個人開發者訓400億參數大模型:分布式算力,DeepSeek架構,3090單卡部署
打破科技巨頭算力壟斷,個人開發者聯手也能訓練超大規模AI模型?
Nous Research宣布推出Psyche Network,可以將全球算力整合起來訓練強大的人工智能。

Psyche是一個基于Deepseek的V3 MLA架構的去中心化訓練網絡,測試網首次啟動時直接對40B參數LLM進行預訓練,可以在單個H/DGX上訓練,并在3090 GPU上運行。

以往類似規模的模型訓練往往需要耗費大量的資源和時間,并且通常是由大型科技公司或專業研究機構憑借其雄厚的資金和算力優勢來完成的。
Psyche的出現讓個人和小團體也可獲取資源創建獨特大規模模型。

對此,有網友表示,Nous Research有潛力成為新的前沿AI實驗室。

技術突破和網絡架構
DisTrO優化器
在傳統AI訓練中,數據需在中心服務器與分布式GPU之間高頻傳輸,帶寬不足會導致GPU利用率暴跌。
2024年Nous研發的DisTrO分布式訓練優化器,通過梯度壓縮(僅傳輸關鍵參數更新)和異步更新策略,將跨節點通信的數據量降低90%以上,突破了訓練過程中的帶寬限制,使得訓練可以去中心化。

點對點網絡堆棧
Psyche創建了一個自定義的點對點網絡堆棧,用于協調全球分布式GPU運行DisTrO。
這個基于P2P(點對點)協議的專用網絡層,無需依賴中心化服務器協調,全球GPU可直接通過加密通道交換梯度數據。
這一設計徹底擺脫了對傳統云服務商高帶寬網絡的依賴,即使是家用寬帶連接的GPU,也能穩定參與訓練。
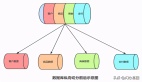
系統架構

Psyche網絡架構有三個主要部分:
coordinator:協調器,存儲有關訓練運行狀態和參與者列表的元數據。處理一輪訓練中每個階段之間的轉換,且負責為運行中的所有客戶端提供同步點。
clients:客戶端,負責訓練、見證和驗證。每個客戶端都保持自身狀態與協調器同步。
data provider:負責提供訓練所需的數據。可以是本地的也可以是HTTP或 CP提供者。
40B參數LLM預訓練
此前互聯網公開的大規模預訓練多由Meta、Google等巨頭主導(如LLaMA 2的700億參數模型),Psyche以去中心化模式實現同等級別訓練。

Psyche首次測試網運行使用的是Deepseek的V3 MLA架構。
MLA通過低秩聯合壓縮鍵值和矩陣分解技術,降低計算復雜度與內存占用,使 400 億參數大語言模型在有限算力下高效訓練。
多頭注意力機制與潛空間表示學習相結合,提升模型語言理解與生成能力;并且,旋轉位置嵌入的運用,有效解決長序列位置依賴問題,從多維度保障了訓練的高效性與模型性能的優質性。
數據集:
使用了FineWeb(14T)、去除部分不常見語言的FineWeb-2(4T)和The Stack v2(1T),些數據集涵蓋豐富信息,為模型訓練提供了有力支持。
分布式訓練策略:
- 模型并行與數據并行結合:將400億參數拆解為128個分片,分布在不同節點進行 “模型并行” 訓練,同時每個節點處理獨立的數據批次(“數據并行”),通過DisTrO優化器同步梯度更新。
- 動態自適應批量大小:根據節點網絡延遲自動調整每個批次的訓練數據量(如高延遲節點使用較小批次,減少等待時間),使全局訓練效率提升25%。
未來將是分布式訓練的天下?
隨著AI模型參數規模呈指數級增長,傳統集中式訓練模式正面臨算力壟斷、成本高昂和擴展性瓶頸的嚴峻挑戰。
分布式訓練的崛起,正在徹底改寫這一格局。
就在幾天前,Prime Intellect發布了首個分布式RL訓練模型INTELLEC-2,引起了廣泛關注。

Nous Research也稱Psyche初始訓練只是起點,后續計劃整合監督微調、強化學習等完整的訓練后階段工作,以及推理和其他可并行工作負載。

誰能站穩分布式訓練擂臺?當然,我們期待更多更優秀的成果~
感興趣的小伙伴可以到官方查看更加詳細的內容。
博客:https://nousresearch.com/nous-psyche/
訓練儀表板:https://psyche.network
代碼:https://github.com/PsycheFoundation/psyche
文檔:https://docs.psyche.network
論壇:https://forum.psyche.networkHugging