













MCP 開發實戰:如何使用 MCP 真正加速 UE 項目開發
作者 | hanzo
用說人話的方式講解MCP。
目前各種MCP的文章和實際例子以及開源工具層出不窮,本文試圖用最簡單的方式解釋下MCP解決什么問題和MCP怎么寫的問題。

為啥要用MCP
MCP是一項專為LLM工具化操作設計的輕量化標準協議,其核心目標是構建LLM與異構軟件系統間的通用指令交互框架。與傳統的單一功能調用機制不同,MCP通過三層架構創新解決工具擴展性問題:
(1) 協議定位
作為中間協議層,MCP抽象出獨立于具體LLM和業務系統的接口描述層,允許開發者在不同維度(功能權限、輸入格式、執行環境)對工具接口進行靈活管控,避免傳統方案中接口爆炸帶來的維護難題。
(2) 技術架構
- 接口描述層:采用聲明式DSL定義工具元數據,包括功能語義、入參Schema、權限策略和執行上下文
- 代理控制層:內置動態路由引擎和權限驗證模塊,支持熱插拔式工具注冊與版本管理
- 協議適配層:提供跨平臺SDK,自動生成OpenAPI/Swagger等標準接口文檔
(3) 核心優勢
- 雙向解耦:前端LLM無需感知具體工具實現,后端系統可獨立迭代
- 權限縱深:細粒度控制工具可見性(開發者/用戶/模型層級)
- 執行沙箱:支持Docker/WASM等多重運行時隔離方案
- 生態兼容:自帶LangChain/LLamaIndex等主流框架的適配器
綜合上述的專業表述,說人話就是,只要你的LLM有Prompt遵循能力,那么不管你是qwen,llama,DeepSeek還是claude ,都可以連接同樣的MCP Server并且讓你的LLM能夠真正的調用工具,因此大大加速了LLM工具使用的開發速度。
為什么最近MCP爆發了?
最近大量MCP的爆發依賴于LLM本身兩個能力的大幅度提升:1.結構化輸出能力2.指令遵循能力。特別是claude3.7 sonnets之后的進展,使得工具的使用成功率大幅提升。對于LLM本身的能力進展來說,通過工具使用的方式積累真實世界的數據,并且進行后訓練,也會成為LLM的垂直能力和LLM工作準確率進一步提升的關鍵。
MCP Server開發實戰
有了基礎概念之后,我們就可以直接開始一個MCP Server的開發了,目前MCP官方提供四種語言的開發SDK,包括Python,typescript,java和kotlin。我們以IEG最常用的typescript為例構建工程。
在開始前我們先明確一些概念,通常,我們編寫的MCP是一個MCP Server,在Server中我們通常會定義一系列我們所需要的工具。使用各種LLM的客戶端只要能連接上Server,就可以使用我們的MCP的各種工具調用能力了。
在UE開發中,UE廢物一樣的文檔和天量的代碼經常讓人頭大,那么能不能讓LLM幫我來分析代碼呢?結合Emacs常用的tree-sitter語法分析庫和MCP,我們就可以用LLM來做這件事。
(本工程基于github:github.com/ayeletstu... 進行修改得來,由于原工程已經無法配置運行,我已經將修改后的代碼傳至 git.woa.com/IEG-RED-...)
首先,我們和普通配置NodeJs工程一樣,在Package.json中添加相應依賴:
"dependencies": {
"@modelcontextprotocol/sdk": "0.6.0",
"glob": "^8.1.0",
"tree-sitter": "^0.20.1",
"tree-sitter-cpp": "^0.20.0"
},
"devDependencies": {
"@types/glob": "^8.1.0",
"@types/jest": "^29.5.14",
"@types/node": "^18.15.11",
"jest": "^29.7.0",
"ts-jest": "^29.2.5",
"typescript": "^5.0.4"
}可以看到我們所需要的modelcontextprotocol sdk和tree-sitter等都可以直接從npm下載配置,我們按照常理執行npm install等步驟。接下來和通常的NodeJS程序一樣,我們編寫index.ts文件,先導入mcp相關的接口:
import { Server } from '@modelcontextprotocol/sdk/server/index.js';
import { StdioServerTransport } from '@modelcontextprotocol/sdk/server/stdio.js';
import {
CallToolRequestSchema,
ErrorCode,
ListToolsRequestSchema,
McpError,
} from '@modelcontextprotocol/sdk/types.js';這里我們可以看到MCP的幾個關鍵概念:
- Server:我們的MCP服務器,也就是處理一類任務的工具集合
- stdioServertransport:MCP默認用的通訊格式。
- RequestSchema:使用MCP時需要提供的參數,名字等等信息。
首先,我們需要定義一個Server class:
class UnrealAnalyzerServer {
private server: Server;
private analyzer: UnrealCodeAnalyzer;
......
}
public async start() {
try {
// Setup handlers first
this.setupToolHandlers();
// Connect to stdio transport
const transport = new StdioServerTransport();
await this.server.connect(transport);
console.log('Unreal Analyzer Server started successfully');
} catch (error) {
console.error('Failed to initialize server:', error);
process.exit(1);
}
}這里定義了我們的server的一些最常用的初始化流程和工具定義過程,因為我們是希望用MCP來分析代碼,因此我們的CodeAnalyzer也屬于我們的Server Class Member。
要定義工具,我們首先需要結合ListToolsRequestSchema來綁定我們的tools,參考下面的代碼:
private setupToolHandlers() {
this.server.setRequestHandler(ListToolsRequestSchema, async () => ({
tools: [
{
......
{
name: 'analyze_class',
description: 'Get detailed information about a C++ class',
inputSchema: {
type: 'object',
properties: {
className: {
type: 'string',
description: 'Name of the class to analyze',
},
},
required: ['className'],
},
},
.....我們定義工具的名字,和工具所需要的輸入,并將其綁定到server。這些信息會讓MCP識別到我們需要調用到什么工具,并且在調用工具時,需要提供什么樣的參數。
有了工具的名字和參數,MCP需要知道具體如何去執行我們想要的操作,比如分析C++類,搜索代碼等等,這里就要用到callToolRequestSchema結構體:
this.server.setRequestHandler(CallToolRequestSchema, async (request) => {
// Only check for initialization for analysis tools
const analysisTools = ['analyze_class', 'find_class_hierarchy', 'find_references', 'search_code', 'analyze_subsystem', 'query_api'];
if (analysisTools.includes(request.params.name) && !this.analyzer.isInitialized() &&
request.params.name !== 'set_unreal_path' && request.params.name !== 'set_custom_codebase') {
throw new Error('No codebase initialized. Use set_unreal_path or set_custom_codebase first.');
}
switch (request.params.name) {
.....
case 'search_code':
return this.handleSearchCode(request.params.arguments);
case 'analyze_subsystem':
return this.handleAnalyzeSubsystem(request.params.arguments);
case 'query_api':
return this.handleQueryApi(request.params.arguments);
default:
throw new Error(`Unknown tool: ${request.params.name}`);
}
});
}很明顯,callToolRequestSchema會將tools的名字和參數傳給工具真正的執行者。在我們的Server內部定義的工具函數中,會調用tree-sitter cpp庫 去進行真正的分析,然后將結果返回給我們的LLM進行總結。
來總結下, MCP的編寫本身是非常簡單的,我們需要實現的是定義工具的名字,參數(從LLM中自然語言的方式獲取),以及用代碼描述的真正執行工具的流程,并且將這些都綁定到我們的Server上,我們只需要關心我們在調用什么工具和我們需要什么數據就行了,至于給大模型的提示詞,多輪對話暫存,格式化輸出驗證等需要考慮到問題,MCP的SDK都能幫我們搞定。
接下來我們用tsc編譯我們的Nodejs程序,我們的Server就做好了。
使用MCP
讀到這里細心的讀者肯定會發現。我們的LLM在哪里?這就是MCP更重要的一個好處,它的Server是LLM無關的,只要客戶端使用的LLM看得懂提示詞,那么它就能使用同一個MCP Server。
接下來我們配置客戶端來使用我們的MCP Server,目前很多軟件,包括Claude desktop,dify等都支持了MCP,這里我們選擇VSCode 的Cline插件作為客戶端(因為他開源),安裝和配置Cline的過程在此不再贅述,打開Cline的Setting,點擊MCP Servers的按鈕,我們會在下方看到一個Configure MCP Server的按鈕,點擊我們就可以打開我們的MCP設置Json:
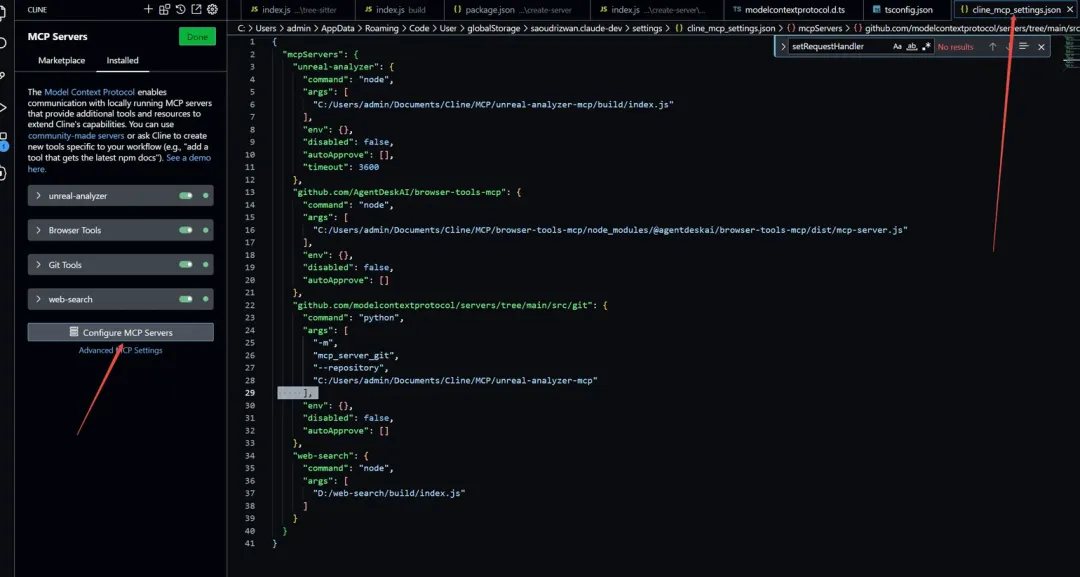
前文提到過,MCP支持多種語言開發,包括Python,Typescript等,因此可以看到我們的MCP配置中也支持多種入口,一個MCP Server的入口,可以是Python腳本,可以是bat批處理,也可以是nodejs程序的入口,對于我們的server來說,我們要配置的是一個nodejs的入口程序,如下面的代碼:
"unreal-analyzer": {
"command": "node",
"args": [
"C:/Users/admin/Documents/Cline/MCP/unreal-analyzer-mcp/build/index.js"
],
"env": {},
"disabled": false,
"autoApprove": [],
"timeout": 3600 }我們將入口指向我們編譯好的JavaScript文件,保存好之后,Cline就會自動去執行這個index.js,如果有運行錯誤,那么Cline的設置窗口中會報錯,當出現下面的綠色按鈕時,則證明我們的MCP Server連接成功了:
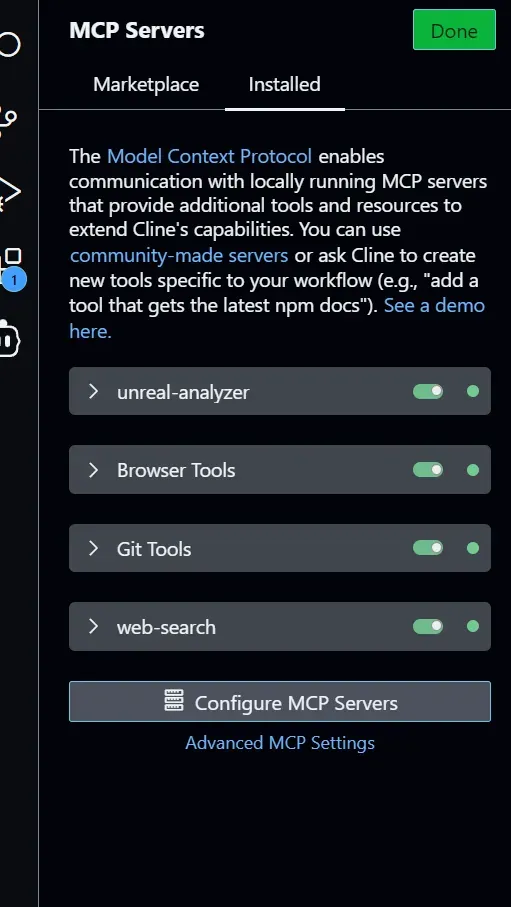
接下來,我們就可以用自然語言的方式快速分析UE代碼了,我們在Cline的對話框中切換到Act Mode(只有Actmode可以調用MCP Server),然后按照我們日常和同事交流說話的口吻打字:先告訴他我們的UE代碼在哪里:

直接說:我想分析下UMaterialExpressionPanner這個類,LLM會分析你的需求,自己去調用工具:

同時,LLM也會根據自己的思考去繼續調用工具,比如我的這個問題,它會繼續調用工具,去搜索代碼:
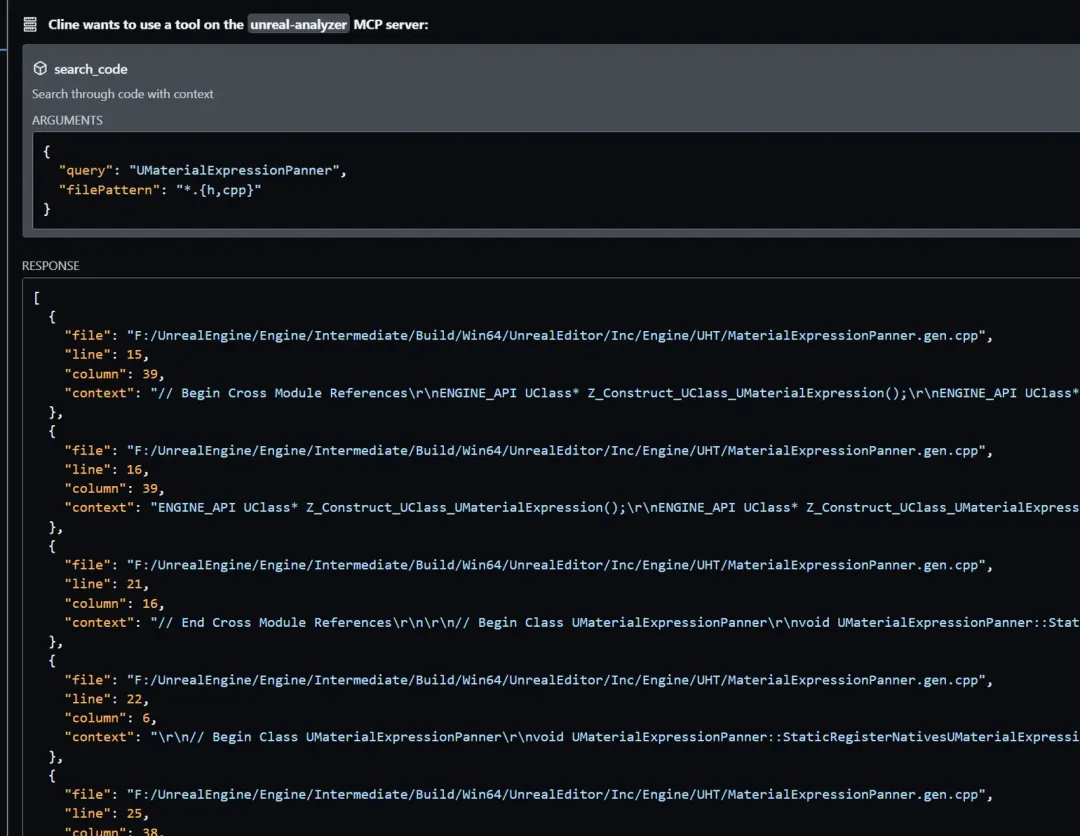
當他發現代碼非常多的時候,它會考慮到:OK,我可能需要過濾一下代碼,于是它會調用SearchWithContext的工具:

來個稍微復雜點的任務,讓它幫我找找lumen里AO相關的類:
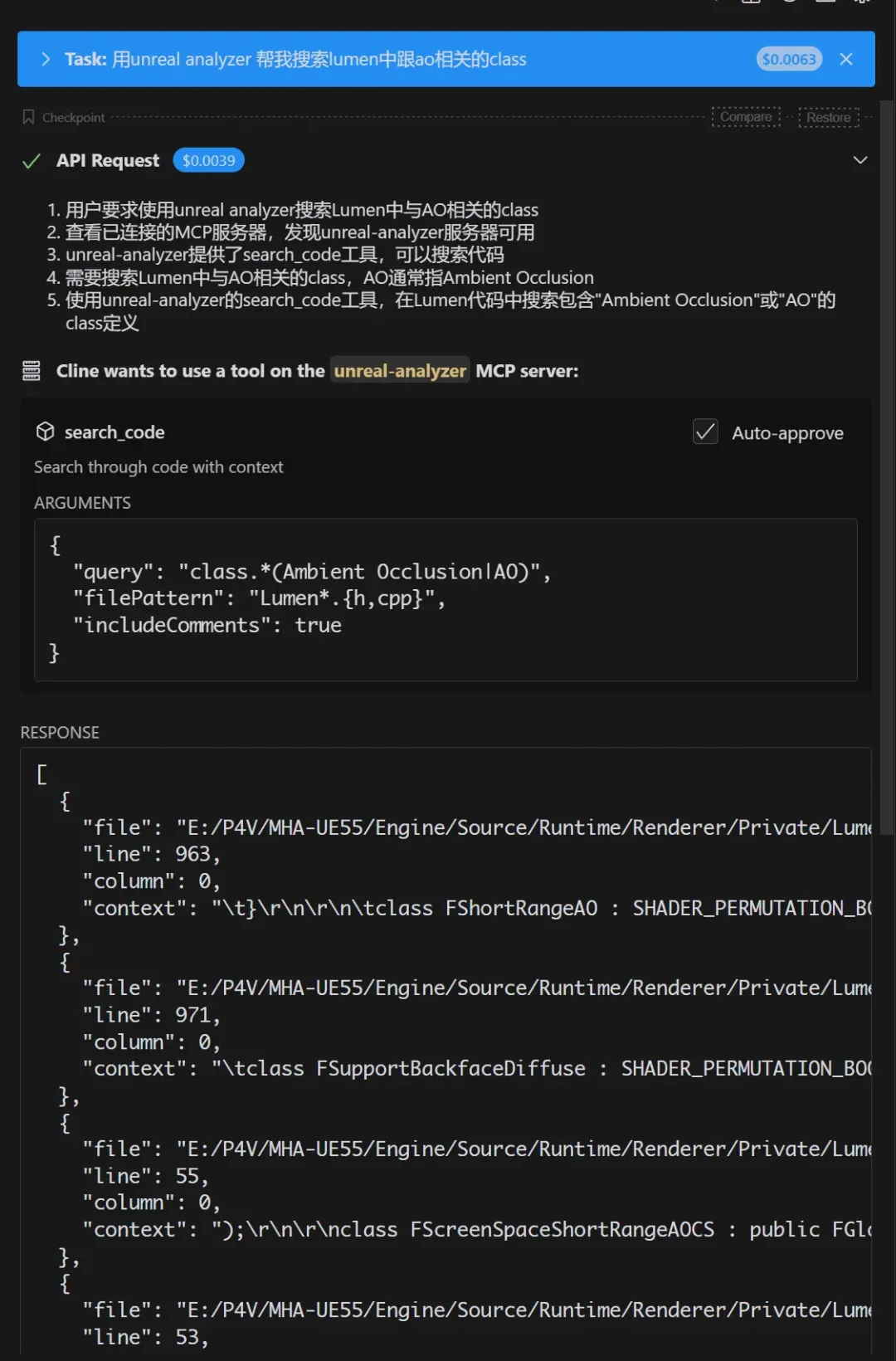

通過這個很簡單的例子工程,我們可以總結出MCP的特點,MCP通過工程化的方法和統一的協議,給LLM裝上了使用工具的手,這樣我們的AI就可以真正的替我們干活。
真正的UnrealMCP實現
理解了MCP的工作邏輯和原理之后, 再開發垂直領域的MCP工具就會相對簡單。接下來我們來分析下真正的能干活的UnrealMCP(github.com/kvick-gam...)是怎么工作的。同時也展示下Python SDK下的MCP工作流。
UnrealMCP由兩部分組成,一部分是MCP Server的Python代碼,一部分是UE5的插件,其中UE5的插件主要負責對接我們操作UE需要的一些C++邏輯。這部分的安裝邏輯和通常的UE插件完全一樣。
而MCP本身的部分,我們希望能夠在Cline插件中調用,由于這個UnrealMCP只能在Claude中工作,而Claude在國內使用非常麻煩,因此在Cline中配置本MCP時,我們需要對倉庫上說明的配置文件稍微進行些修改。 在運行安裝python, 啟動venv等工作之后,我們在配置Cline MCP的json時,需要按照如下代碼配置:
"unreal": {
"command": "cmd.exe",
"args": [
"/c",
"F:\\UnrealEngine\\Engine\\Plugins\\UnrealMCP\\MCP\\run_unreal_mcp.bat"
],
"env": {
"PYTHONPATH": "F:\\UnrealEngine\\Engine\\Plugins\\UnrealMCP\\MCP\\python_modules",
"PATH": "${PATH};F:\\UnrealEngine\\Engine\\Plugins\\UnrealMCP\\MCP\\python_env\\Scripts"
},
"disabled": false,
"autoApprove": [],
"cwd": "F:\\UnrealEngine\\Engine\\Plugins\\UnrealMCP\\MCP"
},這樣就可以在Cline中使用UnrealMCP了。
使用上,UnrealMCP也是非常簡單的,打開UE,啟動UnrealMCP插件之后,我們告訴LLM我們的需求:在場景中創建一個迷宮關卡:

MCP會將相關信息包裝成Python調用腳本,發給UnrealMCP Server:

我們就可以得到最終結果:

和之前的例子一樣,開發UnrealMCP還是遵循定義工具名字,參數,定義行為的這幾個步驟,在UnrealMCP中,它采用了:
- Python MCP 服務
- Python-C++ 橋接層
- C++ Unreal Engine 插件
的三層架構來實現(因為UE的EditorPython并不是很完善,所以需要通過C++插件來實現命令的解析和工作)。以最簡單的CreateObject為例子: 首先,依然是注冊工具和參數,當然,使用Python SDK,這個過程會更加直接簡單,通過Python的注解語法來進行:
@mcp.tool()
def create_object(ctx: Context, type: str, location: list = None, label: str = None) -> str:
params = {"type": type}
if location:
params["location"] = location
if label:
params["label"] = label
response = send_command("create_object", params)我們需要告訴UE我要創建的location和物體類型,接下來,用Python的socket通信封裝一下LLM產生的數據,傳給UE:
def send_command(command_type, params=None, timeout=DEFAULT_TIMEOUT):
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
s.connect(("localhost", DEFAULT_PORT))
command = {"type": command_type, "params": params or {}}
s.sendall(json.dumps(command).encode('utf-8'))
response_data = receive_response(s)
return json.loads(response_data.decode('utf-8'))最后UE在C++插件中進行接受消息,去調用NewActor函數:
TSharedPtr<FJsonObject> FMCPCreateObjectHandler::Execute(const TSharedPtr<FJsonObject> &Params, FSocket *ClientSocket)
{
// 從參數中提取數據
FString Type;
Params->TryGetStringField(FStringView(TEXT("type")), Type);
// 執行 Unreal Engine 操作
AStaticMeshActor *NewActor = World->SpawnActor<AStaticMeshActor>(...);
// 返回響應
TSharedPtr<FJsonObject> ResultObj = MakeShared<FJsonObject>();
ResultObj->SetStringField("name", NewActor->GetName());
return CreateSuccessResponse(ResultObj);
}雖然整體流程復雜了些,但是可以看到,它依然遵循了MCP的設計范式,既通過Tools來擴展能力,告訴LLM,你可以去干什么事,然后用各種方法,將LLM分析自然語言后得出的指令轉為工具調用,去做真正的工作。
MCP的局限性
MCP雖然非常簡潔明了,大大方便了LLM Tool use的開發成本,但是從本質上來說,MCP只是解決了工具使用的可能性這一個主題,要想讓AI真正干活,可以說MCP只是干活的那只手,我們同樣需要大腦(規劃Agent),記憶力(數據庫,記事本)來共同輔助完成自動化的工作。
此外,對于真正的專業軟件來說,每一個接口/功能對應MCP可能也是一個工程量不小的工作,MCP結合真正靠譜的Agent編程框架才有可能完成真正復雜的任務。
總結
本文通過兩個案例,展示了MCP的整體開發邏輯和能力。通過MCP,大模型可以真正干活。但同時,MCP不應該被過度神話,它只是解決了工具調用這一系列的問題。要想讓大模型徹底重塑日常的游戲開發工作流,還需要在流程,記憶力,以及模型本身的后訓練上持續工作。



























