2025防失業預警:不會用DeepSeek-RAG建知識庫的人正在被淘汰
1. 前言
前幾天,老板和我們開了個會,提到一個讓人深思的事情:越來越多的客戶開始詢問,能不能把DeepSeek接入他們的系統,幫助他們管理數據、合同和一些文件。那一刻,我突然意識到,AI技術已經不僅僅是個高大上的話題,它正在切實改變著我們工作和生活的方式。
客戶的需求很簡單,但背后卻透露著一個深刻的問題——他們希望通過AI來提高效率、減少錯誤。對于很多傳統企業來說,信息的混亂和管理的漏洞已經成為不可忽視的痛點。想象一下,如果這些企業能夠通過DeepSeek-RAG技術,構建一個強大的知識庫來幫助他們自動化處理這些信息,那么工作效率和決策質量將會有多大提升。
我開始意識到,知識庫的構建正在成為未來競爭力的一部分。尤其是在AI幻覺頻發的今天,單純依賴模型生成的內容是有風險的,而通過精準的知識庫來輔助AI工作,能夠有效避免錯誤的發生。也正是因此,我決定寫這篇文章,分享如何基于AnythingLLM構建DeepSeek-RAG本地知識庫,并幫助傳統企業從中受益。掌握這種技術,將不僅僅是提升工作效率,更是走在未來職場前沿的關鍵。
2. 本地知識庫與檢索增強生成(RAG)技術前置知識
2.1. 什么是AI幻覺
隨著人工智能技術的飛速發展,越來越多的企業和個人將AI作為決策支持的核心工具。然而,這種過度依賴和迷信AI的現象,實際上可能帶來一些嚴重的問題——那就是AI幻覺。簡單來說,AI幻覺指的是人工智能在生成內容時,出現了與事實不符、邏輯斷裂或脫離上下文的情況。AI模型雖然能生成看似可信的答案,但其背后的推理和依據可能是錯誤的。
這一問題不僅僅存在于專業領域,許多人在日常生活中也會因過度信任AI而無意間陷入幻覺中。

AI幻覺主要有兩種形式:事實性幻覺和忠實性幻覺。事實性幻覺是指AI生成的內容與實際世界的事實不一致,例如錯誤的歷史事件或科學數據;而忠實性幻覺則指的是AI的回答雖然在事實上沒有錯,但與用戶的真實意圖或問題的上下文不符。

那么,為什么AI會產生幻覺呢?首先,AI模型依賴于訓練數據,這些數據可能存在偏差或錯誤,導致AI在生成內容時不符合實際情況。其次,當AI遇到未知的復雜情境時,它可能會出現泛化問題,無法有效處理超出訓練數據范圍的內容。再者,由于大多數AI模型缺乏自我更新和實時學習的能力,它們會在面對新信息時產生過時的回答。
隨著AI技術的普及,越來越多的人和企業開始盲目依賴AI做出決策,而忽視了AI潛在的幻覺問題。這種過度迷信AI的行為,不僅會導致錯誤的判斷,還可能在不知不覺中影響我們的生活和工作。認識到AI幻覺的存在,并采取措施應對,將是我們在AI時代避免被誤導的關鍵。
2.2. 防止AI幻覺的措施
為了降低生成式人工智能中的幻覺風險,可以采取以下措施:
1. 模型微調
- 優點:
a.定制化效果明顯:針對特定領域或任務進行優化,使模型更符合專業需求,生成內容更精準。
b.知識更新:通過微調引入最新數據,彌補預訓練數據的滯后性。
c.減少偏差:有助于降低模型在非目標領域生成不相關或錯誤內容的概率。
- 缺點:
a.成本高昂:微調需要大量高質量數據和計算資源,投入成本較高。
b.過擬合風險:針對特定領域過度優化可能導致模型在其他場景下表現不佳。
c.數據隱私問題:敏感領域數據的使用可能引發隱私和安全風險,需要嚴格的數據治理。
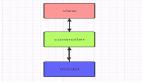
2. 構建本地知識庫與檢索增強生成(RAG)技術
- 優點:
a.權威性保障:利用權威數據源構建知識庫,可為生成內容提供可靠支撐。
b.動態更新:RAG技術允許模型在生成回答前檢索最新數據,改善知識時效性。
c.降低幻覺風險:通過引用準確信息,減少模型憑空生成不實內容的可能。
- 缺點:
a.構建與維護成本:高質量知識庫的建立和更新需要投入大量人力和技術資源。
b.技術整合挑戰:如何無縫將知識庫檢索結果與生成模型結合,依然存在一定技術難度。
c.數據一致性問題:知識庫數據更新不及時或數據來源不一致可能影響回答的準確性。
3. 限制模型響應范圍
- 優點:
a.風險控制:通過設定概率閾值和規則,能有效過濾不相關或錯誤信息,降低幻覺風險。
b.輸出一致性:確保模型在規定范圍內生成符合預期的內容,提升回答質量。
- 缺點:
a.創新性受限:過于嚴格的限制可能削弱模型的創造性和靈活性,影響輸出多樣性。
b.參數調優復雜:需要精細調整參數以達到平衡,過度限制可能使回答顯得模板化或過于簡單。
4. 持續測試與優化
- 優點:
a.實時問題發現:定期評估和測試能及時捕捉模型在實際應用中的缺陷和幻覺風險。
b.系統穩定性提升:不斷優化迭代有助于模型適應變化的數據環境和需求,保持長期穩定性。
- 缺點:
a.資源投入大:持續監控和優化需要投入大量人力和時間資源。
b.測試覆蓋局限:如果測試場景不夠全面,可能仍有部分風險未被及時發現。
綜上所述,為了有效降低AI幻覺風險,通常需要將多種措施結合使用。在實際應用中,構建本地知識庫與檢索增強生成(RAG)技術是一種有效的方案。
2.3. 什么是Embedding
Embedding是將文本轉化為固定維度數值向量的技術,這些向量能夠幫助AI模型理解和處理文本數據。通過Embedding,AI能夠計算文本之間的語義相似度,從而提升搜索、問答等任務的準確性。在構建知識庫時,Embedding技術可以將文件和數據轉化為向量,使得知識庫能夠更智能地匹配和檢索相關信息。常見的Embedding方法包括Word2Vec、GloVe、BERT等,這些方法在實際應用中可以幫助改善語義理解和信息處理的效率(Embedding我會在后續文章細講,本文里只是讓大家有個了解,感興趣的朋友可以點點關注,后續會更新相關內容)。
3. 基于 AnythingLLM構建DeepSeek-RAG本地知識庫
3.1. 安裝AnythingLLM前置準備
3.1.1 什么是Ollama
Ollama 是一個讓用戶可以在本地計算機上運行 AI 語言模型的工具,省去了連接云端和復雜配置的麻煩。它的優點包括:
- 簡單易用:安裝 Ollama 后,可以輕松在本地運行 AI 模型,無需額外的配置。
- 離線使用:即使沒有互聯網連接,也能使用 AI,確保了數據隱私的安全性。
- 兼容多種操作系統:支持 Windows、Mac 和 Linux 系統。
- 支持多種 AI 模型:可以下載并運行多種不同的 AI 語言模型,如通義千問、騰訊混元、DeepSeek 等等。
- 適用于開發者和普通用戶:開發者可以利用它進行模型訓練或微調,而普通用戶也可以用它來聊天、寫作、翻譯等。
3.1.2. Ollama 安裝及配置
3.1.2.1. 下載Ollama
訪問官網:Ollama.com,頁面應顯示一個羊駝??,如果不是,說明你進入了錯誤的頁面。然后,點擊頁面下方的【下載】按鈕。

選擇適配你系統的版本,進行下載:

點擊【Install】進行安裝。

3.1.2.2. 配置Ollama環境變量
有一個點要注意一下,Ollama 下載模型的默認位置是在 C 盤,在下載模型之前,我們需要更改磁盤位置,步驟如下:
在【我的電腦】處點擊鼠標右鍵彈出菜單,選擇【屬性】,進入設置界面后選擇【高級系統設置】:

在彈出的系統屬性彈窗中點擊【環境變量】:

在【系統變量】區域點擊【新建】按鈕,在變量名處輸入OLLAMA_MODELS,點擊【瀏覽目錄】,選擇模型存放位置:

設置完成以后記得保存環境變量配置(很重要)。
需要注意的是剛剛我們下載的Ollama 程序也是放在C盤的,C盤空間容易爆滿,這里我們還需要再操作異步,把Ollama 全部文件夾遷移到一個空間大一些的盤(我選的F盤),如果你C盤空間很多,可以直接跳到下一節。
在F盤新建Ollama文件夾,新建exe、logs、models三個文件夾:

然后去默認安裝文件夾把里面的內容都復制到剛剛創建的文件夾里面,默認安裝文件夾如下:
C:\Users\用戶名\.ollama ------------------------存放大模型
C:\Users\用戶名\AppData\Local\Ollama------------------------存放日志
C:\Users\用戶名\AppData\Local\Programs\Ollama------------------------存Ollama程序將文件夾里面的內容搬走,刪掉 C 盤他們原來的文件夾,打開命令提示符,輸入:
mklink /D C:\users\用戶名.ollama F:\Ollama\models
mklink /D C:\users\用戶名\AppData\Local\Ollama F:\Ollama\logs
mklink /D C:\users\用戶名\AppData\Local\Programs\Ollama F:\Ollama\exe上述命令旨在通過創建軟鏈接,將原本需要位于 C 盤的文件夾重定向到 F 盤,以滿足某些腳本必須在 C 盤運行的要求,同時避免占用 C 盤空間。具體操作如下:
- 將
C:\users\用戶名.ollama重定向到F:\Ollama\models。 - 將
C:\users\用戶名\AppData\Local\Ollama重定向到F:\Ollama\logs。 - 將
C:\users\用戶名\AppData\Local\Programs\Ollama重定向到F:\Ollama\exe。
通過這些操作,用戶可以在 F 盤上訪問 Ollama 相關的文件和程序,同時滿足腳本對 C 盤路徑的要求。
如果提示沒有權限,就以管理員的身份運行:

操作完成以后回到原始放置Ollama文件的C盤對應目錄看一下,變成下圖這樣,軟連接就創建好了:

最后一步,檢查Ollama是否安裝成功,命令提示符窗口輸入ollama -v,如下圖所示就是安裝成功了:

3.1.2.3. 下載模型
下載大模型打開 Ollama 官網 https://ollama.com/ ,點擊的【Models】,選擇合適你的模型進行下載(我選擇的是1.5b),如果你不知道你的電腦可以下載什么規格的模型可以去看一下我這篇文章的第三章:DeepSpeek服務器繁忙?這幾種替代方案幫你流暢使用!(附本地部署教程)

將模型拉取命令復制到命令提示符窗口中,按回車鍵,出現Send a meesage即為下載成功:

到這一步我們就能直接使用了:

在Send a meesage處輸入/?就可以獲得操作幫助:

輸入/bye可以退出:

如果想重新對話,還是輸入ollama run deepseek-r1:1.5b:

3.2. AnythingLLM安裝及配置
在知識庫的構建中,我們采用AnythingLLM來作為知識庫的UI,你也可以選擇其他UI工具,比如 Dify,Fastchat, AnythingLLM 相對來說 0 代碼基礎的小伙伴就可以操作了,所以這里我們先以 AnythingLLM 為例。網址:https://anythingllm.com/ ,打開鏈接后界面如下:

點擊【Download for desktop】選擇合適的版本:

安裝步驟就略過了,都是傻瓜式的,但是有一點需要注意,不要把軟件裝在C盤,選一個空間足夠的盤:

下載好后,點擊運行,軟件的界面如下,點擊【開始】

選擇【Ollama】后自動加載我們已經下載好的大模型,選擇合適的模型后點擊下一步按鈕,之后都是點擊下一步按鈕:

輸入工作區名稱:

點擊【小肥腸科技公司合同管理】,進入默認對話界面,這個界面就是我剛剛在本地部署的的大模型DeepSpeek-r1:1.5b,可以直接和它對話(因為我的模型規格只有1.5b,所以它的回答有點可笑,顯存高的讀者盡量選擇規格高的模型):

接下來就是拉取向量化模型,這里我拉取的是Nomic-Embed-Text 模型(他有很強的長上下文處理能力),打開命令提示符窗口,輸入ollama pull nomic-embed-text:

點擊設置按鈕:

設置Embedding模型:

確保你的LLM 首選項為Ollama:

現在一切基礎工作準備就緒,接下來就是投喂資料了,我造假了一個喵喵星球租房的資料:
租房合同
甲方(出租方):豆豆
乙方(承租方):小肥腸科技有限公司
根據喵喵共和國相關規定,甲乙雙方就租賃房屋事宜達成如下協議:
一、房屋基本情況
房屋位置:喵喵共和國,貓爪街14號
房屋面積:150平方米
房屋類型:高層公寓
二、租賃期限
租期自2025年1月1日起至2025年12月30日止,期滿后可續租。
三、租金及支付方式
租金為小魚干30個/月,乙方應于每月1日前支付。
押金:小魚干100個,租期結束后無損壞可退還。
四、甲方責任
確保房屋符合安全標準,負責主要結構及設施維修。
五、乙方責任
按時支付租金,妥善使用房屋設施,如有損壞負責修理。
六、提前解除合同
需提前30個喵喵日通知對方,違約方需支付租金50%的違約金。
七、爭議解決
雙方可協商解決爭議,若協商不成,可向貓咪法院提起訴訟。
八、合同生效
本合同一式兩份,簽字蓋章后生效。
甲方(簽字):豆豆
乙方(簽字):小肥腸科技有限公司
簽訂日期:2025年1月1日
上傳資料,點擊上傳按鈕,彈出上傳資料的界面:

點擊【Click to upload or drag and drop】上傳資料(也可以直接拖拽進去):

上傳完成后點擊【Move to Workspace】:

點擊【Save and Embed】:

3.3. 效果測試

到此DeepSeek-RAG和本地知識庫的構建內容完結,需要注意的是本地部署很吃電腦配置,盡量選配置高一點的電腦,如果電腦配置實在不給力也可以選擇聯網版本的RAG(后續更新的智能體文章會講)。
4. 資料獲取
如果你對DeepSpeek的相關知識還不熟悉,可以關注公眾號后端小肥腸,點擊底部【資源】菜單獲取DeepSpeek相關教程。
5. 結語
隨著人工智能的不斷發展,AI已經不僅僅是一個技術工具,它正在深入改變我們的工作和生活方式。在信息處理、數據管理等領域,AI的應用已經成為提升效率、減少錯誤的關鍵。DeepSeek-RAG和本地知識庫的構建,是確保AI高效、可靠運作的核心所在。掌握這些技術,不僅能讓你走在技術前沿,更能幫助你在未來的職場競爭中占據先機。如果本文對你有幫助,請給小肥腸點點關注,小肥腸將持續更新更多AI領域干貨內容,你的關注是小肥腸最大更新動力哦~