多模態大模型改造人臉防偽檢測,廈大騰訊優圖等研究入選CVPR 2025
近年來,人臉合成技術在快速發展,相關檢測任務也逐漸從“看得出來”向“說明白為什么”演進。除了判斷一張臉是真還是假,更需要模型能“說出個所以然”。
在CVPR 2025的工作《Towards General Visual-Linguistic Face Forgery Detection》中,研究團隊嘗試從視覺+語言的多模態視角來改進偽造檢測方法。
本文提出了一種簡單有效的訓練范式,并圍繞數據標注問題,構建了一個高質量的文本生成流程。
為什么要引入語言模態?
在偽造檢測任務中加入語言,有兩個直接的好處:
- 第一,提升可解釋性。比起真和假的這種二元黑盒輸出,如果模型能進一步說明“假在哪里”“怎么假”,無論是用于分析溯源,還是輔助下游任務,都更有價值;
- 第二,激活預訓練知識。現有的一些視覺backbone(如CLIP、LLaVA)等被證明能力已經高于很多純視覺預訓練模型,而這些模型在下游任務的潛在的知識需要語言模態來激活。所以我們希望它們的語言模態不僅能輔助理解圖像細節,還能提高模型的遷移能力和泛化表現。
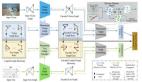
因此,團隊提出了如圖所示的一個新的多模態訓練框架:

△圖1:視覺語言偽造檢測訓練范式
該方法的關鍵在于:不再直接用圖像做二分類判斷,而是先為偽造圖像生成文本描述,再通過這些圖文對來聯合微調多模態模型,比如CLIP或mLLM。這樣訓練后的模型不僅能判斷偽造,還能在語言中“指出問題所在”。
但問題也隨之而來——
數據從哪里來?
多模態任務的關鍵是高質量標注數據。而偽造檢測任務相比于傳統的圖文匹配,難度在于:
- 它是一種更偏底層的任務,涉及的偽造往往是非常微妙的局部特征(比如鼻梁稍微歪了一點、嘴角顏色糊了一點);
- 要準確地用語言描述這些細節,遠沒有那么容易。
目前社區主流的做法大概有兩類:
- 人工眾包標注(如DD-VQA);
- 利用大模型(如GPT-4o)生成偽造描述。
但實驗發現,兩種方式都存在較明顯的問題,尤其在高質量偽造圖像中,容易出現“看花眼”的情況——模型或者標注人可能會誤判沒有問題的區域,產生所謂的“語言幻覺”。
如下圖所示,僅嘴部被修改的偽造圖,GPT和人工標注都錯誤地指出了鼻子區域:

△圖2:現有偽造文本標注容易出現幻覺
此外,真實圖像該怎么標注?要不要也寫一段文字描述?怎么寫才不誤導模型?這些問題都說明:需要一個系統化的、高可信度的標注流程。
FFTG偽造文本生成流程
針對上述挑戰,研究團隊提出了FFTG(人臉偽造文本生成器),這是一種新穎的標注流程,通過結合偽造掩碼指導和結構化提示策略,生成高精度的文本標注。

△圖3:FFTG標注流程
FFTG 標注流程主要分為兩個核心階段:原始標注生成 (Raw Annotation Generation) 和 標注優化 (Annotation Refinement)。
第一階段:原始標注生成
在這一階段,FFTG利用真實圖像和對應的偽造圖像,通過精確的計算分析生成高準確度的初始標注:
1、掩碼生成 (Mask Generation):
- 通過計算真實圖像和偽造圖像之間的像素級差異,生成偽造掩碼 M
- 掩碼值被歸一化到 [0,1] 范圍,突顯操作強度較大的區域
2、偽造區域提取 (Forgery Region Extraction):
- 基于面部特征點將人臉劃分為四個關鍵區域:嘴部、鼻子、眼睛和整個臉部
- 計算每個區域內掩碼 M 的平均值,并設置閾值 θ 判斷該區域是否被篡改
- 形成偽造區域列表,并從中隨機選擇一個區域進行下一步分析
3、偽造類型判定 (Forgery Type Decision): 設計了五種典型的偽造類型判斷標準:
- 顏色差異 (Color Difference):通過 Lab 色彩空間中的均值和方差差異檢測
- 模糊 (Blur):使用拉普拉斯算子量化局部模糊程度
- 結構異常 (Structure Abnormal):使用 SSIM 指數衡量結構變形
- 紋理異常 (Texture Abnormal):通過灰度共生矩陣 (GLCM) 對比度衡量紋理清晰度
- 邊界融合 (Blend Boundary):分析融合邊界的梯度變化、邊緣過渡和頻域特征
4、自然語言描述轉換:
- 將識別出的偽造區域和類型轉換為自然語言表達
- 如”Texture Abnormal”轉換為”lacks natural texture”,”Color Difference”轉換為”has inconsistent colors”
此階段生成的原始標注雖然結構相對固定,但準確度極高,為后續優化提供了可靠基礎。
第二階段:標注優化
為增加標注的多樣性和自然流暢性,FFTG 使用多模態大語言模型(如 GPT-4o-mini)進行標注優化,同時設計了全面的提示策略防止幻覺:
1、視覺提示 (Visual Prompt):
- 將真實和偽造人臉圖像作為配對輸入提供給大模型
- 這種對比方式使模型能通過直接比較識別偽造痕跡,減少幻覺
- 保持偽造檢測視角,避免生成與偽造無關的描述
2、指導提示 (Guide Prompt):
- 將前一階段生成的原始標注作為指導提供給大模型
- 附帶詳細解釋每種偽造類型的判定標準(如紋理異常是如何通過 GLCM 分析確定的)
- 強化技術依據,減少主觀臆斷
3、任務描述提示 (Task Description Prompt):
- 設定專家級偽造檢測任務情境
- 提供分析視覺證據和生成綜合描述的具體要求
- 引導模型進行逐步推理
4、預定義提示 (Pre-defined Prompt):
- 規定輸出格式(如 JSON 結構)
- 要求包含特定短語(如”This is a real/fake face”)
- 確保不同樣本的標注格式一致
下游微調:雙路模型訓練策略
有了高質量的圖文標注數據,接下來的問題是:如何充分利用這些數據來訓練模型?研究團隊提出了兩種不同的訓練策略,分別針對CLIP架構和多模態大語言模型(MLLM),注意本文的目的主要是驗證數據的有效性,所以才去了相對簡單的微調方式:
CLIP三分支訓練架構
對于CLIP這類經典的雙塔結構模型,團隊設計了一種三分支聯合訓練框架,如圖4所示。
這種訓練方法結合了單模態和多模態的學習目標:
1、圖像特征分類(Image Feature Classification):直接使用圖像編碼器提取的特征進行真偽二分類,保證模型在純視覺輸入下的基本檢測能力。
2、多模態特征對齊(Multimodal Feature Alignment):通過對比學習,使圖像特征和對應的文本特征在表示空間中對齊,并且激活CLIP預訓練時獲得的跨模態理解能力。
3、多模態特征融合分類(Multimodal Feature Classification):通過注意力機制融合視覺和文本特征,引導模型學習跨模態的偽造證據整合能力
這三個分支的損失函數共同優化,使模型既能獨立運行,又能充分利用文本信息來增強檢測能力。
MLLM微調方法
對于如LLaVA這類多模態大語言模型,采用了一種更為直接的微調方法:

△圖4:MLLM微調架構
MLLM通常由三部分組成:視覺編碼器、對齊投影器和大語言模型。策略是:
- 固定預訓練好的視覺編碼器參數,專注于微調對齊投影器和大語言模型部分
- 設計簡潔有效的提示模板:”Do you think this image is of a real face or a fake one? Please provide your reasons.”
- 這種雙部分提示不僅引導模型做出二分判斷,還要求提供可解釋的理由。
實驗:多維度驗證FFTG的有效性
為了全面評估提出的方法,團隊在多個偽造檢測基準數據集上進行了廣泛實驗,包括FaceForensics++、DFDC-P、DFD、CelebDF等。
標注質量評估
首先,比較了不同標注方法的質量:

△表1:不同標注方法的質量對比
結果表明,FFTG在所有指標上都顯著優于現有方法。特別是在精度上,FFTG比人工標注高出27個百分點,比直接使用GPT-4o-mini高出28個百分點,證明了該研究的掩碼引導和結構化提示策略能有效減少”幻覺”問題。
跨數據集泛化能力評估
在FF++數據集上訓練模型,并在其他四個未見過的數據集上測試,評估方法的泛化能力:

△表2:跨數據集泛化性能對比
在所有未見過的數據集上,該研究的方法都取得了性能提升。
可視化分析
團隊對模型的注意力機制進行了可視化分析,進一步驗證了FFTG的有效性:

△圖5:不同方法的注意力可視化對比
可以看到,使用FFTG標注訓練的模型能夠更精確地關注真正的偽造區域,而基線方法的注意力更為分散或錯位。例如,在NeuralTextures的例子中,該方法準確聚焦在嘴部區域的微妙變化,而其他方法則在未被篡改的區域產生錯誤激活。
總結
語言模態讓偽造檢測任務不止停留在“看得見”,更能“講得清”。
如果你也關注偽造檢測的可解釋性和泛化性,歡迎進一步了解。為了方便社區復現與研究,團隊已經將標注流程和生成數據集開放:https://github.com/skJack/VLFFD