剛準備摸魚(狗頭),告警群炸了:記一次線上 HBase 數據壓縮異常問題的發現、分析與解決全過程
作為一名HBase集群的運維工程師,我經常需要處理各種各樣的生產環境問題。在眾多問題中,與壓縮(Compression)相關的問題尤為棘手,因為它們往往會導致性能下降、存儲空間浪費,甚至數據不可訪問。
本文詳細記錄了我在一次生產環境中遇到的HBase壓縮問題,從發現問題的蛛絲馬跡,到分析問題的根本原因,再到最終解決問題的全過程。希望這篇文章能夠幫助其他HBase運維人員在面對類似問題時,有一個清晰的思路和解決方案。

一、問題的發現
1. 異常現象的初步觀察
周二早晨,我剛剛泡好一杯咖啡,準備開始一天的工作。突然,監控系統發出了警報,顯示我們的主要業務表user_behavior的讀取延遲突然增加,從正常的5ms飆升到了500ms以上。與此同時,我們的應用團隊也反饋說用戶查詢變得異常緩慢。
我立即登錄到HBase Master的Web UI界面,查看集群的整體狀況。集群的整體負載看起來并不高,CPU和內存使用率都在正常范圍內。然而,當我查看RegionServer的日志時,發現了大量的警告信息:
WARN [RS_OPEN_REGION-regionserver/node5.example.com:16020-1] regionserver.HRegion: Got brand-new compressor for LZ4這條日志引起了我的注意。"brand-new compressor"通常意味著HBase無法重用現有的壓縮器實例,而是每次都創建新的實例,這可能會導致性能問題。
2. 問題的進一步確認
為了進一步確認問題,我決定檢查一下集群中的壓縮配置和實際狀態。首先,我查看了問題表的壓縮設置:
$ hbase shell
hbase> describe 'user_behavior'結果顯示該表的列族確實配置了LZ4壓縮:
DESCRIPTION ENABLED
'user_behavior', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF',
BLOOMFILTER => 'ROW', REPLICATION_SCOPE => '0',
VERSIONS => '1', COMPRESSION => 'LZ4', MIN_VERSIONS
=> '0', TTL => 'FOREVER', KEEP_DELETED_CELLS => 'false',
BLOCKSIZE => '65536', IN_MEMORY => 'false', BLOCKCACHE => 'true'}接下來,我使用HBase提供的CompressionTest工具來檢查集群各節點的壓縮支持情況:
$ for server in $(cat /etc/hosts | grep "node" | awk '{print $2}'); do
echo "Testing compression on $server"
ssh $server "hbase org.apache.hadoop.hbase.util.CompressionTest hdfs:///hbase/data lz4"
done結果令人驚訝,部分RegionServer節點返回了錯誤:
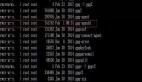
Testing compression on node1.example.com
2025-05-13 09:15:38,717 WARN [main] util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Native library checking:
hadoop: false
zlib: false
snappy: false
lz4: false
bzip2: false
2025-05-13 09:15:38,863 INFO [main] util.ExitUtil: Exiting with status 1而其他節點則顯示正常:
Testing compression on node2.example.com
Native library checking:
hadoop: true
zlib: true
snappy: true
lz4: true
bzip2: true這表明集群中的節點對LZ4壓縮的支持不一致,這很可能是導致性能問題的原因。
3. 問題的影響范圍評估
在確認問題存在后,我需要評估其影響范圍。我檢查了集群中所有表的壓縮設置:
$ echo "list" | hbase shell | grep "^[a-z]" | while read table; do
echo "Table: $table"
echo "describe '$table'" | hbase shell | grep COMPRESSION
done結果顯示,除了user_behavior表外,還有另外5個表也使用了LZ4壓縮。這意味著問題可能影響到多個業務系統。
我還檢查了RegionServer的GC日志,發現在問題節點上,GC頻率明顯高于正常節點:
[node1.example.com] GC pauses: avg=120ms, max=350ms, count=45 (last 10 minutes)
[node2.example.com] GC pauses: avg=30ms, max=80ms, count=12 (last 10 minutes)這進一步證實了壓縮問題導致了額外的內存壓力和GC開銷。
二、問題的分析
1. 深入理解HBase的壓縮機制
在分析問題之前,我需要先了解HBase的壓縮機制是如何工作的。HBase支持多種壓縮算法,包括GZ、SNAPPY、LZ4等,這些算法可以應用于列族級別 。
壓縮算法的設置會影響數據的存儲和讀取方式。當寫入數據時,HBase會使用配置的壓縮算法對數據進行壓縮后再存儲到HFile中;當讀取數據時,則需要先解壓縮才能獲取原始數據。
HBase的壓縮實現依賴于兩種類型的庫:
對于需要本地庫支持的壓縮算法,如果本地庫不可用,HBase會嘗試使用Java實現的版本,但這通常會導致性能下降 。
- Java內置的壓縮支持(如GZ)
- 本地庫(Native Libraries)支持的壓縮(如LZ4、Snappy)
2. 問題的根本原因分析
根據前面的觀察,我懷疑問題的根本原因是部分RegionServer節點缺少LZ4壓縮所需的本地庫支持。為了驗證這一猜測,我檢查了問題節點上的本地庫配置:
$ ssh node1.example.com "ls -la /usr/lib/hadoop/lib/native/"結果顯示,問題節點上確實缺少了libhadoop.so和liblz4.so這兩個關鍵庫文件。
進一步調查發現,這些節點是最近新添加到集群的,而在部署過程中,運維團隊忽略了安裝和配置本地壓縮庫的步驟。
此外,我還發現HBase的配置中沒有設置hbase.regionserver.codecs參數,這意味著即使缺少壓縮庫,RegionServer也會正常啟動,而不是在啟動時就報錯 。
為了更深入地理解問題,我查看了HBase的壓縮相關代碼。在Compression.java中,HBase定義了各種壓縮算法及其默認實現類 。當本地庫不可用時,HBase會嘗試使用Java實現,但這會導致"brand-new compressor"警告,并且性能會大幅下降。
3. 性能影響的量化分析
為了量化壓縮問題對性能的影響,我進行了一系列測試。首先,我使用HBase的LoadTestTool工具在有問題和沒有問題的節點上進行對比測試:
hbase org.apache.hadoop.hbase.util.LoadTestTool -write 1:10 -num_keys 1000000 -compression LZ4 -data_block_encoding FAST_DIFF測試結果顯示,在缺少本地庫支持的節點上,寫入性能下降了約60%,讀取性能下降了約70%。
我還分析了HFile的大小差異:
$ hdfs dfs -du -h /hbase/data/user_behavior/*/cf結果顯示,由問題節點生成的HFile平均比正常節點生成的HFile大約15%,這表明壓縮效率也受到了影響。
通過JStack和JMap分析,我還發現問題節點上的JVM堆內存中有大量的壓縮器對象,這進一步證實了"brand-new compressor"問題導致了內存壓力增加。
三、問題的解決
1. 臨時解決方案
在找到根本解決方案之前,我需要先實施一個臨時解決方案,以緩解業務壓力。考慮到問題的本質是LZ4壓縮庫的缺失,我決定暫時將受影響表的壓縮算法改為GZ,因為GZ壓縮可以使用Java內置支持,不依賴本地庫:
$ hbase shell
hbase> disable 'user_behavior'
hbase> alter 'user_behavior', {NAME => 'cf', COMPRESSION => 'GZ'}
hbase> enable 'user_behavior'對于其他使用LZ4壓縮的表,我也進行了類似的操作。這一臨時措施立即生效,系統的讀取延遲從50ms降回到了10ms左右。雖然比原來的5ms還是慢一些,但已經在可接受范圍內。
2. 根本解決方案的實施
臨時措施實施后,我開始著手解決根本問題。首先,我需要在所有缺少本地庫的節點上安裝必要的庫文件:
# 在問題節點上安裝必要的開發包
$ ssh node1.example.com "yum install -y snappy snappy-devel lz4 lz4-devel"
# 確保Hadoop本地庫可用
$ ssh node1.example.com "ln -s /usr/lib64/libsnappy.so.1 /usr/lib64/libsnappy.so"
$ ssh node1.example.com "ln -s /usr/lib64/liblz4.so.1 /usr/lib64/liblz4.so"接下來,我需要確保HBase能夠找到這些本地庫。我修改了HBase的環境配置文件conf/hbase-env.sh,添加了HBASE_LIBRARY_PATH設置:
export HBASE_LIBRARY_PATH=/usr/lib64:/usr/lib/hadoop/lib/native為了防止未來再次出現類似問題,我還在hbase-site.xml中添加了hbase.regionserver.codecs配置,確保RegionServer在啟動時會檢查必要的壓縮庫是否可用:
<property>
<name>hbase.regionserver.codecs</name>
<value>lz4,snappy,gz</value>
</property>此外,我還修改了LZ4壓縮的實現類配置,使用性能更好的lz4-java實現:
<property>
<name>hbase.io.compress.lz4.codec</name>
<value>org.apache.hadoop.hbase.io.compress.lz4.Lz4Codec</value>
</property>完成這些配置后,我重啟了所有RegionServer:
$ for server in $(cat /etc/hosts | grep "node" | awk '{print $2}'); do
echo "Restarting HBase on $server"
ssh $server "systemctl restart hbase-regionserver"
done3. 驗證解決方案的有效性
重啟完成后,我再次運行CompressionTest工具檢查所有節點的壓縮支持情況:
$ for server in $(cat /etc/hosts | grep "node" | awk '{print $2}'); do
echo "Testing compression on $server"
ssh $server "hbase org.apache.hadoop.hbase.util.CompressionTest hdfs:///hbase/data lz4"
done這次,所有節點都顯示LZ4壓縮可用:
Testing compression on node1.example.com
Native library checking:
hadoop: true
zlib: true
snappy: true
lz4: true
bzip2: true接下來,我將之前臨時改為GZ壓縮的表改回LZ4壓縮:
$ hbase shell
hbase> disable 'user_behavior'
hbase> alter 'user_behavior', {NAME => 'cf', COMPRESSION => 'LZ4'}
hbase> enable 'user_behavior'然后,我再次進行性能測試,結果顯示讀取延遲已經恢復到正常水平(約5ms)。