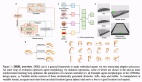
李飛飛/DeepSeek前員工領銜,復現R1強化學習框架,訓練Agent在行動中深度思考
什么開源算法自稱為DeepSeek-R1(-Zero) 框架的第一個復現?
新強化學習框架RAGEN,作者包括DeepSeek前員工Zihan Wang、斯坦福李飛飛團隊等,可訓練Agent在行動中深度思考。
 圖片
圖片
論文一作Zihan Wang在DeepSeek期間參與了Deepseek-v2和Expert Specialized Fine-Tuning等工作,目前在美國西北大學讀博。
他在介紹這項工作時上來就是一個靈魂提問:為什么你的強化學習訓練總是崩潰?
而RAGEN正是探討了使用多輪強化學習訓練Agent時會出現哪些問題 ,以及如何解決這些問題。
 圖片
圖片
通過大量實驗,研究團隊發現了訓練深度推理型Agent的三大難點:
- Echo Trap(回聲陷阱):多輪強化學習中,模型過度依賴局部收益的推理,導致行為單一化、探索能力衰退,從而影響長期收益。
- 數據質量:Agent生成的交互數據直接影響強化學習的效果。合理的數據應該具有多樣性、適度的交互粒度和實時性。比如在單個任務上多試幾次,每輪限制5-6個動作,并保持rollout的頻繁更新。
- 缺乏推理動機:如果沒有精心設計的獎勵函數,Agent很難學會多輪任務中持續的推理能力。甚至會出現表面看起來能完成任務,實際上只是匹配了固定模式的假象。下一步的關鍵在于建立更細粒度、面向解釋的獎勵機制。
在交互式隨機環境中訓練推理Agent
RAGEN是一個模塊化的Agent訓練和評估系統,基于StarPO(State-Thinking-Actions-Reward Policy Optimization)框架,通過多輪強化學習來優化軌跡級別的交互過程,由兩個關鍵部分組成:
MDP Formulation
將Agent與環境的交互表述為馬爾可夫決策過程 (MDP),其中狀態和動作是token序列,從而允許在環境動態上推理。
 圖片
圖片
StarPO:通過軌跡級優化強化推理
StarPO是一個通用的強化學習框架,用于優化Agent的整個多輪交互軌跡,在兩個階段之間交替進行,支持在線和離線學習。
Rollout階段:
給定初始狀態,該模型會生成多條軌跡。在每一步中,模型都會接收軌跡歷史記錄并生成推理引導的動作。
<think>...reasoning process...</think><ans> action </ans>環境接收動作并返回反饋(獎勵和下一個狀態)。
 圖片
圖片
Update階段:多回合軌跡優化
生成軌跡后,訓練優化預期獎勵。StarPO并非采用逐步優化的方式,而是使用重要性采樣來優化整個軌跡。這種方法能夠在保持計算效率的同時實現長遠推理。
StarPO支持PPO、GRPO等多種優化策略。
 圖片
圖片

除提出算法外,RAGEN論文中還重點介紹了通過研究推理穩定性和強化學習動態得出的6點主要發現。
6點主要發現
發現1:多輪訓練引入了新的不穩定模式
像PPO和GRPO這樣的單輪強化學習方法的adaptations在Agent任務中有效,但經常會崩潰。PPO中的“批評者”或許可以**延緩不穩定性,但無法阻止推理能力的下降,這凸顯了在Agent任務中對專門的穩定性進行改進的必要性。
發現2:Agent強化學習中的模型崩潰體現為訓練過程中的“回聲陷阱”
早期智能體會以多樣化的符號推理做出反應,但訓練后會陷入確定性、重復性的模板。模型會收斂到固定的措辭,這表明強化學習可能會強化表面模式而非一般推理,并形成阻礙長期泛化的“回聲陷阱”。
發現3:崩潰遵循類似的動態,可以通過指標預測
獎勵的標準差和熵通常會在性能下降之前發生波動,而梯度范數的峰值通常標志著不可逆崩潰的臨界點。這些指標提供了早期指標,并激發了對穩定策略的需求。
發現4:基于不確定性的過濾提高了訓練的穩定性和效率基于獎勵方差過濾訓練數據可以有效對抗“回聲陷阱”。僅保留高度不確定的訓練實例可以延遲或防止跨任務崩潰,并提高數據效率。
發現5:任務多樣性、行動預算和推出頻率影響數據質量
多樣化的任務實例能夠實現更好的策略對比和跨環境泛化。合適的行動預算能夠提供充足的規劃空間,并避免過長序列引入的噪聲。Up-to-date rollouts能夠確保優化目標與當前策略行為保持一致。
發現6:如果沒有精心的獎勵設計,推理行為就無法產生
雖然符號推理在弱監督下的單輪任務中自然出現,但在多輪環境中,如果沒有明確鼓勵可解釋的中間推理步驟的獎勵設計,它就無法持續存在。
團隊觀察到,即使有結構化的提示,如果獎勵信號僅關注最終結果,推理能力也會在訓練過程中逐漸衰退。這表明如果沒有細致的獎勵塑造,智能體可能會傾向于走捷徑,完全繞過推理。
One More Thing
同團隊還有另一個項目VAGEN,使用多輪強化學習訓練多模態Agent。
VAGEN 引入了回合感知推理交互鏈優化 (TRICO) 算法,通過兩項關鍵創新擴展了傳統的RICO方法:選擇性token屏蔽,跨輪credit分配。
與傳統的Agent強化學習相比,VAGEN不會平等對待軌跡中的所有token,而是重點優化最關鍵的決策token并在交互過程中創建更細致的獎勵結構,更適合多模態Agent
 圖片
圖片
RAGEN、VAGEN代碼均已開源,感興趣的團隊可以跑起來了。
論文:
https://github.com/RAGEN-AI/RAGEN/blob/main/RAGEN.pdf
代碼
https://github.com/RAGEN-AI/RAGEN
https://github.com/RAGEN-AI/VAGEN
參考鏈接:
[1]https://ragen-ai.github.io
[2]https://x.com/wzihanw/status/1915052871474712858