我所理解的 Go 的 GC (Garbage Collection) 垃圾回收機(jī)制
Go 語言(Golang)作為一款內(nèi)置運(yùn)行時(shí)的現(xiàn)代編程語言,其垃圾回收(Garbage Collection, GC)機(jī)制是開發(fā)者理解其性能和行為的關(guān)鍵一環(huán)。要深入理解 Go 的 GC,我們首先需要明確垃圾回收的核心任務(wù)是什么,以及它在設(shè)計(jì)上需要面對(duì)哪些權(quán)衡與博弈。
在主流的編程語言內(nèi)存模型中,程序運(yùn)行時(shí)使用到的內(nèi)存通常可以劃分為幾個(gè)區(qū)域,其中最主要的是靜態(tài)數(shù)據(jù)區(qū)、棧(stack)和堆(heap)。 棧內(nèi)存 的管理相對(duì)簡單:當(dāng)一個(gè)函數(shù)被調(diào)用時(shí),系統(tǒng)會(huì)為其分配一個(gè)棧幀(stack frame),用于存儲(chǔ)局部變量、參數(shù)以及函數(shù)返回地址等信息;當(dāng)函數(shù)執(zhí)行完畢并返回時(shí),其對(duì)應(yīng)的棧幀會(huì)被自動(dòng)銷毀,所占用的內(nèi)存也隨之釋放。這種后進(jìn)先出(LIFO)的管理方式使得棧上數(shù)據(jù)的生命周期與函數(shù)調(diào)用周期緊密綁定,無需開發(fā)者手動(dòng)干預(yù)。
然而,并非所有數(shù)據(jù)都適合存放在棧上。對(duì)于那些需要在函數(shù)調(diào)用結(jié)束后依然存在,或者大小在編譯期難以確定的數(shù)據(jù),通常會(huì)在 堆內(nèi)存 中分配。對(duì)于像 C/C++ 這類沒有內(nèi)置垃圾回收機(jī)制的語言,開發(fā)者需要顯式地使用如 malloc 這樣的函數(shù)向操作系統(tǒng)申請(qǐng)堆內(nèi)存,并且在不再需要時(shí)通過 free 函數(shù)手動(dòng)釋放。如果忘記釋放,就會(huì)導(dǎo)致 內(nèi)存泄漏 (memory leak),即程序持續(xù)占用不再使用的內(nèi)存,最終可能耗盡系統(tǒng)資源。反之,如果在內(nèi)存釋放后繼續(xù)嘗試訪問它(懸垂指針),則可能導(dǎo)致程序崩潰或未定義行為,即 釋放后使用 (use-after-free)錯(cuò)誤。
在 Go 語言中,開發(fā)者通常不需要像 C/C++ 那樣顯式地“申請(qǐng)”和“釋放”內(nèi)存來管理對(duì)象的生命周期,盡管 Go 提供了如 new 關(guān)鍵字(用于分配零值的內(nèi)存并返回指針)和 make 函數(shù)(用于初始化切片、映射和通道等內(nèi)建類型)來進(jìn)行內(nèi)存分配。當(dāng)這些分配發(fā)生在堆上,或者當(dāng)變量因?yàn)?nbsp;逃逸分析 (escape analysis)——一種編譯器優(yōu)化技術(shù),用于決定變量是分配在棧上還是堆上——而被分配到堆上時(shí),這些對(duì)象的生命周期管理便不再由棧的自動(dòng)機(jī)制控制。
這些脫離了棧作用域控制的堆上對(duì)象,其內(nèi)存何時(shí)以及如何被回收,就成了 GC 的核心職責(zé)。一個(gè)優(yōu)秀的 GC 機(jī)制需要在多個(gè)維度上進(jìn)行優(yōu)化:
- 高效檢測(cè) :如何快速準(zhǔn)確地識(shí)別哪些內(nèi)存是不再被使用的“垃圾”?
- 回收時(shí)機(jī)與頻率 :過于頻繁的垃圾回收會(huì)中斷業(yè)務(wù)邏輯的執(zhí)行,影響程序性能(吞吐量和延遲);而不頻繁的回收則可能導(dǎo)致不再使用的內(nèi)存長時(shí)間累積,造成內(nèi)存膨脹,甚至引發(fā)內(nèi)存溢出(Out Of Memory, OOM)。
- 內(nèi)存碎片 (memory fragmentation):反復(fù)分配和釋放不同大小的內(nèi)存塊可能導(dǎo)致堆中出現(xiàn)許多不連續(xù)的小塊空閑內(nèi)存,這些碎片雖然總量可能不少,但難以滿足較大的內(nèi)存分配請(qǐng)求。如何減少內(nèi)存碎片,提高內(nèi)存利用率,也是 GC 需要考量的。
本文將圍繞 Go 語言的 GC 設(shè)計(jì)展開討論,力求在過程中逐步厘清上述問題,并理解 Go 如何在這些挑戰(zhàn)中取得平衡。
Go GC 總體設(shè)計(jì)
通用的垃圾回收原理主要可以歸納為兩大類:
第一類是基于 引用計(jì)數(shù) (reference counting)的機(jī)制。這種方法為每個(gè)對(duì)象維護(hù)一個(gè)計(jì)數(shù)器,記錄有多少個(gè)引用指向該對(duì)象。當(dāng)一個(gè)新的引用指向?qū)ο髸r(shí),計(jì)數(shù)器加一;當(dāng)一個(gè)引用被移除時(shí),計(jì)數(shù)器減一。一旦對(duì)象的引用計(jì)數(shù)變?yōu)榱悖捅砻髟搶?duì)象不再被任何部分使用,可以立即被回收。Python 語言的 GC 機(jī)制中就包含了引用計(jì)數(shù),C++ 的智能指針 std::shared_ptr 也是基于這一原理。引用計(jì)數(shù)的主要優(yōu)點(diǎn)是對(duì)象可以在不再被引用的那一刻立即被回收,內(nèi)存管理及時(shí)。然而,它也存在一些顯著的缺點(diǎn):一是頻繁更新引用計(jì)數(shù)會(huì)帶來額外的運(yùn)行時(shí)開銷;二是它難以處理 循環(huán)引用 (circular references)的問題,即一組對(duì)象互相引用,即使它們整體已經(jīng)與程序的其他部分隔離(即成為垃圾),但它們的引用計(jì)數(shù)都大于零,導(dǎo)致無法被回收。為了解決循環(huán)引用,通常需要引入額外的檢測(cè)機(jī)制,如 C++ 中的 std::weak_ptr(弱指針)。
第二類是基于 可達(dá)性分析 (reachability analysis)的追蹤式垃圾回收(tracing garbage collection)。這類 GC 的核心思想是“可達(dá)性即存活性”:程序從一組固定的 根對(duì)象 (roots)——通常包括全局變量、當(dāng)前活躍的函數(shù)調(diào)用棧上的局部變量和參數(shù),以及 CPU 寄存器中的指針等——開始,沿著指針引用關(guān)系遍歷內(nèi)存中的對(duì)象圖。所有從根對(duì)象出發(fā)能夠訪問到的對(duì)象都被認(rèn)為是“活”對(duì)象,其余未被訪問到的對(duì)象則被視為“垃圾”,可以被回收。Go 語言的 GC 正是采用了基于可達(dá)性分析的并發(fā)標(biāo)記清掃(concurrent mark-and-sweep)算法。
那么,Go 語言是如何基于可達(dá)性分析的假設(shè),高效且正確地標(biāo)記并清掃不再使用的內(nèi)存呢?這需要我們先了解一些 Go 內(nèi)存管理和 GC 相關(guān)的基礎(chǔ)概念。
在進(jìn)一步探討 Go GC 的具體流程和技術(shù)細(xì)節(jié)之前(假設(shè)讀者對(duì) Go 的 GPM 調(diào)度模型已有基本了解),我們先介紹一些核心的術(shù)語和組件:
- 頁(page) :在 Go 的內(nèi)存管理中,操作系統(tǒng)級(jí)別的內(nèi)存頁(通常為 4KB 或 8KB)是內(nèi)存分配的最小單位之一。Go 的運(yùn)行時(shí)會(huì)向操作系統(tǒng)申請(qǐng)大塊內(nèi)存,然后將這些大塊內(nèi)存劃分為更小的、固定大小的頁進(jìn)行內(nèi)部管理。Go 自身的內(nèi)存管理系統(tǒng)通常使用 8KB 大小的頁。
- span (mspan) :
mspan是 Go 內(nèi)存管理的核心數(shù)據(jù)結(jié)構(gòu),代表了一段連續(xù)的頁。一個(gè)mspan可以用來存儲(chǔ)特定 大小類 (size class)的多個(gè)小對(duì)象,或者一個(gè)單獨(dú)的大對(duì)象。mspan內(nèi)部維護(hù)了關(guān)于其所含對(duì)象的重要元數(shù)據(jù),例如對(duì)象的分配狀態(tài)、存活狀態(tài)(用于 GC 標(biāo)記)等。 - 大小類(size class) :為了高效管理不同大小的對(duì)象分配并減少內(nèi)部碎片,Go 將小對(duì)象(通常指小于 32KB 的對(duì)象)歸入不同的固定大小等級(jí),即大小類。每個(gè)
mspan通常服務(wù)于一種特定的大小類,這意味著它內(nèi)部所有可分配的槽位(slot)都是同樣大小的。 - mcache :
mcache是一個(gè)與每個(gè) P(Processor,對(duì)應(yīng)于 GPM 模型中的 P,代表一個(gè)邏輯處理器,用于執(zhí)行 goroutine)相關(guān)聯(lián)的本地內(nèi)存緩存。它為當(dāng)前 P 上運(yùn)行的 goroutine 提供快速的小對(duì)象分配服務(wù)。mcache中包含各種大小類的mspan列表,由于是 P 本地緩存,從mcache分配內(nèi)存通常不需要加鎖,極大地提高了并發(fā)分配的效率。 - mcentral :
mcentral是一個(gè)全局的、按大小類組織的數(shù)據(jù)結(jié)構(gòu)。每個(gè)大小類都有一個(gè)對(duì)應(yīng)的mcentral實(shí)例。當(dāng)某個(gè) P 的mcache中缺少特定大小類的mspan時(shí),它會(huì)向相應(yīng)的mcentral請(qǐng)求。反之,如果mcache中有多余的空閑mspan,也會(huì)歸還給mcentral。mcentral起到了在不同 P 之間平衡mspan資源的作用,它也需要處理鎖來保證并發(fā)安全。 - mheap :
mheap是 Go 程序的全局堆內(nèi)存管理器。它持有所有從操作系統(tǒng)申請(qǐng)到的內(nèi)存(這些大塊內(nèi)存被稱為 arenas ,例如在 64 位系統(tǒng)上一個(gè) arena 可能是 64MB),并將這些內(nèi)存切分成mspan分配給各個(gè)mcentral。mheap負(fù)責(zé)管理堆的整體大小,決定何時(shí)向操作系統(tǒng)申請(qǐng)更多內(nèi)存或何時(shí)將未使用的內(nèi)存歸還給操作系統(tǒng)。所有的大對(duì)象(大于 32KB)直接由mheap分配。 - 根對(duì)象(root object) :如前所述,根對(duì)象是 GC 開始追蹤對(duì)象可達(dá)性的起點(diǎn)。在 Go 中,這主要包括全局變量區(qū)域中的指針、每個(gè) goroutine 棧(goroutine stack)上指向堆對(duì)象的指針,以及一些運(yùn)行時(shí)內(nèi)部結(jié)構(gòu)的指針。
- 存活堆(live heap) :指在一輪 GC 標(biāo)記階段結(jié)束后,被確認(rèn)為仍然存活(即從根對(duì)象可達(dá))的所有堆對(duì)象的總大小。
- 堆目標(biāo)(heapGoal) :
heapGoal是一個(gè)動(dòng)態(tài)計(jì)算的目標(biāo)堆大小。當(dāng)實(shí)際的堆內(nèi)存占用達(dá)到或超過heapGoal時(shí),就會(huì)觸發(fā)新一輪的 GC。它的計(jì)算通常基于上一輪 GC 結(jié)束后的存活堆大小以及一個(gè)由環(huán)境變量GOGC(默認(rèn)為 100)控制的百分比,公式為heapGoal = liveHeap * (1 + GOGC/100)。
基于上述概念,Go 的一輪并發(fā)標(biāo)記清掃 GC 大致可以分為以下幾個(gè)主要階段:
首先是 標(biāo)記準(zhǔn)備(Mark Setup) 階段。這是一個(gè)短暫的 STW (Stop The World)過程,意味著所有用戶 goroutine 都會(huì)被暫停。在此期間,GC 會(huì)啟用 寫屏障 (write barrier)——一種在并發(fā)標(biāo)記期間確保數(shù)據(jù)一致性的關(guān)鍵機(jī)制,我們稍后會(huì)詳細(xì)討論。同時(shí),還會(huì)進(jìn)行一些必要的初始化工作,為接下來的并發(fā)標(biāo)記做準(zhǔn)備。
接下來是 并發(fā)標(biāo)記(Concurrent Marking) 階段。在這個(gè)階段,用戶 goroutine 恢復(fù)運(yùn)行,與 GC 的標(biāo)記工作并行執(zhí)行。GC 會(huì)從根對(duì)象開始,遞歸地遍歷所有可達(dá)的對(duì)象圖。如果一個(gè)對(duì)象是可達(dá)的,它會(huì)被標(biāo)記。為了提高效率,Go 語言的 goroutine 在進(jìn)行內(nèi)存分配時(shí),也可能會(huì)被要求輔助 GC 執(zhí)行一部分標(biāo)記工作(這被稱為 標(biāo)記輔助 ,mark assist)。寫屏障在這一階段持續(xù)工作,以正確處理用戶 goroutine 在標(biāo)記過程中對(duì)指針的修改。在三色標(biāo)記法中,對(duì)象會(huì)從初始的“白色”(未訪問)變?yōu)椤盎疑保ㄒ寻l(fā)現(xiàn)但其引用的對(duì)象尚未完全掃描),最終變?yōu)椤昂谏保ㄒ褣呙枨移渌幸玫膶?duì)象也已掃描或加入掃描隊(duì)列)。
標(biāo)記工作基本完成后,進(jìn)入 標(biāo)記終止(Mark Termination) 階段。這同樣是一個(gè) STW 階段,所有用戶 goroutine 再次暫停。GC 會(huì)完成所有剩余的標(biāo)記工作,例如處理一些在并發(fā)標(biāo)記期間被寫屏障記錄下來的指針修改,確保所有存活對(duì)象都被正確標(biāo)記。在此之后,所有未被標(biāo)記(即仍為“白色”)的對(duì)象都被認(rèn)為是垃圾。
最后是 并發(fā)清掃(Concurrent Sweeping) 階段。用戶 goroutine 恢復(fù)運(yùn)行。GC 會(huì)在后臺(tái)或者在用戶 goroutine 嘗試分配新內(nèi)存時(shí),逐步回收那些在標(biāo)記階段被識(shí)別為垃圾(白色)的對(duì)象所占用的內(nèi)存空間,將其管理的 mspan 中的對(duì)應(yīng)槽位重新標(biāo)記為空閑,以便后續(xù)分配使用。如果一個(gè) mspan 中的所有對(duì)象都被回收,那么整個(gè) mspan 就可以被歸還給 mheap,用于其他目的,甚至可能被歸還給操作系統(tǒng)。
值得注意的是,Go 的 GC 設(shè)計(jì)目標(biāo)之一是盡可能縮短 STW 的時(shí)間,將大部分工作并發(fā)化,以減少對(duì)應(yīng)用程序延遲的影響。關(guān)于 STW 的具體細(xì)節(jié)和其必要性,我們將在后續(xù)章節(jié)中進(jìn)一步討論。
三色標(biāo)記法
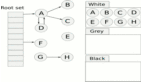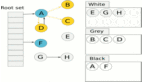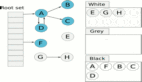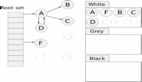
為了在并發(fā)環(huán)境中準(zhǔn)確地識(shí)別存活對(duì)象,Go 的 GC 采用了 三色標(biāo)記法(Tri-color Marking Algorithm)。這個(gè)算法將堆中的對(duì)象邏輯上分為三種顏色:
- 白色(White) :對(duì)象初始狀態(tài),表示尚未被 GC 訪問到。在一輪 GC 結(jié)束時(shí),所有仍然是白色的對(duì)象都被認(rèn)為是垃圾,將被回收。
- 灰色(Gray) :對(duì)象已被 GC 發(fā)現(xiàn)(即從根可達(dá)),但其內(nèi)部的指針(即它所引用的其他對(duì)象)尚未被完全掃描。灰色對(duì)象被視為一個(gè)臨界狀態(tài),它們存在于一個(gè)待處理的工作隊(duì)列中。
- 黑色(Black) :對(duì)象已被 GC 發(fā)現(xiàn),并且其內(nèi)部所有指針都已經(jīng)被掃描完畢(即它引用的對(duì)象要么也變成了灰色或黑色,要么是
nil)。黑色對(duì)象表示 GC 已經(jīng)處理完畢,并且在當(dāng)前 GC 周期內(nèi)是存活的。
垃圾回收進(jìn)行“染色”(標(biāo)記)時(shí),其標(biāo)記信息(例如三色標(biāo)記法中的顏色)是針對(duì) mspan 中具體的對(duì)象或?qū)ο蟛畚唬╯lot)的。 對(duì)于包含小對(duì)象的 mspan,它內(nèi)部有一個(gè)位圖(bitmap)或者類似的數(shù)據(jù)結(jié)構(gòu),用于記錄每個(gè)小對(duì)象的標(biāo)記狀態(tài)。因此,雖然 mspan 是頁的集合,但 GC 標(biāo)記的精度是對(duì)象級(jí)別的,這些標(biāo)記信息存儲(chǔ)在 mspan 的元數(shù)據(jù)中。
GC 的標(biāo)記過程可以想象成一個(gè)從根對(duì)象開始向外“染色”的過程:
- 初始時(shí),所有對(duì)象(除了少量特殊對(duì)象)都被認(rèn)為是白色的。
- GC 從所有根對(duì)象開始,將它們標(biāo)記為灰色,并放入一個(gè)待掃描的灰色對(duì)象集合(工作隊(duì)列)中。
- GC 從灰色對(duì)象集合中取出一個(gè)灰色對(duì)象,掃描它引用的所有其他對(duì)象:
對(duì)于每一個(gè)它引用的白色對(duì)象,將其標(biāo)記為灰色,并放入灰色對(duì)象集合中。
當(dāng)這個(gè)灰色對(duì)象的所有引用都被掃描完畢后,該對(duì)象自身被標(biāo)記為黑色。
- 重復(fù)步驟 3,直到灰色對(duì)象集合為空。
- 此時(shí),所有仍然是白色的對(duì)象就是不可達(dá)的垃圾,可以被回收。
那么,為什么需要三種顏色而不是簡單的兩種(例如,白色和黑色)呢?在非并發(fā)的 GC 中,兩種顏色確實(shí)足夠。但在并發(fā) GC 中,應(yīng)用程序的 賦值器 (mutator,即用戶 goroutine)會(huì)與 GC 的 收集器 (collector)同時(shí)運(yùn)行。我們需要灰色這個(gè)中間狀態(tài)配合后問提到的寫屏障來保證正確性。
為了防止這種“丟失對(duì)象”的情況,三色標(biāo)記法引入了灰色狀態(tài),并配合 寫屏障 (write barrier)來共同維護(hù)一個(gè)關(guān)鍵的不變性。這個(gè)不變性通常是: 不允許黑色對(duì)象直接指向白色對(duì)象,除非該白色對(duì)象能夠通過其他灰色對(duì)象間接可達(dá),或者該白色對(duì)象本身即將被標(biāo)記為灰色。 更嚴(yán)格地說,Go 的寫屏障努力確保在并發(fā)標(biāo)記期間,不會(huì)出現(xiàn)一個(gè)黑色對(duì)象直接指向一個(gè)白色對(duì)象,而這個(gè)白色對(duì)象又沒有其他路徑可以被灰色對(duì)象發(fā)現(xiàn)。
如果賦值器試圖創(chuàng)建一個(gè)從黑色對(duì)象指向白色對(duì)象的指針,寫屏障就會(huì)介入。例如,當(dāng)執(zhí)行 objBlack.field = objWhite 這樣的操作時(shí),寫屏障會(huì)確保 objWhite(或與其相關(guān)的對(duì)象)被標(biāo)記為灰色,從而保證它不會(huì)被遺漏。例如,在一個(gè)掃描順序可能導(dǎo)致問題的場(chǎng)景中:GC 線程掃描了對(duì)象 X 并將其標(biāo)記為黑色。隨后,用戶 goroutine 修改了 X 的一個(gè)字段,使其指向了一個(gè)白色對(duì)象 Y。如果沒有寫屏障,Y 可能永遠(yuǎn)不會(huì)被掃描。有了寫屏障,這次寫入操作會(huì)被攔截,寫屏障會(huì)將 Y 標(biāo)記為灰色,放入待處理隊(duì)列,確保其后續(xù)會(huì)被掃描。
Go 的寫屏障主要有兩種形式(或其變種/組合): 插入寫屏障 (insertion write barrier)和 刪除寫屏障 (deletion write barrier),它們共同服務(wù)于維護(hù)上述三色不變性。
刪除寫屏障、插入寫屏障以及混合屏障
寫屏障是 Go 并發(fā) GC 的核心機(jī)制之一,它通過在指針寫入操作前后插入少量額外代碼來實(shí)現(xiàn)。當(dāng)用戶 goroutine(賦值器)修改堆上對(duì)象的指針字段時(shí),這些由編譯器自動(dòng)插入的屏障代碼會(huì)被執(zhí)行,以通知 GC 發(fā)生了可能影響對(duì)象可達(dá)性的變化。
插入寫屏障(Dijkstra-style Insertion Write Barrier)
插入寫屏障的核心思想是:當(dāng)一個(gè)指針從對(duì)象 A 指向?qū)ο?B 時(shí)(A.ptr = B),如果對(duì)象 B 是白色的,那么寫屏障會(huì)強(qiáng)制將對(duì)象 B 標(biāo)記為灰色。這樣做的目的是防止一個(gè)已經(jīng)被掃描過的黑色對(duì)象(比如 A,如果它已經(jīng)是黑色的)指向一個(gè)尚未被發(fā)現(xiàn)的白色對(duì)象 B,從而避免 B 被遺漏。
具體來說,當(dāng)賦值器執(zhí)行 *slot = ptr (其中 slot 是堆上一個(gè)指針的地址,ptr 是新的指針值)時(shí):
- 如果
ptr指向的對(duì)象是白色的,則將其標(biāo)記為灰色并加入 GC 的工作隊(duì)列。 - 然后才實(shí)際執(zhí)行
*slot = ptr的賦值。
這種屏障確保了所有新建立的引用,如果指向的是白色對(duì)象,那么該白色對(duì)象都會(huì)被“保護(hù)”起來(變?yōu)榛疑却?GC 的后續(xù)處理。Go 在早期版本中主要依賴這種類型的屏障。它的優(yōu)點(diǎn)是實(shí)現(xiàn)相對(duì)簡單,能夠保證正確性(不丟失存活對(duì)象)。但它可能導(dǎo)致一些已經(jīng)死亡的對(duì)象(在被標(biāo)記為灰色后,又因?yàn)槠渌玫臄嚅_而變得不可達(dá))仍然被當(dāng)作存活對(duì)象處理,直到下一輪 GC,這被稱為“浮動(dòng)垃圾”(floating garbage)。
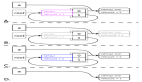
刪除寫屏障(Yuasa-style Deletion Write Barrier)
刪除寫屏障關(guān)注的是被覆蓋的舊指針。當(dāng)一個(gè)指針字段 A.ptr 原本指向?qū)ο?B,現(xiàn)在要改為指向?qū)ο?C(或者 nil)時(shí)(oldVal = A.ptr; A.ptr = C),刪除寫屏障會(huì)在賦值發(fā)生 之前 對(duì) oldVal(即 B)進(jìn)行處理。如果 oldVal 指向的對(duì)象是白色的,并且它可能因?yàn)檫@次引用斷開而失去唯一的灰色或黑色先行者,那么刪除寫屏障會(huì)將 oldVal 指向的對(duì)象標(biāo)記為灰色。
這種屏障主要用于增量式或并發(fā) GC 中,以確保在并發(fā)刪除引用時(shí),不會(huì)意外地使一個(gè)本應(yīng)存活的對(duì)象(因?yàn)槠渌窂饺匀淮嬖冢皇?GC 尚未掃描到)變成不可達(dá)。它在處理并發(fā)場(chǎng)景下對(duì)象圖的動(dòng)態(tài)變化時(shí),能夠提供更強(qiáng)的保障,有助于提高回收的精度。
混合寫屏障(Hybrid Write Barrier)
Go 從 1.8 版本開始引入了一種 混合寫屏障 (hybrid write barrier)。這種屏障結(jié)合了插入寫屏障和刪除寫屏障的特性,其主要目的是 消除在標(biāo)記終止(Mark Termination)STW 階段對(duì)所有 goroutine 棧進(jìn)行重新掃描的需求,從而顯著縮短 STW 的時(shí)間。
混合寫屏障的工作方式大致如下:
- 堆指針寫入 :當(dāng)向堆對(duì)象的指針字段寫入新值時(shí)(
*slot = ptr),屏障會(huì)先將*slot原本指向的對(duì)象(如果它是白色的)標(biāo)記為灰色。這類似于刪除寫屏障的思路,即保護(hù)即將被覆蓋的指針?biāo)赶虻膶?duì)象。然后才執(zhí)行指針的寫入。 - 棧指針寫入:棧上的指針寫入不使用這種復(fù)雜的屏障,因?yàn)闂?huì)在標(biāo)記階段被特殊處理(例如,初始掃描和可能的STW期間的最終處理)。
混合寫屏障的核心保證是:任何在并發(fā)標(biāo)記期間被黑色對(duì)象引用的白色對(duì)象,都會(huì)通過某種方式被 GC 發(fā)現(xiàn)。具體來說:
- 如果一個(gè)黑色對(duì)象在堆上創(chuàng)建了一個(gè)指向白色對(duì)象的指針,那么被該指針槽位 覆蓋 的舊對(duì)象(如果是白色)會(huì)被著色為灰色。新指向的白色對(duì)象
ptr如果沒有其他路徑,其可達(dá)性依賴于其宿主對(duì)象(即包含slot的對(duì)象)的狀態(tài)。如果宿主是黑色,且ptr是白色,這個(gè)場(chǎng)景正是寫屏障要處理的。混合寫屏障通過“保護(hù)舊值”的方式,間接保證了當(dāng)宿主對(duì)象被掃描時(shí),即使新值ptr是白色,也不會(huì)立即丟失。 - 棧上的指針變化由棧掃描覆蓋(主要是在 GC 開始時(shí)的 標(biāo)記準(zhǔn)備 STW 階段 ,會(huì)對(duì)所有 goroutine 的棧進(jìn)行掃描,這是識(shí)別從棧出發(fā)的根引用的必要步驟);在 標(biāo)記終止 STW 階段 ,不再需要對(duì)所有 goroutine 的棧進(jìn)行第二次完整的、地毯式的掃描。
這其中,最核心的原因是 混合寫屏障加強(qiáng)了對(duì)從棧流向堆的指針的追蹤能力 。過去,如果一個(gè)指針只存在于棧上,并且在并發(fā)標(biāo)記期間棧發(fā)生了復(fù)雜的變化,GC 可能會(huì)“跟丟”這個(gè)指針。引入混合寫屏障后,如果這個(gè)指針要“逃逸”到堆上并可能導(dǎo)致問題(比如被一個(gè)黑色堆對(duì)象引用),混合寫屏障會(huì)介入。
因此,不再需要通過一個(gè)全局的、重量級(jí)的“所有棧都停下來重新徹底掃描一遍”的操作來“查漏補(bǔ)缺”。系統(tǒng)相信,通過初始的棧掃描,結(jié)合并發(fā)標(biāo)記期間混合寫屏障在堆上的工作,以及運(yùn)行時(shí)對(duì) goroutine 棧的常規(guī)管理,已經(jīng)足以保證所有存活對(duì)象都能被找到。
通過這種設(shè)計(jì),Go 的混合寫屏障確保了在并發(fā)標(biāo)記期間,即使賦值器在堆上創(chuàng)建了從黑色對(duì)象到白色對(duì)象的引用,或者刪除了這樣的引用,三色不變性也能被維護(hù),而無需在標(biāo)記結(jié)束時(shí)進(jìn)行昂貴的完整棧重掃。這使得 Go 的 GC 停頓時(shí)間,特別是標(biāo)記終止階段的 STW,能夠控制在非常低的水平。
STW, Stop the World
現(xiàn)在我們對(duì) Go GC 的流程和寫屏障有了更深入的理解,可以再次審視 STW(Stop The World) 在 GC 周期中的角色、發(fā)生的時(shí)機(jī)以及其必要性。
Go 的 GC 周期中包含兩次主要的 STW 停頓:
標(biāo)記準(zhǔn)備階段(Mark Setup)的 STW
- 何時(shí)發(fā)生 :在 GC 周期開始時(shí)。
- 為何需要 :此階段非常短暫。它的主要任務(wù)是啟用寫屏障,并準(zhǔn)備 GC 所需的各種數(shù)據(jù)結(jié)構(gòu)。暫停所有 P(邏輯處理器)和用戶 goroutine 是為了確保在一個(gè)一致的程序狀態(tài)下安全地開啟寫屏障。如果在此期間用戶 goroutine 仍在運(yùn)行并修改指針,那么寫屏障的啟用過程可能會(huì)出現(xiàn)競(jìng)態(tài)條件,或者遺漏在屏障完全生效前發(fā)生的指針修改。此外,此階段還會(huì)進(jìn)行一些根對(duì)象的初始掃描準(zhǔn)備工作,比如掃描全局變量和準(zhǔn)備掃描 goroutine 棧(現(xiàn)代 Go GC 對(duì)棧的初始處理更輕量)。
- 如果不 STW 會(huì)怎樣 :無法保證寫屏障的一致啟用,可能導(dǎo)致在并發(fā)標(biāo)記初期就丟失對(duì)象。根集合的快照也可能不準(zhǔn)確。
標(biāo)記終止階段(Mark Termination)的 STW
- 何時(shí)發(fā)生 :在并發(fā)標(biāo)記工作基本完成之后,清掃開始之前。
- 為何需要 :此階段用于完成所有并發(fā)標(biāo)記的收尾工作。例如,處理在并發(fā)標(biāo)記期間由寫屏障記錄下來的、需要進(jìn)一步檢查的指針。在引入混合寫屏障之前,這個(gè)階段一個(gè)非常重要的任務(wù)是重新掃描所有 goroutine 的棧,因?yàn)樵诓l(fā)標(biāo)記期間,棧上的指針可能發(fā)生了變化,而這些變化可能沒有被寫屏障完全覆蓋(早期寫屏障主要針對(duì)堆指針)。引入混合寫屏障后,棧重掃的負(fù)擔(dān)大大減輕,甚至在很多情況下被消除了,使得這個(gè) STW 時(shí)間顯著縮短。此 STW 確保了在進(jìn)入清掃階段之前,所有存活對(duì)象都已被正確標(biāo)記為黑色,所有垃圾對(duì)象都保持白色。這也是一個(gè)同步點(diǎn),確保所有 GC 工作線程和輔助標(biāo)記的 goroutine 都已完成其標(biāo)記任務(wù)。
- 如果不 STW 會(huì)怎樣 :如果并發(fā)標(biāo)記結(jié)束后不進(jìn)行最終的同步和檢查,可能會(huì)有少量本應(yīng)存活的對(duì)象因?yàn)椴l(fā)修改而未被標(biāo)記,導(dǎo)致被錯(cuò)誤回收。或者,某些由寫屏障延遲處理的任務(wù)沒有完成,標(biāo)記結(jié)果不完整。
為什么需要兩次 STW,而不是一次長時(shí)間的 STW?
如果 GC 從頭到尾都是 STW,那么應(yīng)用程序的響應(yīng)會(huì)受到極大影響,長時(shí)間的停頓對(duì)于許多在線服務(wù)是不可接受的。Go GC 的設(shè)計(jì)哲學(xué)是將盡可能多的工作并發(fā)化,只在絕對(duì)必要的同步點(diǎn)進(jìn)行短暫的 STW。這兩次 STW 將整個(gè) GC 周期劃分為幾個(gè)階段,使得主要的標(biāo)記工作(最耗時(shí))可以與用戶 goroutine 并行執(zhí)行。
GC Pacer 與 heapGoal
Go 的 GC 觸發(fā)和步調(diào)是由一個(gè)稱為 Pacer 的機(jī)制來控制的。Pacer 的目標(biāo)是根據(jù) GOGC 環(huán)境變量(默認(rèn)為 100)設(shè)定的比率來決定何時(shí)啟動(dòng)下一輪 GC。GOGC=100 意味著當(dāng)堆大小增長到上一次 GC 結(jié)束后存活堆大小的兩倍時(shí),就應(yīng)該觸發(fā)新的 GC。計(jì)算公式為:heapGoal = heap_live * (1 + GOGC/100)其中 heap_live 是上一輪 GC 結(jié)束時(shí)測(cè)得的存活對(duì)象總大小。Pacer 會(huì)監(jiān)控當(dāng)前的堆分配情況,并在接近 heapGoal 時(shí)啟動(dòng) GC,力求平滑地完成回收任務(wù),避免突兀的性能抖動(dòng)。
GC 工作的公平性與標(biāo)記輔助
為了確保 GC 工作能夠及時(shí)完成,尤其是在分配速率非常高的 goroutine 存在的情況下,Go 引入了 標(biāo)記輔助(Mark Assist) 機(jī)制。當(dāng)一個(gè)用戶 goroutine 嘗試在堆上分配新內(nèi)存時(shí),如果此時(shí) GC 的標(biāo)記階段正在進(jìn)行中,并且 GC 的進(jìn)度落后于預(yù)期的步調(diào)(即分配速度超過了 GC 標(biāo)記的速度),那么這個(gè)正在分配內(nèi)存的 goroutine 會(huì)被要求“幫助”GC 完成一部分標(biāo)記工作,然后才能繼續(xù)其自身的內(nèi)存分配。這種機(jī)制確保了所有 goroutine 都為 GC 貢獻(xiàn)力量,防止某些高分配率的 goroutine “餓死”GC 或?qū)е露褍?nèi)存失控增長。這不是嚴(yán)格意義上 P 之間的公平性,而是確保分配者也承擔(dān) GC 責(zé)任,從而間接促進(jìn)整體進(jìn)度。GC 的后臺(tái)標(biāo)記任務(wù)則由專門的 GC worker goroutine(通常占 GOMAXPROCS 的 25%)執(zhí)行,它們之間也存在工作竊取機(jī)制以平衡負(fù)載。
更加細(xì)致的 GC 流程
為了更清晰地理解 Go 的垃圾回收過程,我們將其細(xì)化為一系列明確的階段和狀態(tài)。Go 的運(yùn)行時(shí)內(nèi)部使用如 _GCoff、_GCmark、_GCmarktermination 等狀態(tài)來管理 GC 周期。以下是一輪典型 GC 周期的詳細(xì)流程:
**當(dāng)前狀態(tài): _GCoff (GC 關(guān)閉)**
- 描述: GC 當(dāng)前未激活。應(yīng)用程序 (mutators) 正常運(yùn)行。
- 內(nèi)存分配: 新分配的對(duì)象被標(biāo)記為白色。
- 后臺(tái)清掃: 上一個(gè) GC 周期的清掃工作可能仍在并發(fā)進(jìn)行中 (由 gcBgMarkWorker 或按需觸發(fā))。
一個(gè) mspan 必須先被清掃干凈 (即回收其中上一周期標(biāo)記為白色的對(duì)象),其空閑槽位才能用于新的分配。
一旦一個(gè) mspan 被清掃過,在本輪 GC 的后續(xù)掃描標(biāo)記完成前,它不會(huì)被再次清掃。
- 觸發(fā)條件: 當(dāng)堆分配的總大小達(dá)到根據(jù) GOGC 計(jì)算出的 heapGoal 時(shí),準(zhǔn)備啟動(dòng)新一輪 GC。
▼ ▼ ▼ GC 觸發(fā) ▼ ▼ ▼
**階段 1: 標(biāo)記準(zhǔn)備 (Mark Setup) - STW (Stop The World)**
- 運(yùn)行時(shí)狀態(tài)轉(zhuǎn)換: 從 _GCoff 進(jìn)入 _GCmark 階段。
- 動(dòng)作:
1. STW 開始: 暫停所有用戶 goroutine 和 P。
2. 設(shè)置 gcphase = _GCmark。
3. 啟用寫屏障 (write barrier): 確保并發(fā)標(biāo)記期間對(duì)象指針修改的正確性。
4. 啟用標(biāo)記輔助 (mark assists): 分配內(nèi)存的用戶 goroutine 可能需要協(xié)助 GC 進(jìn)行標(biāo)記。
5. 掃描根對(duì)象:
- 掃描所有全局變量中的指針。
- 掃描所有當(dāng)前活躍 goroutine 的棧上的指針 (現(xiàn)代 Go 通過混合屏障等優(yōu)化,此步驟可能更輕量或分階段)。
- 將從根對(duì)象直接可達(dá)的對(duì)象標(biāo)記為灰色,并放入待處理工作隊(duì)列。
6. STW 結(jié)束: 恢復(fù)所有用戶 goroutine 和 P。
- 后續(xù): GC 工作 goroutine (通常為 GOMAXPROCS 的 25%) 開始并發(fā)標(biāo)記。用戶 goroutine 繼續(xù)執(zhí)行,并在分配時(shí)可能參與標(biāo)記輔助。
**階段 2: 并發(fā)標(biāo)記 (Concurrent Marking)**
- 運(yùn)行時(shí)狀態(tài): gcphase = _GCmark。
- 描述: 這是 GC 工作的主要階段,與用戶 goroutine 并發(fā)執(zhí)行。
- 動(dòng)作:
1. GC 工作 goroutine 和標(biāo)記輔助的 goroutine 從工作隊(duì)列中取出灰色對(duì)象。
2. 掃描灰色對(duì)象的指針字段:
- 對(duì)于其引用的每個(gè)白色對(duì)象,將其標(biāo)記為灰色并加入工作隊(duì)列。
3. 當(dāng)一個(gè)灰色對(duì)象的所有指針字段都被掃描后,將其標(biāo)記為黑色。
4. 寫屏障持續(xù)工作: 攔截用戶 goroutine 對(duì)指針的修改,以維護(hù)三色不變性 (例如,防止黑色對(duì)象指向白色對(duì)象而未將白色對(duì)象置灰)。
5. 持續(xù)處理工作隊(duì)列,直到隊(duì)列為空或滿足特定終止條件。
**階段 3: 標(biāo)記終止 (Mark Termination) - STW (Stop The World)**
- 運(yùn)行時(shí)狀態(tài)轉(zhuǎn)換: 從 _GCmark 進(jìn)入 _GCmarktermination 階段。
- 動(dòng)作:
1. STW 開始: 再次暫停所有用戶 goroutine 和 P。
2. 設(shè)置 gcphase = _GCmarktermination。
3. 完成剩余標(biāo)記工作:
- 處理所有寫屏障記錄的待處理指針。
- 重新檢查某些根集合或特定條件下的對(duì)象,確保沒有遺漏 (混合屏障顯著減少了棧重掃的需求)。
- 確保所有可達(dá)對(duì)象均已標(biāo)記為黑色。此時(shí),所有仍為白色的對(duì)象被確認(rèn)為垃圾。
4. 禁用寫屏障。
5. 禁用標(biāo)記輔助。
6. 準(zhǔn)備清掃階段: 初始化清掃所需的狀態(tài)。
7. STW 結(jié)束: 恢復(fù)所有用戶 goroutine 和 P。
**階段 4: 并發(fā)清掃 (Concurrent Sweeping)**
- 運(yùn)行時(shí)狀態(tài)轉(zhuǎn)換: 從 _GCmarktermination 回到 _GCoff (清掃在 _GCoff 狀態(tài)下進(jìn)行)。
- 描述: 回收在標(biāo)記階段被識(shí)別為垃圾 (白色) 的對(duì)象所占用的內(nèi)存。此階段與用戶 goroutine 并發(fā)執(zhí)行。
- 動(dòng)作:
1. 設(shè)置 gcphase = _GCoff。
2. 清掃器 (sweeper) 開始工作:
- 后臺(tái) GC 工作 goroutine (gcBgMarkWorker) 會(huì)主動(dòng)遍歷所有 mspan,回收其中標(biāo)記為白色的對(duì)象,并將其占用的槽位標(biāo)記為空閑。
- 按需清掃: 當(dāng)用戶 goroutine 嘗試分配內(nèi)存,且所需的 mspan 尚未被清掃時(shí),該 goroutine 可能會(huì)先觸發(fā)對(duì)該 mspan 的清掃。
3. 對(duì)于一個(gè) mspan:
- 一旦被清掃,其內(nèi)部的白色對(duì)象所占用的空間被回收。
- 該 mspan 的空閑槽位可立即用于新的對(duì)象分配 (新分配的對(duì)象為白色)。
- 此 mspan 在下一次 GC 的標(biāo)記階段完成之前,不會(huì)被再次清掃 (即,當(dāng)前分配到其中的新白色對(duì)象不會(huì)被本輪 GC 的清掃器誤回收)。
4. 更新堆的統(tǒng)計(jì)數(shù)據(jù) (如 live heap 大小)。
5. 根據(jù)新的 live heap 大小和 GOGC 設(shè)置,計(jì)算下一次 GC 的 heapGoal。
▼ ▼ ▼ GC 周期結(jié)束,系統(tǒng)返回 _GCoff 狀態(tài),等待下一次觸發(fā) ▼ ▼ ▼關(guān)于 _GCoff 階段新分配對(duì)象的處理
在 _GCoff 階段,GC 的標(biāo)記工作并未激活。當(dāng)用戶 goroutine 在此階段申請(qǐng)內(nèi)存并分配新對(duì)象時(shí),這些新對(duì)象默認(rèn)被標(biāo)記為 白色 。
你可能會(huì)問,如果這些新分配的白色對(duì)象在 _GCoff 期間(此時(shí)上一周期的清掃可能還在進(jìn)行),它們會(huì)不會(huì)被錯(cuò)誤地清掃掉?答案是 不會(huì) 。原因在于:
- 清掃針對(duì)的是上一周期的垃圾 :GC 的清掃階段是針對(duì) 上一輪 標(biāo)記結(jié)束后被識(shí)別為白色(即垃圾)的對(duì)象。例如,第 N 輪 GC 的清掃器只會(huì)回收在第 N 輪標(biāo)記中最終仍為白色的對(duì)象。
mspan先清掃后分配 :一個(gè)mspan(內(nèi)存管理的基本單元)在能夠用于分配新的對(duì)象之前,必須確保它已經(jīng)被上一輪 GC 的清掃器處理完畢。也就是說,如果一個(gè)mspan中含有第 N 輪 GC 判定的垃圾,這些垃圾必須被清理掉,相應(yīng)的槽位變?yōu)榭臻e,然后這個(gè)mspan才能用來分配第 N+1 輪(或_GCoff期間)的新對(duì)象。- 新對(duì)象等待下一輪 GC :在
_GCoff期間分配到已清掃mspan上的新白色對(duì)象,它們是“干凈”的,它們是否存活將由 下一輪(即第 N+1 輪)GC 的標(biāo)記階段來判斷。如果它們?cè)诘?N+1 輪標(biāo)記開始時(shí)仍然存活(即從根可達(dá)),它們會(huì)被標(biāo)記為灰色,然后黑色;如果不可達(dá),則在第 N+1 輪標(biāo)記結(jié)束后它們依然是白色,并將在第 N+1 輪的清掃階段被回收。
總結(jié)來說, “對(duì)于一個(gè) mspan,需要先清掃完(上一周期的垃圾),再用于(為新對(duì)象)分配。下次 GC 掃描標(biāo)記完成前,(這個(gè) mspan 中新分配的對(duì)象)不會(huì)被再次清掃” 。這個(gè)機(jī)制確保了新分配的對(duì)象不會(huì)被當(dāng)前(或剛結(jié)束的)GC 周期的清掃過程錯(cuò)誤回收。
內(nèi)存碎片與對(duì)象復(fù)用
長時(shí)間運(yùn)行的程序,尤其是那些頻繁進(jìn)行內(nèi)存分配和釋放的程序,常常會(huì)面臨 內(nèi)存碎片 (memory fragmentation)的問題。內(nèi)存碎片分為內(nèi)部碎片(因分配單元大于實(shí)際需求導(dǎo)致的空間浪費(fèi))和外部碎片(空閑內(nèi)存被分割成許多不連續(xù)的小塊,導(dǎo)致雖然總空閑內(nèi)存足夠,但無法滿足較大的單次分配請(qǐng)求)。
一些其他語言的 GC,例如 Java 中的 HotSpot 虛擬機(jī),采用了 分代收集 (generational collection)的策略。這基于一個(gè)常見的“弱分代假說”:大多數(shù)對(duì)象在年輕時(shí)(剛分配后不久)就會(huì)死亡,而存活時(shí)間較長的對(duì)象則傾向于繼續(xù)存活更久。因此,Java 將堆分為新生代和老年代。新生代中的對(duì)象回收頻繁且通常采用 復(fù)制算法 (copying algorithm),這種算法在回收的同時(shí)會(huì)將存活對(duì)象復(fù)制到另一塊內(nèi)存區(qū)域,從而自然地整理了內(nèi)存,消除了碎片。但復(fù)制算法的代價(jià)是需要額外的空間(通常是可用空間的一半),并且移動(dòng)對(duì)象也會(huì)帶來開銷。老年代則采用標(biāo)記-清除或標(biāo)記-整理算法。
Go 語言的 GC 并沒有采用分代收集,也沒有使用會(huì)移動(dòng)對(duì)象的整理(compacting)算法。這意味著 Go 的 GC 本身不直接通過移動(dòng)對(duì)象來消除外部碎片。然而,Go 的內(nèi)存分配器通過一系列精巧的設(shè)計(jì)來緩解內(nèi)存碎片問題,并促進(jìn)內(nèi)存的高效復(fù)用:
多級(jí)緩存與大小類(Size Classes & Caching Hierarchy)
- Go 的內(nèi)存分配器為小對(duì)象(通常 < 32KB)預(yù)定義了大約 67 個(gè) 大小類 (size classes)。當(dāng)程序請(qǐng)求分配一個(gè)小對(duì)象時(shí),分配器會(huì)將其向上取整到最接近的大小類進(jìn)行分配。這有助于標(biāo)準(zhǔn)化內(nèi)存塊的大小,減少內(nèi)部碎片。
- 內(nèi)存分配通過一個(gè)分層緩存系統(tǒng)進(jìn)行:
mcache(P 本地緩存) ->mcentral(全局大小類緩存) ->mheap(全局堆)。 mcache為每個(gè) P 提供了各種大小類的mspan列表。當(dāng) goroutine 在其 P 上分配小對(duì)象時(shí),它可以直接從mcache中獲取對(duì)應(yīng)大小類的空閑槽位,這個(gè)過程通常是無鎖的,非常迅速。當(dāng)對(duì)象被釋放時(shí),其占用的槽位也會(huì)返回到mcache中對(duì)應(yīng)的mspan,以便快速復(fù)用。這種設(shè)計(jì)極大地提高了小對(duì)象的分配和回收效率,并鼓勵(lì)了內(nèi)存的本地化復(fù)用。
mspan 的管理與復(fù)用
- 一個(gè)
mspan管理著一連串相同大小類的對(duì)象槽位。當(dāng)一個(gè)mspan中的所有對(duì)象都被 GC 回收后,這個(gè)mspan就變?yōu)榭臻e狀態(tài)。 - 空閑的
mspan會(huì)被mcentral回收,并可以被重新用于服務(wù)于相同大小類的分配請(qǐng)求,或者如果mheap需要,在某些情況下,一個(gè)完全空閑的mspan(由多個(gè)頁組成)的內(nèi)存頁甚至可以被拆分或重新組合用于其他大小類或大對(duì)象的分配,雖然這不如直接復(fù)用高效。
大對(duì)象直接分配
對(duì)于大對(duì)象(> 32KB),它們直接從 mheap 中分配,通常會(huì)獨(dú)占一個(gè)或多個(gè) mspan。當(dāng)這些大對(duì)象被回收后,它們所占用的 mspan 也會(huì)被釋放回 mheap。
向操作系統(tǒng)歸還內(nèi)存(madvise)
- 當(dāng)
mheap中積累了大量連續(xù)的空閑頁(通常是由于大量mspan被完全釋放)時(shí),Go 的運(yùn)行時(shí)會(huì)周期性地掃描并嘗試將這些未使用的物理內(nèi)存歸還給操作系統(tǒng)。這是通過調(diào)用操作系統(tǒng)提供的機(jī)制(如 Linux 上的madvise系統(tǒng)調(diào)用,使用MADV_DONTNEED或MADV_FREE等參數(shù))來實(shí)現(xiàn)的。這并不會(huì)改變進(jìn)程的虛擬地址空間大小,但會(huì)減少其實(shí)際占用的物理內(nèi)存,從而降低整體系統(tǒng)內(nèi)存壓力。雖然這不是內(nèi)存整理,但它能有效減少程序在空閑時(shí)的內(nèi)存足跡。
通過上述機(jī)制,Go 語言在不移動(dòng)對(duì)象(避免了移動(dòng)帶來的復(fù)雜性和開銷)的前提下,力求通過精細(xì)化的內(nèi)存管理、高效的本地緩存和及時(shí)的內(nèi)存歸還,來最大限度地減少內(nèi)存碎片的影響并提高內(nèi)存的復(fù)用率。特別是對(duì)于小對(duì)象的分配和回收,Go 的性能表現(xiàn)非常出色。
內(nèi)存感知型垃圾回收的探索:Green Tea GC
隨著 CPU 核心數(shù)量的增加和內(nèi)存架構(gòu)(如 NUMA,Non-Uniform Memory Access)的日益復(fù)雜,內(nèi)存訪問的延遲和帶寬正成為高性能系統(tǒng)的主要瓶頸。傳統(tǒng)的垃圾回收算法,包括 Go 此前版本的并行標(biāo)記算法,在進(jìn)行對(duì)象圖遍歷時(shí),其內(nèi)存訪問模式往往缺乏良好的 空間局部性 (spatial locality,即連續(xù)訪問物理上相鄰的內(nèi)存)和 時(shí)間局部性 (temporal locality,即短時(shí)間內(nèi)重復(fù)訪問同一內(nèi)存區(qū)域),也未充分考慮內(nèi)存拓?fù)浣Y(jié)構(gòu)。這會(huì)導(dǎo)致大量的 CPU 周期浪費(fèi)在等待內(nèi)存訪問上(即所謂的 memory stalls)。據(jù)統(tǒng)計(jì),在 Go 的傳統(tǒng) GC 掃描循環(huán)中,超過 35% 的 CPU 周期可能僅僅是由于內(nèi)存停頓造成的。
為了應(yīng)對(duì)這一挑戰(zhàn),Go 團(tuán)隊(duì)一直在探索更具內(nèi)存感知能力的垃圾回收算法。在 Go 語言的 Issue #73581 中,一個(gè)名為 Green Tea ?? Garbage Collector 的新設(shè)計(jì)被提出,并計(jì)劃作為 Go 1.25 版本中的一個(gè)可選實(shí)驗(yàn)性功能。
Green Tea GC 的核心思想與優(yōu)勢(shì)
Green Tea GC 的核心理念是: 與其掃描單個(gè)孤立的對(duì)象,不如按更大的、連續(xù)的內(nèi)存塊(spans)進(jìn)行掃描。
解決的問題 : 傳統(tǒng) GC 的對(duì)象圖遍歷可能在內(nèi)存中“跳躍”,導(dǎo)致緩存未命中率高。Green Tea 試圖通過按塊處理來改善內(nèi)存訪問模式。
原理簡介
- GC 的共享工作隊(duì)列不再追蹤單個(gè)待掃描的對(duì)象,而是追蹤內(nèi)存 塊(spans) 。在原型實(shí)現(xiàn)中,這些主要是指包含小對(duì)象(例如,最大 512 字節(jié))的 8KB 大小的
mspan。 - 當(dāng) GC 發(fā)現(xiàn)一個(gè)指向某個(gè)塊內(nèi)對(duì)象的指針時(shí),它會(huì)標(biāo)記該對(duì)象“需要掃描”(例如,在該塊的元數(shù)據(jù)中設(shè)置一個(gè)“灰色位”),并且如果該塊尚未被加入工作隊(duì)列,則將其加入。
- GC 工作線程從隊(duì)列中取出一個(gè)塊。核心假設(shè)是,在該塊等待被處理的過程中,可能會(huì)有更多的位于該塊內(nèi)的對(duì)象被其他并發(fā)掃描的路徑發(fā)現(xiàn)并標(biāo)記為“需要掃描”。
- 當(dāng)工作線程實(shí)際處理這個(gè)塊時(shí),它可以一次性掃描該塊內(nèi)所有被標(biāo)記為“需要掃描”的對(duì)象。由于這些對(duì)象物理上位于同一個(gè)內(nèi)存塊(span)中,連續(xù)處理它們將顯著提高空間局部性,從而提升緩存利用率并減少內(nèi)存訪問延遲。
帶來的優(yōu)勢(shì)
- 改善局部性 :通過集中處理同一內(nèi)存塊中的對(duì)象,大幅提升了內(nèi)存訪問的局部性,減少了緩存不命中和 CPU 等待內(nèi)存的時(shí)間。
- 降低開銷 :與每個(gè)小對(duì)象都入隊(duì)出隊(duì)相比,按塊(span)進(jìn)行調(diào)度和管理,均攤了這部分開銷。
- 更好的并發(fā)擴(kuò)展性 :工作分配基于改進(jìn)的、類似 goroutine 調(diào)度器使用的分布式工作竊取隊(duì)列,追蹤的是塊而非海量的小對(duì)象,這有助于減少全局鎖的競(jìng)爭。
原型實(shí)現(xiàn)細(xì)節(jié)
Green Tea 的原型主要針對(duì) 小對(duì)象 span 。這是因?yàn)樾?duì)象的掃描本身耗時(shí)很短,傳統(tǒng) GC 為每個(gè)小對(duì)象進(jìn)行獨(dú)立調(diào)度和元數(shù)據(jù)訪問的開銷占比更高,因此從按塊掃描中獲益最大。較大的對(duì)象則可能繼續(xù)使用原有的掃描算法。
為了支持這種按塊掃描,每個(gè) span 會(huì)存儲(chǔ)其內(nèi)部對(duì)象的標(biāo)記位(例如,每個(gè)對(duì)象對(duì)應(yīng)一個(gè)灰色位和一個(gè)黑色位)。當(dāng) GC 掃描到一個(gè)指向小對(duì)象的指針時(shí),它會(huì)設(shè)置該對(duì)象在其 span 內(nèi)的灰色位。如果這個(gè) span 尚未在掃描隊(duì)列中,它會(huì)被加入。當(dāng)一個(gè) span 從隊(duì)列中被取出進(jìn)行處理時(shí),GC 會(huì)查找該 span 內(nèi)所有灰色但非黑色的對(duì)象,掃描它們,然后將它們標(biāo)記為黑色。
為了優(yōu)化只有一個(gè)對(duì)象需要掃描的 span(這種情況下新算法的額外開銷可能使其比老算法慢),Green Tea 實(shí)現(xiàn)了一些技巧:比如追蹤最初導(dǎo)致 span 入隊(duì)的那個(gè)對(duì)象作為“代表對(duì)象”,并使用一個(gè)“命中標(biāo)志”來指示該 span 在排隊(duì)期間是否有其他對(duì)象也被標(biāo)記。如果取出 span 時(shí)命中標(biāo)志未設(shè)置,GC 就可以直接掃描代表對(duì)象,避免遍歷整個(gè) span 的元數(shù)據(jù)。
Green Tea GC 的目標(biāo)是使 Go 的垃圾回收器更加“內(nèi)存感知”,雖然它可能不是完全以內(nèi)存為中心重新設(shè)計(jì)的,但它確實(shí)朝著更有效地利用現(xiàn)代計(jì)算機(jī)內(nèi)存層次結(jié)構(gòu)邁出了重要一步。實(shí)驗(yàn)結(jié)果表明,這種新算法在 GC 密集型工作負(fù)載上顯著降低了 GC 的 CPU 成本,并為未來進(jìn)一步的優(yōu)化(如使用 SIMD指令加速掃描)打開了大門。