大模型分布式并行技術--數據并行優(yōu)化
通信融合
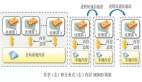
從上文知道數據并行中需要同步每一個模型梯度, 這是通過進程間的 Allreduce 通信實現(xiàn)的。如果一個模型 有非常多的參數,則數據并行訓練的每一個 step 中會有非常多次的 Allreduce 通信,下圖為融合梯度同步示例。
 融合梯度同步示例
融合梯度同步示例
通信的耗時可以從通信延遲(lantency) 和數據傳輸時間消耗兩方面考慮。單次通信延遲時間相對固定, 而 傳輸時間由通信的數據量和帶寬決定。減少總的通信消耗, 可以通過減少通信頻率來實現(xiàn), 通信融合是一個可 行的手段,通過將 N 個梯度的 Allreduce 通信合并成一次 Allreduce 通信,可以減少 N- 1 次通信延遲時間。
常用的 Allreduce 融合實現(xiàn)方式是在通信前將多個梯度 tensors 拼接成一個內存地址連續(xù)的大 tensor,梯度同 步時僅對拼接后的大 tensor 做一次 Allreduce 操作。參數更新時將大 tensor 切分還原回之前的多個小 tensors,完 成每個梯度對應參數的更新。
通信計算重疊
除了降低絕對的通信耗時,還可以從降低整體訓練耗時角度來優(yōu)化,可以考慮通信和計算的異步流水實現(xiàn)。 數據并行中的梯度同步 Allreduce 通信是在訓練的反向過程中進行的, 而 Allreduce 后得到的同步梯度是在訓練 的更新過程中才被使用, 在反向中并沒有被使用。也就是說上一個梯度的通信和下一個梯度的計算間并沒有依 賴,通信和計算可以并行,讓兩者的耗時相互重疊掩蓋,減少反向的耗時,下圖為通信計算并行相互重疊示例。
 通信計算并行相互重疊示例。
通信計算并行相互重疊示例。
通信和計算的重疊通常是將通信和計算算子調度到不同的流 (stream) 上實現(xiàn)的。通信算子調度到通信流, 計 算算子調度到計算流, 同一個流上的算子間是順序執(zhí)行的, 不同流上的算子可以并行執(zhí)行, 從而實現(xiàn)反向中梯 度通信和計算的并行重疊。需要注意的是, 當通信和計算被調度在不同的流上執(zhí)行時, 需要考慮兩個流之間依 賴和同步關系。
- 某個梯度 Allreduce 通信進行前,該梯度的反向計算已經完成。
- 某個梯度對應參數的更新計算開始前,該梯度的 Allreduce 通信已經完成。
在梯度同步的數據并行場景中,開發(fā)者需要需要通過 stream 間的同步功能保證:
以上兩個方法是數據并行中常用的減少通信時間消耗, 提高并行加速比的優(yōu)化策略。如果能做到通信和計 算的重疊程度越高,那么數據并行的加速比越接近 100% ,多卡并行對訓練吞吐提升的效率也就越高。