CV圈對決:谷歌提出ViTGAN,用視覺Transformer訓練GAN
卷積神經網絡(convoluitonal neural networks,CNN)憑借強大的卷積和池化(pooling)能力,在計算機視覺領域占領主導地位。
而最近Transformer架構的興起,開始在圖像和視頻識別任務中與CNN「掰頭」。特別是視覺Transformer(ViT)。
Dosovitskiy等人的研究已經展示了將圖像解釋為一系列類似于自然語言中的單詞的標記(token)。在ImageNet基準測試中,以較小的FLOP實現可比的分類精度。

現在盡管ViT及其變體仍然處于起步階段,但鑒于ViT在圖像識別方面表現出對競爭性,以及需要較少的視覺特定歸納偏差,ViT能不能擴展應用到圖像生成呢?
由谷歌和加州大學圣地亞哥分校組成的研究團隊對這個問題進行了研究,并發表了論文:ViTGAN:用視覺Transformer訓練生成對抗網絡(GAN)。

△ https://arxiv.org/pdf/2107.04589.pdf
論文研究的問題是:ViT是否可以在不使用卷積或池化的情況下完成圖像生成任務,即ViT是否能用具有競爭質量的GAN訓練出基于CNN的GAN。
研究團隊將ViT架構集成到中GAN中,發現現有的GAN正則化方法與自我注意機制的交互很差,導致訓練過程中嚴重的不穩定。
因此,團隊引入了新的正則化技術來訓練帶有ViT的GAN,得出以下研究結果:
1. ViTGAN模型遠優于基于Transformer的GAN模型,在不使用卷積或池化的情況下,性能與基于CNN的GAN(如Style-GAN2)相當。
2. ViTGAN模型是首個在GAN中利用視覺Transformer的模型之一。
3. ViTGAN模型展示了在標準圖像生成基準(包括CIFAR、CelebA和LSUN bedroom數據集)中,這種Transformer與最先進的卷積架構具有可比性的方法。
實驗方法
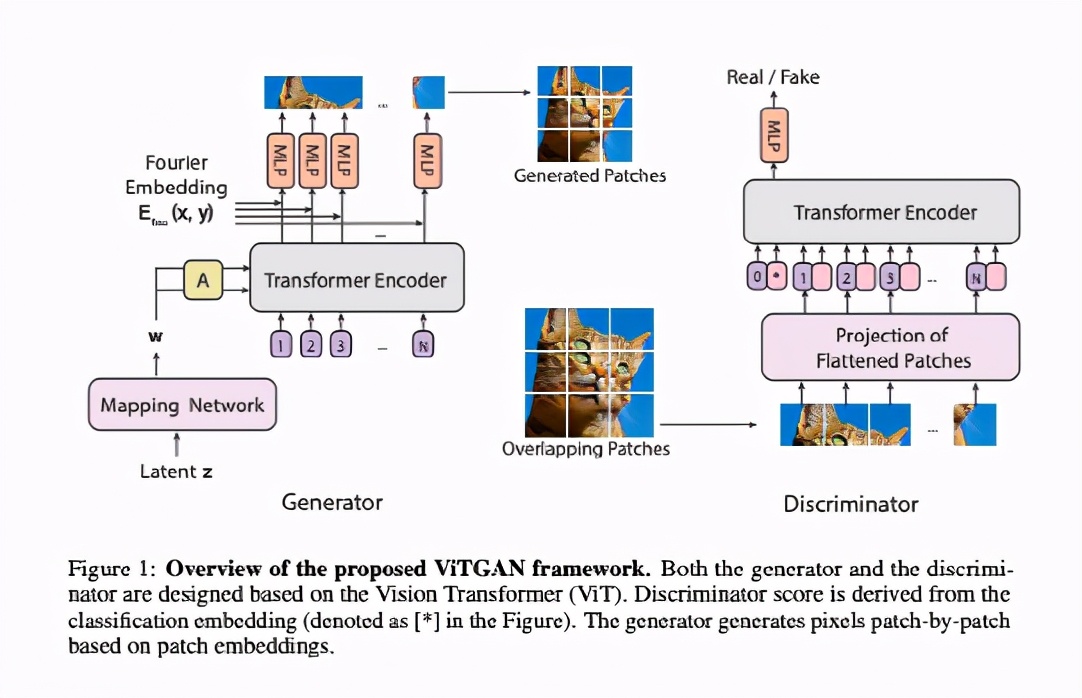
上圖說明了ViTGAN的架構,包括一個ViT鑒別器和一個基于ViT的生成器。
實驗發現,直接使用ViT作為鑒別器會使訓練變得不穩定。作者對生成器和鑒別器都引入了新的技術,用來穩定訓練動態并促進收斂。(1)ViT鑒別器的正則化;(2)生成器的新架構。
由于現有的 GAN 正則化方法與 self-attention 的交互很差,在訓練過程中導致嚴重的不穩定。
為了解決這個問題,作者引入了新穎的「正則化」技術來訓練帶有 ViT 的 GAN數據集上實現了與最先進的基于CNN 的 StyleGAN2 相當的性能。
利普希茨連續(Lipschitz continuity)在GAN鑒別器中很重要,首先它作為WGAN中近似Wasserstein距離的一個條件而引入注意力,后來在其他GAN設置中被證實超出了 Wasserstein損失。特別是,證明了Lipschitz鑒別器保證了最優鑒別函數的存在以及唯一納什均衡的存在。
然而,最近的一項工作表明,標準dot product self-attention(即Equation 5)層的Lipschitz常數可以是無界的,使Lipschitz連續在ViTs中被違反。
如Equation 7所示,實驗用歐氏距離代替點積相似度,query 和 key的投影矩陣的權重也是一樣的。
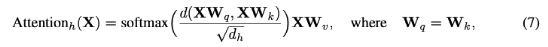
實驗發現,在初始化時將每層的歸一化權重矩陣與spectral norm相乘就足以解決這個問題。實驗用以下的更新規則來實現spectral norm,其中σ計算權重矩陣的標準spectral norm.
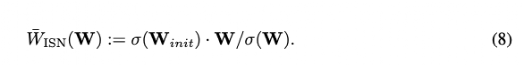
設計生成器
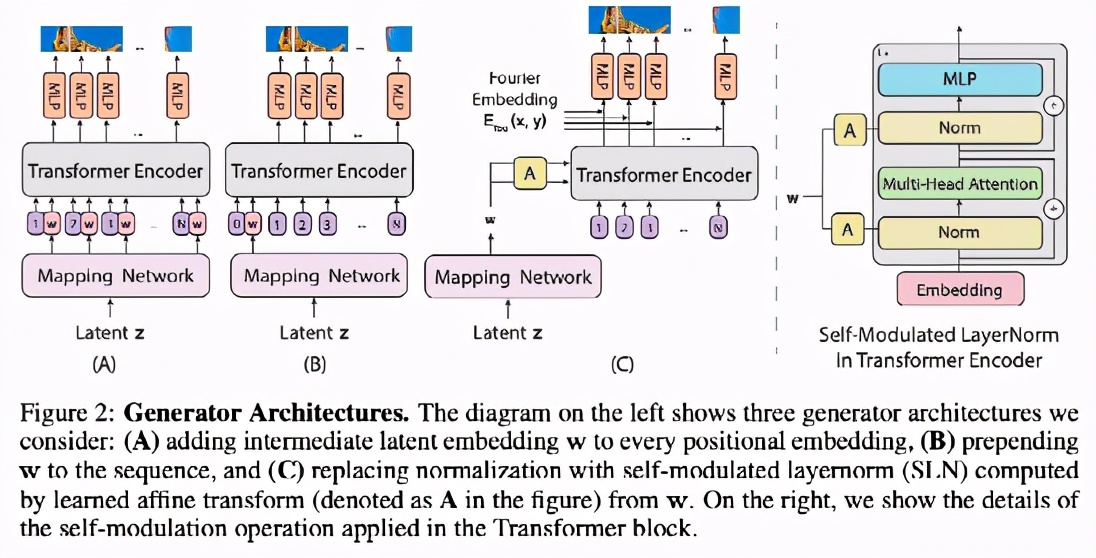
設計一個基于ViT架構的生成器并不簡單。一個挑戰是將ViT從預測一組類別標簽轉換為在一個空間區域內生成像素點。
在介紹實驗模型之前,作者先討論兩個可信的基線模型,如Fig. 2 (A)和2 (B)所示。這兩個模型交換ViT的輸入和輸出,從嵌入物中生成像素,特別是從潛伏向量 w,即w=MLP(z)(Fig. 2中稱為映射網絡),由MLP從高斯噪聲向量z中導出。
這兩個基線生成器在輸入序列上有所不同。Fig. 2(A)將一個位置嵌入序列作為輸入位置嵌入序列,并在每個位置嵌入中加入中間特征向量w.
實驗結果
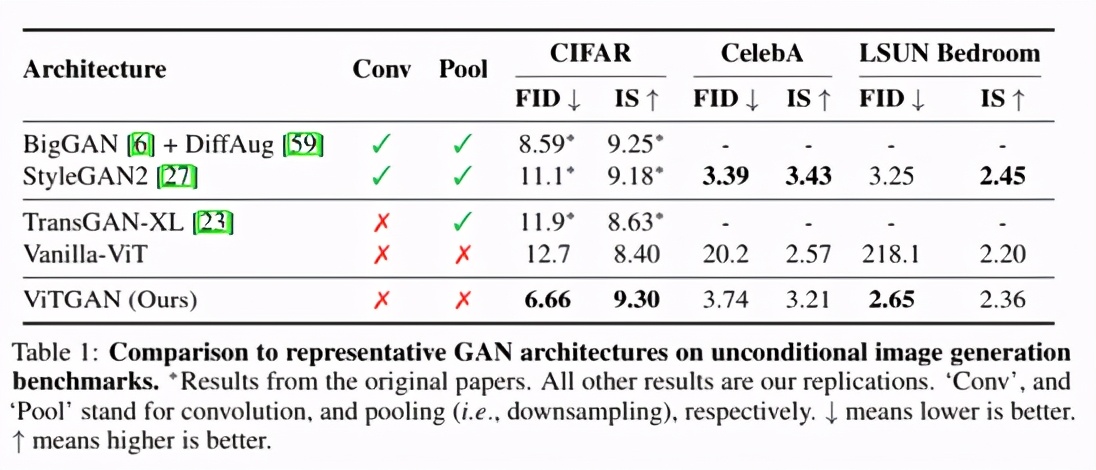
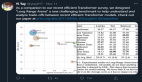
△ ViTGAN與基線架構關于圖像合成的主要結果對比
TransGAN是現有唯一一個完全建立在 Transformer 架構上的無卷積GAN,其最佳變體是TransGAN-XL。
Vanilla-ViT是一種基于ViT的GAN,它使用圖2(A)中所示的生成器和一個vanilla ViT鑒別器。
為公平比較,該基線使用了R1 penalty和bCR + DiffAug。
此外,BigGAN和StyleGAN2也作為最先進的基于CNN的GAN模型加入對比。
從上述表格可以看出,ViTGAN模型大大優于其他基于Transformer的GAN模型。這是在 Transformer架構上改進的穩定GAN訓練的結果。它實現了與最先進的基于 CNN 的模型相當的性能。
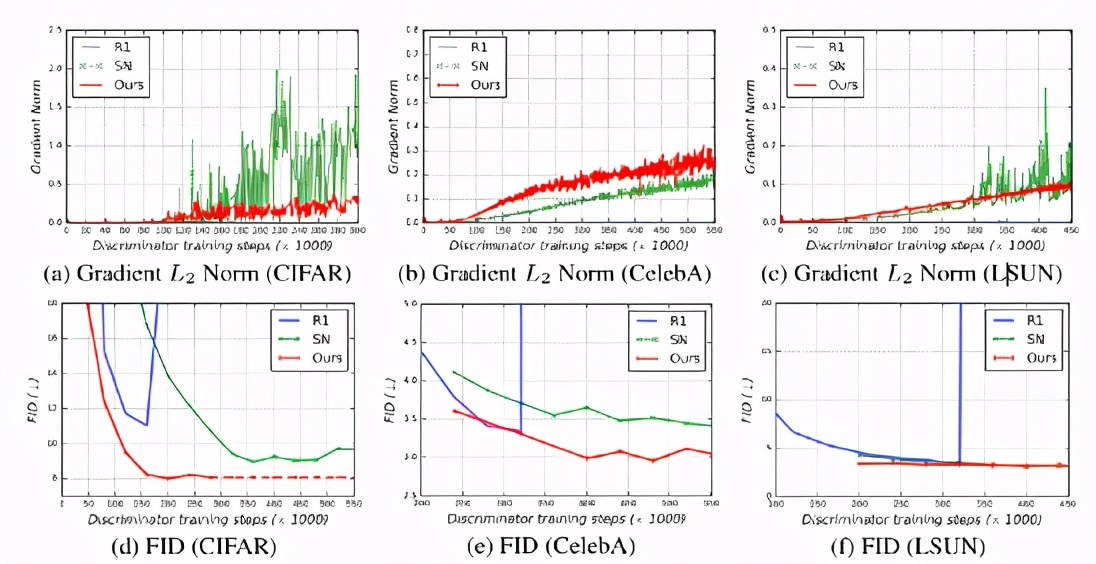
這一結果提供了一個經驗證據:Transformer架構可以在生成對抗訓練中與卷積網絡相媲美。



如上圖所示,ViTGAN模型(最后一列)顯著提高了最佳 Transformer 基線(中間列)的圖像保真度。即使與StyleGAN2相比,ViTGAN生成的圖像質量和多樣性也相當。
總結
這篇論文介紹了ViTGAN,利用GAN中的視覺Transformer(ViTs),并提出了確保其訓練穩定性和提高收斂性的基本技術。
在標準基準(CIFAR-10、CelebA和LSUN bedroom)上的實驗表明,提出的模型實現了與最先進的基于CNN的GAN相媲美的性能。
至于限制,ViTGAN是一個建立在普通ViT架構上的新的通用GAN模型。它仍然無法擊敗最好的基于CNN的GAN模型。
這可以通過將先進的訓練技術納入ViTGAN框架得到改善。希望ViTGAN能夠促進這一領域未來的研究,并可以擴展到其他圖像和視頻合成任務。