CVPR 2025 Highlight | 清華提出一鍵式視頻擴散模型VideoScene,從視頻到 3D 的橋梁,一步到位!
清華大學的研究團隊首次提出了一種一步式視頻擴散技術 VideoScene,專注于 3D 場景視頻生成。它利用了 3D-aware leap flow distillation 策略,通過跳躍式跨越冗余降噪步驟,極大地加速了推理過程,同時結合動態降噪策略,實現了對 3D 先驗信息的充分利用,從而在保證高質量的同時大幅提升生成效率。實驗證明VideoScene可彌合從視頻到 3D 的差距。


視頻結果



相關鏈接
- 論文: https://arxiv.org/abs/2504.01956
- 項目: https://hanyang-21.github.io/VideoScene
- 代碼: https://github.com/hanyang-21/VideoScene
論文介紹
 VideoScene:提取視頻擴散模型,一步生成 3D 場景
VideoScene:提取視頻擴散模型,一步生成 3D 場景
從稀疏視圖中恢復 3D 場景是一項具有挑戰性的任務,因為它存在固有的不適定問題。傳統方法已經開發出專門的解決方案(例如,幾何正則化或前饋確定性模型)來緩解該問題。然而,由于輸入視圖之間的最小重疊和視覺信息不足,它們仍然會導致性能下降。幸運的是,最近的視頻生成模型有望解決這一挑戰,因為它們能夠生成具有合理 3D 結構的視頻片段。在大型預訓練視頻擴散模型的支持下,一些先驅研究開始探索視頻生成先驗的潛力,并從稀疏視圖創建 3D 場景。盡管取得了令人矚目的改進,但它們受到推理時間慢和缺乏 3D 約束的限制,導致效率低下和重建偽影與現實世界的幾何結構不符。在本文中,我們提出VideoScene來提煉視頻擴散模型以一步生成 3D 場景,旨在構建一個高效的工具來彌合從視頻到 3D 的差距。具體來說,我們設計了一種 3D 感知的跳躍流精煉策略,用于跳過耗時的冗余信息,并訓練了一個動態去噪策略網絡,以便在推理過程中自適應地確定最佳跳躍時間步長。大量實驗表明,我們的 VideoScene 比以往的視頻擴散模型實現了更快、更優異的 3D 場景生成結果,凸顯了其作為未來視頻到 3D 應用高效工具的潛力。
方法概述
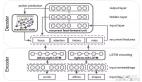
 VideoScene 的流程。 給定輸入對視圖,我們首先使用快速前饋 3DGS 模型(即MVSplat)生成粗略的 3D 表示,從而實現精確的攝像機軌跡控制渲染。編碼后的渲染潛在向量(“輸入”)和編碼后的輸入對潛在向量(“條件”)組合在一起,作為一致性模型的輸入。隨后,執行前向擴散操作,為視頻添加噪聲。然后,將加噪視頻分別發送給學生模型和教師模型,以預測視頻。最后,通過蒸餾損失和 DDP 損失分別更新學生模型和 DDPNet。
VideoScene 的流程。 給定輸入對視圖,我們首先使用快速前饋 3DGS 模型(即MVSplat)生成粗略的 3D 表示,從而實現精確的攝像機軌跡控制渲染。編碼后的渲染潛在向量(“輸入”)和編碼后的輸入對潛在向量(“條件”)組合在一起,作為一致性模型的輸入。隨后,執行前向擴散操作,為視頻添加噪聲。然后,將加噪視頻分別發送給學生模型和教師模型,以預測視頻。最后,通過蒸餾損失和 DDP 損失分別更新學生模型和 DDPNet。
結果展示

定性比較。可以觀察到基線模型存在諸如模糊、跳幀、過度運動以及物體相對位置偏移等問題,而 VideoScene 實現了更高的輸出質量和更好的 3D 連貫性。
結論
VideoScene是一種新穎的快速視頻生成框架,它通過提煉視頻擴散模型,一步生成 3D 場景。具體而言,利用3D先驗知識約束優化過程,并提出一種 3D 感知跳躍流提煉策略,以跳過耗時的冗余信息。此外設計了一個動態去噪策略網絡,用于在推理過程中自適應地確定最佳跳躍時間步長。大量實驗證明了 VideoScene 在 3D 結構效率和一致性方面的優勢,凸顯了其作為彌合視頻到 3D 差距的高效工具的潛力。