應 KV 對的 Q, K, V 相關。APB 使用 Locret 中引入的 retaining heads 作為上下文壓縮器。
- 查詢感知的上下文壓縮:APB 在 anchor block 的開頭嵌入查詢。當預填充結束時,這些查詢可以隨著 anchor block 一同被丟棄,不會影響整體計算的同時還能讓上下文壓縮器看到查詢的內容。通過這種方式,保留頭能夠更精準地識別出查詢相關的 KV 對,并通過通信機制傳給后續設備。
以此機制為基礎,APB 的推理過程如下:
- 上下文分割:長文本被均勻的分到每個設備上,開頭拼接一個 anchor block,其中包含了查詢問題。
- 上下文壓縮:我們用 Locret 引入的保留頭來壓縮 KV Cache。
- 通信:我們對壓縮過的 KV Cache 施加一個 AllGather 算子。每個設備會拿到前序設備傳來的壓縮緩存,并構建 passing block。
- 計算:我們使用一個特殊的 Flash Attention Kernel 來實現這個特殊的注意力機制。我們更改了注意力掩碼的形狀。Passing block 在注意力計算結束后就被刪除,不參與后續計算。
APB 實現更快、性能更好的長文本推理
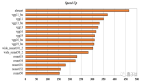
團隊使用 Llama-3.1-8B-instruct, Qwen-2.5-14B-instruct 以及 Yi-34B-200K 模型在 InfiniteBench 和 RULER 上進行了測試,測量任務性能(%)以及處理完整長文本請求的推理速度(tok /s)。研究人員選擇 Flash Attention, Ulysses, Ring Attention, MInference 以及 Star Attention 作為基線算法,實驗結果如下:

從上圖可見,Flash Attention 作為無序列并行的精準注意力算法,具有較好的任務性能,但推理速度最慢;Ring Attention 和 Ulysses 作為序列并行的精準注意力算法,通過增加并行度的方式提升了推理速度;MInference 是一種無序列并行的稀疏注意力機制,表現出了一定的性能損失;Star Attention 作為序列并行與稀疏注意力結合的最初嘗試,具有較好的推理速度,然而表現出了顯著的性能下降。
相較于基線算法,APB 在多種模型和任務上表現出更優的性能和更快的推理速度。這意味著,APB 方法能夠實現最好的任務性能與推理速度的均衡。
除此之外,研究人員在不同長度的數據上測量了 APB 與基線算法的性能、速度,并給出了整體計算量,結果如下:

可以從上圖中看到,APB 在各種輸入長度下均表現出更優的任務性能與推理速度。速度優勢隨著輸入序列變長而變得更加明顯。APB 相較于其他方法更快的原因是它需要更少的計算,且計算量差異隨著序列變長而加大。
并且,研究人員還對 APB 及基線算法進行了預填充時間拆解分析,發現序列并行可以大幅度縮減注意力和 FFN 時間。

通過稀疏注意力機制,APB 能進一步縮減注意力時間。Star Attention 由于使用了過大的 anchor block,其 FFN 的額外開銷十分明顯,而 APB 由于使用了 passing block 來傳遞遠距離語義依賴,能夠大幅度縮小 anchor block 大小,從而降低 FFN 處的額外開銷。
APB 支持具有卓越的兼容性,能適應不同分布式設定(顯卡數目)以及不同模型大小,在多種模型和分布式設定下均在性能與推理速度上取得了優異的效果。
核心作者簡介
黃宇翔,清華大學四年級本科生,THUNLP 實驗室 2025 年準入學博士生,導師為劉知遠副教授。曾參與過 MiniCPM、模型高效微調、以及投機采樣研究項目。主要研究興趣集中在構建高效的大模型推理系統,關注模型壓縮、投機采樣、長文本稀疏等推理加速技術。

李明業,中南大學三年級本科生,2024 年 6 月份加入 THUNLP 實驗室實習,參與過投機采樣研究項目。主要研究興趣集中在大模型的推理加速,例如投機采樣以及長文本推理加速等。