反向傳播、前向傳播都不要,這種無梯度學習方法是Hinton想要的嗎?
「我們應該拋棄反向傳播并重新開始。」早在幾年前,使反向傳播成為深度學習核心技術之一的 Geoffrey Hinton 就發表過這樣一個觀點。

而一直對反向傳播持懷疑態度的也是 Hinton。因為這種方法既不符合生物學機理,與大規模模型的并行性也不兼容。所以,Hinton 等人一直在尋找替代反向傳播的新方法,比如 2022 年的前向 - 前向算法。但由于性能、可泛化性等方面仍然存在問題,這一方向的探索一直沒有太大起色。
最近,來自牛津大學和 Mila 實驗室的研究者向這一問題發起了挑戰。他們開發了一種名為 NoProp 的新型學習方法,該方法既不依賴前向傳播也不依賴反向傳播。相反,NoProp 從擴散和流匹配(flow matching)方法中汲取靈感,每一層獨立地學習對噪聲目標進行去噪。

- 論文標題:NOPROP: TRAINING NEURAL NETWORKS WITHOUT BACK-PROPAGATION OR FORWARD-PROPAGATION
- 論文鏈接:https://arxiv.org/pdf/2503.24322v1
研究人員認為這項工作邁出了引入一種新型無梯度學習方法的第一步。這種方法不學習分層表示 —— 至少不是通常意義上的分層表示。NoProp 需要預先將每一層的表示固定為目標的帶噪聲版本,學習一個局部去噪過程,然后可以在推理時利用這一過程。
他們在 MNIST、CIFAR-10 和 CIFAR-100 圖像分類基準測試上展示了該方法的有效性。研究結果表明,NoProp 是一種可行的學習算法,與其他現有的無反向傳播方法相比,它實現了更高的準確率,更易于使用且計算效率更高。通過擺脫傳統的基于梯度的學習范式,NoProp 改變了網絡內部的貢獻分配(credit assignment)方式,實現了更高效的分布式學習,并可能影響學習過程的其他特性。
在看了論文之后,有人表示,「NoProp 用獨立的、無梯度的、基于去噪的層訓練取代了傳統的反向傳播,以實現高效且非層次化的貢獻分配。這是一項具有開創性意義的工作,可能會對分布式學習系統產生重大影響,因為它從根本上改變了貢獻分配機制。
其數學公式中涉及每層特定的噪聲模型和優化目標,這使得無需梯度鏈即可進行獨立學習。其優勢在于通過讓每一層獨立地對一個固定的噪聲目標進行去噪,從而繞過了反向傳播中基于順序梯度的貢獻分配方式。這種方式能夠實現更高效、可并行化的更新,避免了梯度消失等問題,盡管它并未構建傳統的層次化表示。」

還有人表示,「我在查看擴散模型架構時也產生過這樣的想法…… 然而,我認為這可能是一種非最優的方法,所以它現在表現得如此出色讓我感到很神秘。顯而易見的是其并行化優勢。」


為什么要尋找反向傳播的替代方案?
反向傳播雖是訓練神經網絡的主流方法,但研究人員一直在尋找替代方案,原因有三:
- 生物學合理性不足:反向傳播需要前向傳遞和后向傳遞嚴格交替,與生物神經系統運作方式不符。
- 內存消耗大:必須存儲中間激活值以計算梯度,造成顯著內存開銷。
- 并行計算受限:梯度的順序傳播限制了并行處理能力,影響大規模分布式學習,并導致學習過程中的干擾和災難性遺忘問題。
目前為止,反向傳播的替代優化方法包括:
- 無梯度方法:如直接搜索方法和基于模型的方法
- 零階梯度方法:使用有限差分近似梯度
- 進化策略
- 基于局部損失的方法:如差異目標傳播(difference target propagation)和前向 - 前向算法
但這些方法因在準確性、計算效率、可靠性和可擴展性方面的限制,尚未在神經網絡學習中廣泛應用。
方法解析
NoProp
設 x 和 y 是分類數據集中的一個輸入 - 標簽樣本對,假設從數據分布 q?(x,y) 中抽取,z?,z?,...,z? ∈ R? 是神經網絡中 T 個模塊的對應隨機中間激活值,目標是訓練該網絡以估計 q?(y|x)。
定義兩個分布 p 和 q,按以下方式分解:

p 分布可以被解釋為一個隨機前向傳播過程,它迭代地計算下一個激活值 z?,給定前一個激活值 z??? 和輸入 x。實際上,可以看到它可以被明確表示為一個添加了高斯噪聲的殘差網絡:

其中 N?(?|0,1) 是一個 d 維高斯密度函數,均值向量為 0,協方差矩陣為單位矩陣,a?,b?,c? 是標量(如下所示),b?z??? 是一個加權跳躍連接,而 ?θ?(z???,x) 是由參數 θ? 參數化的殘差塊。注意,這種計算結構不同于標準深度神經網絡,后者沒有從輸入 x 到每個模塊的直接連接。遵循變分擴散模型方法,也可以將 p 解釋為給定 x 條件下 y 的條件隱變量模型,其中 z? 是一系列隱變量。可以使用變分公式學習前向過程 p,其中 q 分布作為變分后驗。關注的目標是 ELBO,這是對數似然 log p (y|x)(即證據)的下界:

遵循 Sohl-Dickstein 和 Kingma 等人的方法,將變分后驗 q 固定為一個易于處理的高斯分布。在這里使用方差保持的 Ornstein-Uhlenbeck 過程:

其中 u? 是類別標簽 y 在 R? 中的嵌入,由可訓練的嵌入矩陣 W (Embed) ∈ R??? 定義,m 是類別數量。嵌入由 u? = {W (Embed)}? 給出。利用高斯分布的標準性質,我們可以得到:

其中 ?? = ∏????α?,μ?(z???,u?) = a?u? + b?z???,a? = √(??(1-α???))/(1-????),b? = √(α???(1-??))/(1-????),以及 c? = (1-??)(1-α???)/(1-????)。為了優化 ELBO,將 p 參數化以匹配 q 的形式:

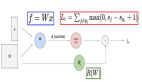
其中 p (z?) 被選為 Ornstein-Uhlenbeck 過程的平穩分布,?θ?(z???,x) 是由參數 θ? 參數化的神經網絡模塊。給定 z??? 和 x 對 z? 進行采樣的結果計算如殘差架構(方程 3)所示,其中 a?,b?,c? 如上所述。最后,將此參數化代入 ELBO(方程 4)并簡化,得到 NoProp 目標函數:

其中 SNR (t) = ??/(1-??) 是信噪比,η 是一個超參數,U {1,T} 是在整數 1,...,T 上的均勻分布。我們看到每個 ?θ?(z???,x) 都被訓練為直接預測 u?,給定 z??? 和 x,使用 L2 損失,而 p?θout (y|z?) 被訓練為最小化交叉熵損失。每個模塊 ?θ?(z???,x) 都是獨立訓練的,這是在沒有通過網絡進行前向或反向傳播的情況下實現的。
實現細節
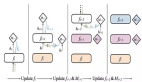
NoProp 架構如圖 1 所示。

在推理階段,NoProp 架構從高斯噪聲 z?開始,通過一系列擴散步驟轉換潛變量。每個步驟中,潛變量 z?通過擴散動態塊 u?演化,形成序列 z?→z?→...→z?,其中每個 u?都以前一狀態 z???和輸入圖像 x 為條件。最終,z?通過線性層和 softmax 函數映射為預測標簽?。
訓練時,各時間步驟被采樣,每個擴散塊 u?獨立訓練,同時線性層和嵌入矩陣與擴散塊共同優化以防止類別嵌入崩潰。對于流匹配變體,u?表示 ODE 動態,標簽預測通過尋找與 z?在歐幾里得距離上最接近的類別嵌入獲得。
訓練所用的模型如圖 6 所示,其中左邊為離散時間情況的模型,右邊為連續時間情況的模型。

作者在三種情況下構建了相似但有區別的神經網絡模型:
- 離散時間擴散:神經網絡 ?θt 將圖像 x 和潛變量 zt?1 通過不同嵌入路徑處理后合并。圖像用卷積模塊處理,潛變量根據維度匹配情況用卷積或全連接網絡處理。合并后的表示通過全連接層產生 logits,應用 softmax 后得到類別嵌入上的概率分布,最終輸出為類別嵌入的加權和。
- 連續時間擴散:在離散模型基礎上增加時間戳 t 作為輸入,使用位置嵌入編碼并與其他特征合并,整體結構與離散情況相似。
- 流匹配:架構與連續時間擴散相同,但不應用 softmax 限制,允許 v?θ 表示嵌入空間中的任意方向,而非僅限于類別嵌入的凸組合。
所有模型均使用線性層加 softmax 來參數化相應方程中的條件概率分布。
對于離散時間擴散,作者使用固定余弦噪聲調度。對于連續時間擴散,作者將噪聲調度與模型共同訓練。
實驗結果
作者對 NoProp 方法進行了評估,分別在離散時間設置下與反向傳播方法進行比較,在連續時間設置下與伴隨敏感性方法(adjoint sensitivity method)進行比較,場景是圖像分類任務。
結果如表 1 所示,表明 NoProp-DT 在離散時間設置下在 MNIST、CIFAR-10 和 CIFAR-100 數據集上的性能與反向傳播方法相當,甚至更好。此外,NoProp-DT 在性能上優于以往的無反向傳播方法,包括 Forward-Forward 算法、Difference Target 傳播以及一種稱為 Local Greedy Forward Gradient Activity-Perturbed 的前向梯度方法。雖然這些方法使用了不同的架構,并且不像 NoProp 那樣顯式地對圖像輸入進行條件約束 —— 這使得直接比較變得困難 —— 但 NoProp 具有不依賴前向傳播的獨特優勢。

此外,如表 2 所示,NoProp 在訓練過程中減少了 GPU 內存消耗。

為了說明學習到的類別嵌入,圖 2 可視化了 CIFAR-10 數據集中類別嵌入的初始化和最終學習結果,其中嵌入維度與圖像維度匹配。

在連續時間設置下,NoProp-CT 和 NoProp-FM 的準確率低于 NoProp-DT,這可能是由于它們對時間變量 t 的額外條件約束。然而,它們在 CIFAR-10 和 CIFAR-100 數據集上通常優于伴隨敏感性方法,無論是在準確率還是計算效率方面。雖然伴隨方法在 MNIST 數據集上達到了與 NoProp-CT 和 NoProp-FM 相似的準確率,但其訓練速度明顯較慢,如圖 3 所示。

對于 CIFAR-100 數據集,當使用 one-hot 編碼時,NoProp-FM 無法有效學習,導致準確率提升非常緩慢。相比之下,NoProp-CT 仍然優于伴隨方法。然而,一旦類別嵌入與模型聯合學習,NoProp-FM 的性能顯著提高。
作者還對類別概率 的參數化和類別嵌入矩陣 W_Embed 的初始化進行了消融研究,結果分別如圖 4 和圖 5 所示。消融結果表明,類別概率的參數化方法之間沒有一致的優勢,性能因數據集而異。對于類別嵌入的初始化,正交初始化和原型初始化通常與隨機初始化相當,甚至優于隨機初始化。
的參數化和類別嵌入矩陣 W_Embed 的初始化進行了消融研究,結果分別如圖 4 和圖 5 所示。消融結果表明,類別概率的參數化方法之間沒有一致的優勢,性能因數據集而異。對于類別嵌入的初始化,正交初始化和原型初始化通常與隨機初始化相當,甚至優于隨機初始化。

 更多詳細內容請參見原論文。
更多詳細內容請參見原論文。