別扯什么 CQRS,服務做什么讀寫分離,就離譜!
作者:58沈劍
互聯網微服務架構,應該按照“子業務”進行微服務拆分,而不應該按照“讀寫”來進行微服務拆分。
有朋友問我說:服務要不要做讀寫分離?
我的態度旗幟鮮明:不要。
畫外音:別扯什么CQRS。
什么是“服務讀寫分離”架構?
有兩類最常見的。
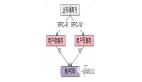
第一類、單純服務讀寫分離

如上圖,服務化之后:
- 同一個基礎服務,分為讀服務與寫服務;
- 底層公用高可用的數據庫集群;
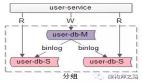
第二類、服務和數據庫同時讀寫分離

讀服務與寫服務讀寫的是不同的數據庫,如上圖:
- 寫服務訪問寫庫;
- 讀服務訪問讀庫;
- 寫庫與讀庫是一個主從同步的集群;
為什么我旗幟鮮明的反對服務區分讀寫分離?
原因1:上游容易困惑,運維更加復雜。
- 調用方對同一個基礎服務,某一個RPC接口,在讀服務,還是寫服務,容易困惑;
- 對于同一個基礎服務,服務數量翻倍了,運維更加復雜;
原因2:微服務不是這么拆分集群的。
- 一般來說,垂直拆分,是按照“子業務”維度進行拆分,而不是按照“讀寫”維度進行拆分,這是模塊化設計的基本準則;
- 完全打破了“服務化數據庫私有”的微服務初衷;
兩個服務因為同一份數據庫資源訪問而耦合在一起,當數據庫資源發生變化的時候(例如:ip變化,域名變化,表結構變化,水平切分變化等),有兩個依賴點需要修改。

而好的設計,有變化產生時,只有一個需要修改(低耦合,高內聚)。
原因3:根本沒法很好的添加緩存。
大部分互聯網業務是讀多寫少的業務,數據庫讀取最容易成為瓶頸,常見提升讀性能的方式是,增加緩存。

服務讀寫分離,怎么添加緩存?
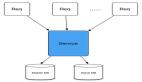
如上圖,讀服務的下游增加一個緩存,當有讀請求訪問時:
- 先訪問緩存,如果命中,直接返回;
- 如果緩存不命中,訪問數據庫,然后將數據放入緩存中,以便下一次能夠命中;
初步看,沒有問題。但是,寫服務修改數據庫時,緩存中的數據沒有辦法得到淘汰!
有朋友說,寫數據庫之前,可以由寫服務來淘汰緩存:

即,讀服務與寫服務都可以操作緩存。
這個設計,又違背了“服務化緩存私有”的微服務初衷,兩個服務因為同一份緩存資源訪問而耦合在一起,當緩存資源發生變化的時候,有兩個依賴點需要修改。
況且,如果真的兩個服務訪問相同的數據庫和緩存,為什么不合成一個服務呢?

硬要拆成兩個服務,不是自己玩自己么?
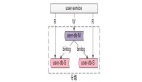
另外,有朋友說,可以由寫服務發消息來淘汰緩存:

如上圖:
- 緩存私有,只有讀服務操縱緩存;
- 數據庫發生寫請求時,寫服務給MQ發消息,由讀服務來淘汰緩存;
這種設計:
- 讀服務來淘汰緩存,本質是一個寫請求,不是很奇怪么?
- 引入了一個MQ組件,引入更大的一致性風險
- 讀服務和寫服務如果是一個進程,豈不是更好么,干嘛硬要跨進程通信呢?
所以,還是一個服務更好:

- 調用方無二義性,不糾結;
- 好維護;
- 數據庫,緩存私有,無耦合;
稍作總結:互聯網微服務架構,應該按照“子業務”進行微服務拆分,而不應該按照“讀寫”來進行微服務拆分。
以上僅為個人架構經驗,供大伙參考,歡迎共同探討。
知其然,知其所以然。
思路比結論更重要。
責任編輯:趙寧寧
來源:
架構師之路