谷歌提出Transformer架構中,表示崩塌、過度壓縮的五個解決方法
Transformer架構的出現(xiàn)極大推動了生成式AI的發(fā)展,在此基礎之上開發(fā)出了ChatGPT、Copilot、訊飛星火、文心一言、Midjourney等一大批知名產(chǎn)品。
但Transformer架構并非完美還存在不少問題,例如,在執(zhí)行需要計數(shù)或復制輸入序列元素的任務經(jīng)常會出錯。而這些操作是推理的基本組件,對于解決日常任務至關重要。
所以,谷歌DeepMind和牛津大學的研究人員發(fā)布了一篇論文,深度研究了在解碼器Transformer架構中的“表示崩塌”和“過度壓縮”兩大難題,同時提供了幾個簡單的解決方案。

表示崩塌
表示崩潰是指在某些情況下,輸入給大模型的不同序列在經(jīng)過處理后,會生成非常相似甚至幾乎相同的表示,并導致模型無法具體區(qū)分它們。
這是因為Transformer架構中的自注意力機制和位置編碼的設計,使得隨著序列的增長,信息的表示越來越集中,從而導致信息的損失。

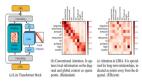
為了更好地解釋這種表示崩潰,研究人員定義了兩個序列的表示差異,并在Gemma 7B大語言模型中進行了實驗。

一組是逐漸增長的1的序列,另一組是在1的序列末尾添加了一個額外的1。通過觀察這兩組序列在Transformer模型中的表示。
研究人員發(fā)現(xiàn),隨著序列長度的增加,兩組序列的表示差異逐漸減小,直至低于機器的浮點精度,這時大模型已經(jīng)無法精準區(qū)分這兩個序列了。
過度壓縮
過度壓縮現(xiàn)象的出現(xiàn)與表示崩塌有很大關系。在Transformer模型中,過度壓縮的表現(xiàn)為早期輸入的token在模型的最終表示中的影響力減弱,特別是當這些token距離序列的末尾較遠時。

由于Transformer模型的自注意力機制和層疊結構,數(shù)據(jù)在每一層都會經(jīng)過多次的壓縮和重新分配,這可能導致一些重要的信息在傳播過程中被稀釋或變得非常不明顯。

為了展示過度壓縮在Transformer中的詳細表現(xiàn),研究人員深度分析了如何通過模型的每一層傳遞并最終影響下一個token的預測。
研究人員發(fā)現(xiàn),對于序列中較早的token,由于它們可以通過更多的路徑影響最終的表示,因此它們的影響力會隨著序列長度的增加而減少。這種影響力隨著token在序列中的位置而變化,序列開始的token比序列末尾的token更容易在模型的表示中保留其信息。

同樣為了驗證該現(xiàn)象的存在,研究人員在Gemini 1.5和Gemma 7B模型中進行了復制和計數(shù)任務實驗。
結果顯示,當序列長度增加時,模型在復制序列末尾的token時表現(xiàn)不佳,而在復制序列開始的token時表現(xiàn)較好,這基本驗證了過度壓縮的現(xiàn)象確實存在。
五個解決方案
為了解決Transformer架構中的表示崩塌和過度壓縮兩大難題,研究人員提出了5個簡單有效的解決方法。
- 改進注意力機制:最直接的方法就是改進Transformer架構中的自注意力機制。通過調整注意力權重的分配,可以增強模型對序列中早期token的關注。這可以通過修改注意力分數(shù)的計算方式來實現(xiàn),例如,通過增加對早期token的權重,或者重新設計一種機制,使得模型在處理長序列時不會忽略這些token。
- 改進位置編碼:位置編碼是Transformer模型中用于捕捉序列中token位置信息的關鍵組件。可以改進這個模塊,例如,使用相對位置編碼或可學習的動態(tài)位置編碼,有助于模型更好地保持序列中各個token的獨特性,從而減少表示崩潰的發(fā)生。
- 增加大模型深度和寬度:增加模型的深度和寬度可以提供更多的參數(shù)來學習復雜的表示,有助于模型更好地區(qū)分不同的輸入序列。但是對AI算力的需求也非常大,不適合小型企業(yè)和個人開發(fā)者。
- 使用正則化:例如,使用權重衰減可以幫助模型避免過擬合,有助于減少表示崩潰現(xiàn)象。通過在訓練過程中引入噪聲或限制權重的大小,能抵抗輸入序列的微小變化。
- 引入外部記憶組件:可以使用外部記憶組件,例如,差分記憶或指針網(wǎng)絡,可以幫助模型存儲和檢索長序列中的信息。這種外部記憶可以作為模型內部表示的補充,提供一種機制來保持序列中關鍵信息的活躍度。

為了驗證方法的有效性,研究人員在谷歌的Gemini 1.5和Gemma 7B大語言模型中行了綜合評測。結果顯示,改進注意力機制和引入外部記憶組件等方法,確實能有效緩解這兩大難題。